OpenGrok : un formidable outil d'indexation / recherche / navigation pour code source
16 septembre 2013 —Au cours de cet article, je vais expliquer comment installer OpenGrok, un logiciel permettant de naviguer dans du code source, et d’effectuer des recherches dessus, depuis une interface web.
Mais pourquoi un indexeur de code-source ?
Il m’arrive fréquemment d’avoir besoin de naviguer dans du code source qui n’est pas actuellement ouvert dans mon IDE ; en particulier, je pense aux situations suivantes :
- Je ne suis pas à mon poste, et je n’ai pas accès à un IDE, ou même au code-source :
- Par exemple, je veux montrer une portion de code à un collègue (qui peut travailler sur un autre projet que moi, et ne pas avoir sur son poste le code-source de mon projet),
- Ou je suis en intervention depuis un autre PC que le mien, sans accès au code-source de l’application que je dépanne (autre qu’un
vimdans un terminal), et ai besoin de chercher la cause d’une erreur (et sur des centaines de milliers de lignes,grepest parfois quelque peu insuffisant), - Ou je suis en pleine revue de code sur un diff correspondant à une application autre que celle sur laquelle mon IDE est ouvert, et souhaite voir comment est implémentée une classe que je vois être utilisée,
- Ou encore, je souhaite accéder à une portion de code sur une autre branche de l’application sur laquelle je travaille, mais sans vouloir prendre le temps de checkouter cette branche,
- Voire même, je veux rechercher tous les usages d’une fonction dans le code-source d’un projet que je connais mal – et dont je peux même ne pas avoir pas les sources sur moi.
Dans ces types de situations, j’ai besoin d’un outil qui :
- Comprenne du code-source : il doit être capable de déterminer ce qui est une fonction, ce qui est une variable, une classe, …
- Soit accessible en ligne via un navigateur, puisque je peux ne pas avoir le code de l’application sur le PC que j’utilise à un instant donné,
- Soit extrêmement rapide à répondre !
- Et soit capable d’indexer plusieurs projets, éventuellement sur plusieurs branches Git ou SVN différentes.
J’ai découvert il y a plusieurs années lxr.php.net, qui permet d’effectuer des recherches dans le code source de chacune des branches stables de PHP (et je l’utilise régulièrement lors que je travaille au développement ou debugagge d’extensions PHP !). Il s’agit d’une instance d’un logiciel nommé OpenGrok (les sources sont sur Github), basé sur Lucene, et que j’ai depuis déployé plusieurs fois sur mes machines personnelles ou professionnelles.
Installation d’OpenGrok
OpenGrok requiert quelques composants :
- Une version récente de JAVA (1.6 ou 1.7)
- Un conteneur de servlet (Tomcat, par exemple)
- Exuberant Ctags
Sous Debian “wheezy” 7.1, le tout peut s’installer depuis les repositories officiels :
sudo apt-get install exuberant-ctags tomcat6
Si vous avez la JRE d’Oracle installée (typiquement, parce qu’un autre logiciel la requiert), OpenGrok fonctionnera aussi très bien avec.
En fonction des projets à indexer, il pourra aussi être utile d’installer les clients SVN, git, … qui permettront d’extraire les sources à indexer.
Au besoin, le port d'écoute de Tomcat peut être modifié dans le fichier `/etc/tomcat6/server.xml` -- j'utilise généralement le port `8181` pour mon instance d'OpenGrok, le port `8080` *(par défaut)* étant souvent déjà pris par un autre logiciel. Pour cela, modifiez le bloc suivant :
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
URIEncoding="UTF-8"
redirectPort="8443" />
En fonction du port que vous avez choisi, et après éventuel redémarrage via sudo /etc/init.d/tomcat6 restart, Tomcat doit être accessible en HTTP (URL à adapter, bien sûr) :
http://192.168.0.13:8181/
Il ne reste plus qu’à télécharger OpenGrok et décompresser le fichier obtenu :
cd /opt/
sudo wget http://java.net/projects/opengrok/downloads/download/opengrok-0.11.1.tar.gz
sudo tar xf opengrok-0.11.1.tar.gz
sudo rm opengrok-0.11.1.tar.gz
sudo mv opengrok-0.11.1 opengrok
Ensuite, déployons l’application web :
cd opengrok/bin
sudo ./OpenGrok deploy
Puis, redémarrons le serveur :
sudo /etc/init.d/tomcat6 restart
Et enfin, l’interface web d’OpenGrok devrait désormais être accessible, sous l’URL /source/ :
http://192.168.0.13:8181/source/
Ce qui doit donner quelque chose de ce type :

Puisque nous n’avons lancé aucune indexation (cf la date d’indexation au 1er janvier 1970 en bas de la page), le logiciel n’est pour l’instant pas encore très utile, et n’affiche aucun projet.
Indexer du code-source avec OpenGrok
Une fois OpenGrok installé, il faut indexer le code-source au sein duquel vous souhaitez pouvoir naviguer et effectuer des recherches.
Pour cela, le code des projets que vous souhaitez indexer doit se trouver sous un même répertoire ; et l’indexation sera lancée sur ce répertoire. Notez qu’il n’est pas possible de spécifier une liste de branches à indexer pour un projet ; à la place, à vous de cloner le projet autant de fois que nécessaire, et de positionner chaque extraction sur la branche souhaitée (ça demande un peu plus de travail de mise en place des sources à indexer, mais ça offre aussi plus de souplesse – et OpenGrok se concentre sur son rôle : l’indexation).
A titre d’exemple, récupérons vers $HOME/projects les sources de trois projets, et positionnons-nous sur les branches qui nous intéressent :
mkdir $HOME/projects
# Sources de PHP master
git clone https://git.php.net/repository/php-src.git $HOME/projects/php-src
# Symfony 1.4
git clone https://github.com/symfony/symfony1.git $HOME/projects/symfony-1.4
cd $HOME/projects/symfony-1.4
# symfony 2.3
git clone https://github.com/symfony/symfony.git $HOME/projects/symfony-2.3
cd $HOME/projects/symfony-2.3
git checkout -b 2.3 origin/2.3
Ensuite, créons le répertoire que OpenGrok utilisera pour stocker les données résultant de l’indexation (je souhaite pouvoir lancer l’indexation avec le compte utilisateur user, d’où le chown) :
sudo mkdir /var/opengrok
sudo chown user:user /var/opengrok
Et enfin, lançons l’indexation du contenu de $HOME/projects, à l’aide de la commande suivante :
/opt/opengrok/bin/OpenGrok index $HOME/projects
L’indexation peut durer quelques temps, et consommer pas mal de ressources. Pour indexer les sources récupérées plus haut, sur une VirtualBox dual-core à 2GB de RAM (sur un système physique Core 2 Quad à 2.8 GHz, 8 GB de RAM, et SSD), il a fallu environ 5 minutes et demies – mais sur des projets beaucoup plus gros, j’ai déjà vu l’indexation durer plus d’une heure !
Utiliser l’interface web d’OpenGrok pour naviguer dans les sources indexées
Une fois l’indexation terminée, la liste des projets (les sous-répertoires de celui sur lequel l’indexation a été lancée) remonte sous forme d’une liste, en haut à droite de l’interface d’OpenGrok :
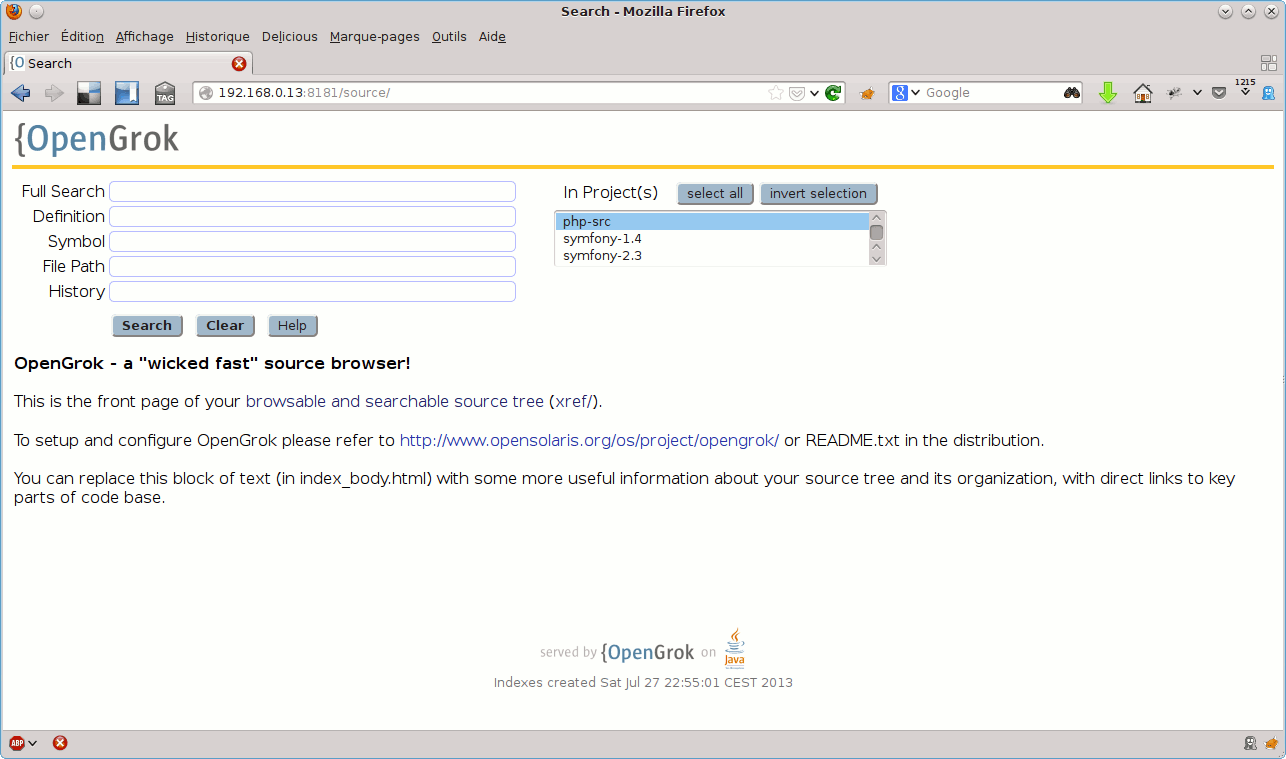
Le lien xhref permet de naviguer dans l’arborescence du code des différents projets :
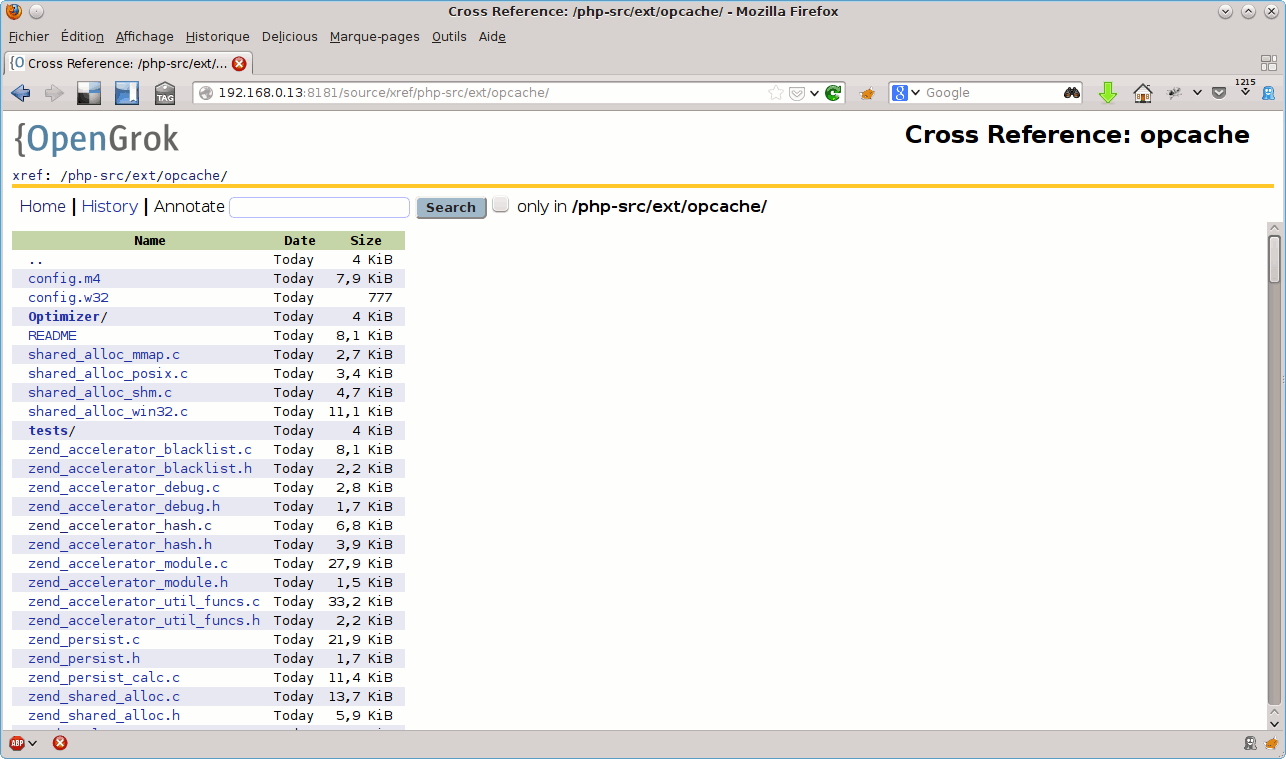
Les champs de formulaire en haut à gauche, quant à eux, permettent d’effectuer des recherches de différents types dans les projets sélectionnés :
Full Search: pour effectuer une recherche textuelle.Definition: pour chercher des définitions de variables, fonctions, …Symbol: pour rechercher des utilisations de variables, fonctions, …File Path: pour spécifier sous quel chemin rechercher.History: pour effectuer une recherche dans l’historique de commits.
Les résultats de recherche sont cliquables, avec de multiples liens :
Hdonne accès à l’historique du fichier,Adonne accès aux annotions : pour chaque ligne est indiquée le commit et son auteur (revient à ungit blameousvn blame),Dpermet d’accéder au fichier brut,- Cliquer sur le nom du fichier permet de le consulter,
- Et enfin, cliquer sur la ligne de code en partie droite permet d’accéder directement à celle-ci.
Une fois que vous êtes sur un fichier, chaque mot-clef, chaque nom de variable, chaque constante, chaque nom de fonction, … tout est cliquable, et permet soit de naviguer vers les définitions (typiquement, pour une fonction ou une variable définie dans le même fichier) ou de lancer des recherches complémentaires.
D’ailleurs : si vous avez cliqué sur un nom de fichier, la recherche sera lancée en utilisant celui-ci comme nom de fichier ; si vous avez cliqué sur nom de fonction, la recherche sera lancée sur la définition de celle-ci ; et ainsi de suite : OpenGrok, lors de sa phase d’indexation, a compris la syntaxe du code-source, et fait donc bien plus qu’un simple grep !
Quelques exemples de recherches et de résultats
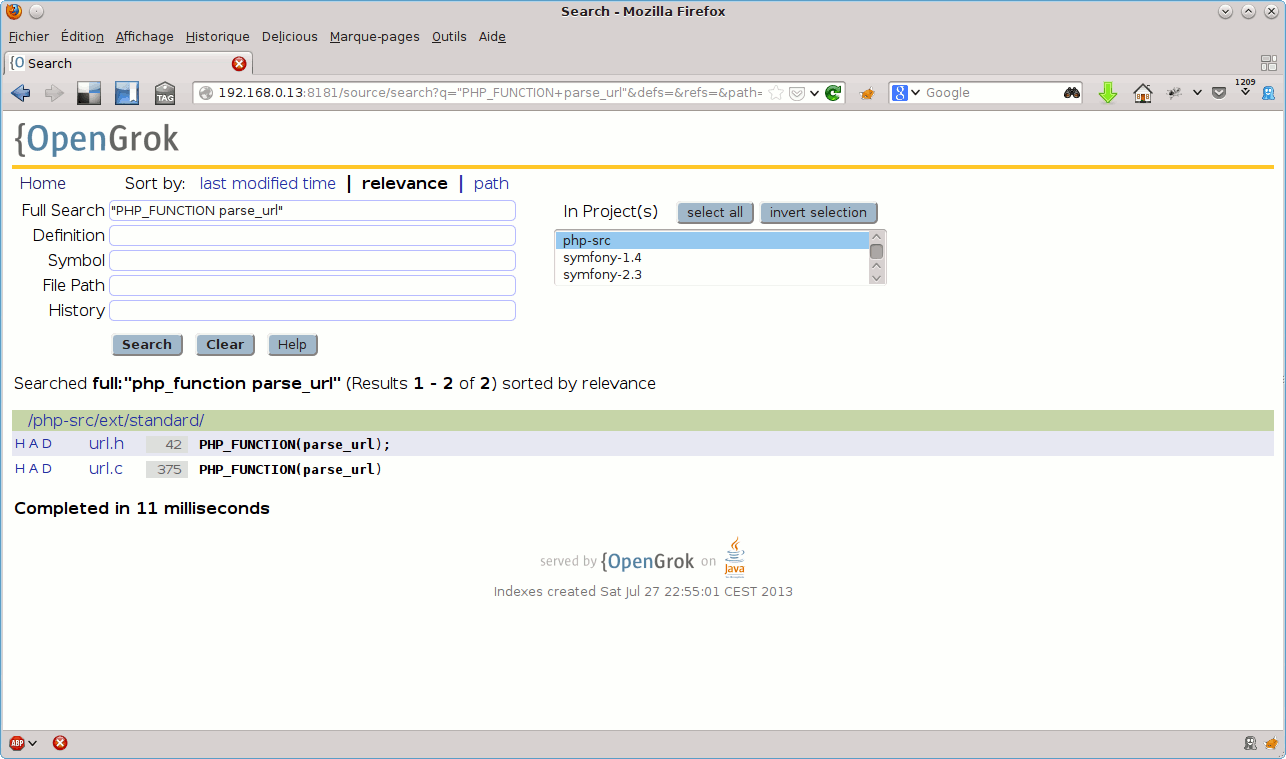
Le premier champ Full Text permet d’effectuer une recherche textuelle dans les projets indexés. Je l’utilise parfois pour rechercher, dans les sources de PHP, des définitions de fonctions (qui, fréquemment, sont construites avec une syntaxe de la forme PHP_FUNCTION(nom_de_fonction)) :
Le champ Definition permet de rechercher des définitions (de variables, fonctions, …) correspondant à un motif. Par exemple, si nous saisissons zend_*_parameters dans ce champ, en sélectionnant les sources de PHP comme projet, nous obtiendrons en retour des liens vers les endroits où les fonctions correspondant à ce motif sont définies :

A l’inverse, le champ Symbol permet de rechercher les usages d’un motif (pour une fonction, ses appels ; pour une variable, ses utilisations). Par exemple, en recherchant strlen dans les sources de symfony 2.3, nous obtiendrons un grand nombre de résultats :
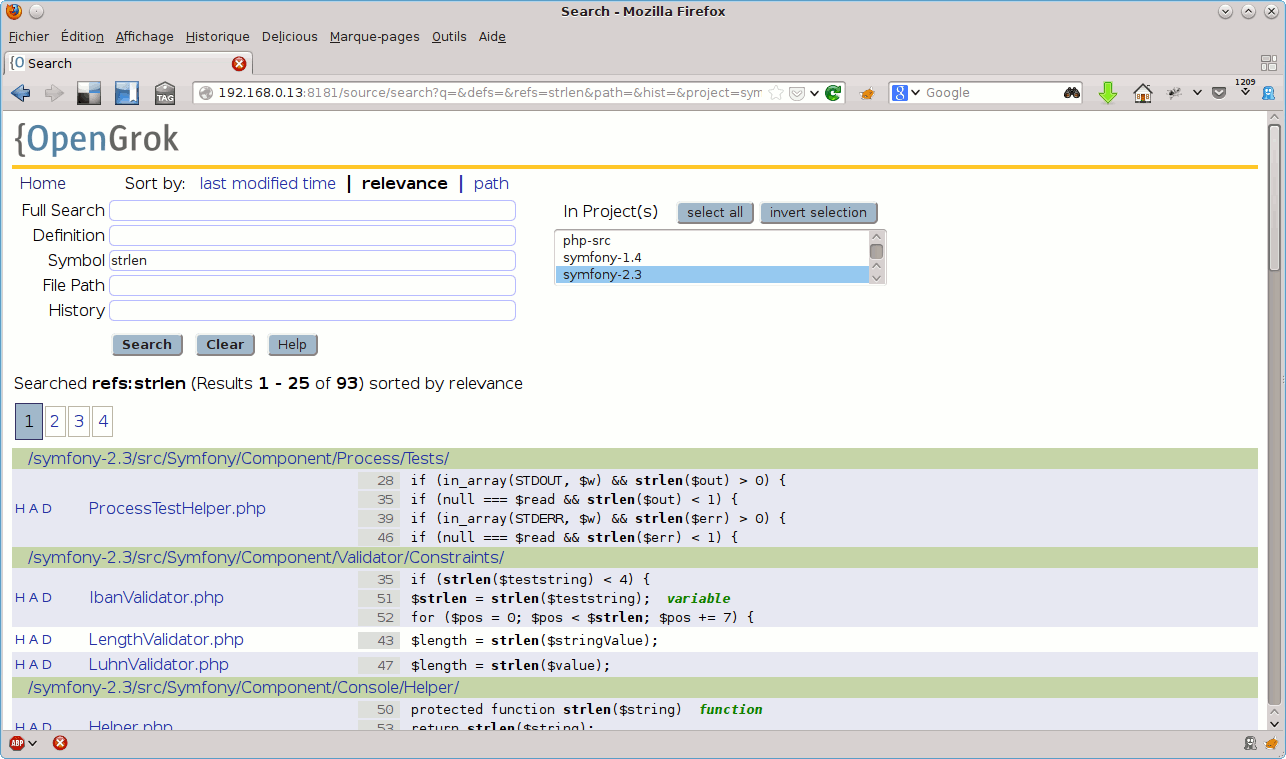
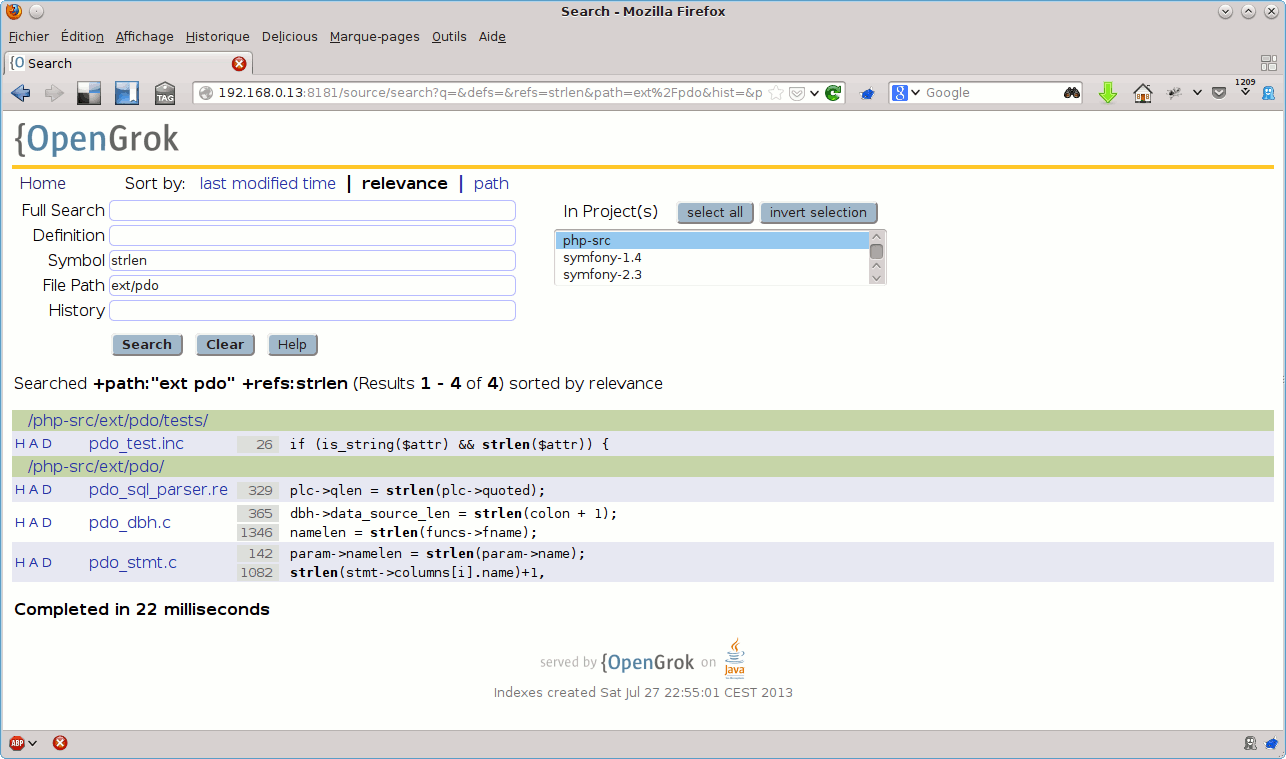
Le champ File Path permet de spécifier dans quels chemins rechercher – je l’utilise principalement pour limiter les résultats d’une recherche à un sous-ensemble des sources du projet au sein duquel j’effectue une recherche spécifiée via les autres champs. Par exemple, pour rechercher les utilisations de la fonction strlen() dans les sources de l’extension PDO de PHP, je pourrais utiliser quelque chose de ce type :
Pour finir, le champ History permet de rechercher dans l’historique de commits d’un projet. Par exemple, recherchons la chaîne “bug #55399” (entourée de double-quotes) en utilisant le champ History, sur les sources de PHP. Le résultat obtenu est alors le suivant :

Ces champs peuvent contenir des wildcards comme * pour plusieurs caractères, et ? pour un seul caractère. Ils peuvent bien entendu être combinés, et utilisés pour rechercher sur un seul ou sur plusieurs projets, sélectionnés en partie droite de l’écran.
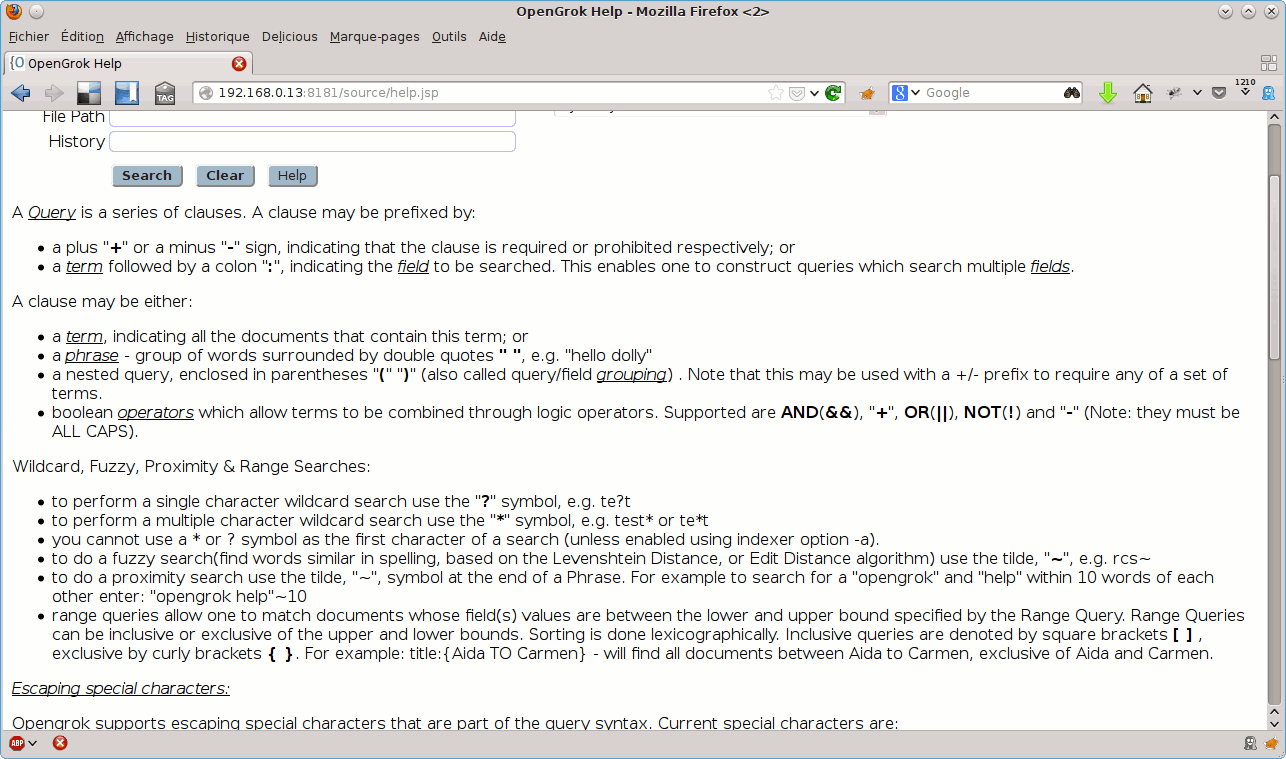
Pour plus d’informations quant à la syntaxe et aux options utilisables dans les requêtes de recherche, consultez l’URL /help.jsp de votre instance d’OpenGrok :
Quelques conseils, notes, et renvois au manuel formel
Pour finir, voici un peu en vrac quelques conseils et quelques notes – certaines fortement tirées de la documentation, et pas toujours mises en pratique sur mes propres instances d’OpenGrok ^^
Quelques conseils
Comme je le disais un peu plus haut, OpenGrok ne gère pas l’indexation de différentes branches d’un projet, ni la mise à jour de projets depuis votre système de contrôle de sources. A la place, il se concentre sur son boulot : l’indexation. Cela signifie que c’est à vous de mettre en place les projets à indexer, à raison d’un répertoire par projet, en-dessous du répertoire parent de l’indexation.
Pour éviter tout risque d’erreur et automatiser cela, j’ai tendance à utiliser un simple shell-script, qui pull tour à tour les différents projets que je souhaite indexer ainsi que leurs différentes branches, et lance ensuite l’indexation en elle-même.
Sur de gros projets, l’indexation peut durer un bon moment en consommant pas mal de ressources ; j’ai donc l’habitude de lancer ce script d’indexation par cron, la nuit ou le week-end (cela dit, si l’indexation de vos projets est rapide, ça peut aussi tourner pendant une pause café ou entre les midis, et sauver un pingouin en évitant de laisser le PC allumé la nuit).
Les extractions des différents projets et des différentes branches, ainsi que les indexes générés par OpenGrok, peuvent finir par prendre pas mal d’espace disque ; prévoyez donc de les placer sur un disque volumineux – si vous avez un HDD et un SSD, il est probablement peu utile de mettre tout ça sur le SSD ;-)
Aussi : j’ai tendance à indexer une extraction propre de projets, et jamais mon espace de travail courant (qui est souvent positionné sur une branche de développement, pas forcément “propre” au moment où l’indexation est susceptible de se lancer).
Et enfin : en fonction des projets, vous voudrez peut-être récupérer des dépendances externes (par exemple, via composer), ou effacer des fichiers sur lesquels vous n’aurez jamais besoin d’effectuer de recherche (par exemple, des fichiers de données ; ou, des fois, les tests unitaires), avant de lancer l’indexation.
Modifier le répertoire de données
Pour stocker les données d’OpenGrok (résultat de l’indexation) ailleurs que dans le répertoire par défaut /var/opengrok, renseignez un autre chemin via la variable d’environnement OPENGROK_INSTANCE_BASE ; par exemple, pour lancer l’indexation :
OPENGROK_INSTANCE_BASE=/mnt/data/opengrok \
/opt/opengrok/bin/OpenGrok index $HOME/projects
Considérant que cela changera l’emplacement du fichier de configuration, vous aurez à créer un lien symbolique entre l’emplacement par défaut, et celui que vous venez de spécifier :
ln -s /mnt/data/opengrok/etc/configuration.xml \
/var/opengrok/etc/configuration.xml
Plus d’informations sont disponibles dans le fichier README.txt.
Personnalisez la page d’index !
Par défaut, la page d’index d’OpenGrok n’est pas particulièrement jolie – le lien vers xhref est fort utile, mais il manque un élément majeur : un lien clairement visible vers la documentation, la syntaxe à utiliser pour effectuer des recherches un peu poussées.
La page utilisée pour l’instance OpenGrok des sources de PHP est simple, mais plutôt sympa : elle fournit des liens directs vers les arborescences des différentes branches (y compris des moteurs autres que l’implémentation de php.net, comme HHVM), et, surtout, des liens vers la syntaxe à utiliser !
Pour savoir comment personnaliser cette page, cherchez index.html dans le fichier README.txt.


