Transcript de ma conférence « Notre environnement de développement n’est plus un bizutage ! » au Forum PHP 2016 Paris
3 novembre 2016 —Le 27 octobre, j’étais présent au Forum PHP 2016 organisé par l’AFUP, pour une présentation intitulée « Notre environnement de développement n’est plus un bizutage ! ». J’ai publié les slides il y a quelques jours et, si vous voulez en savoir plus, voici une tentative de transcript de cette conférence – c’est la première fois que je rédige un post de ce genre, je suis preneur de vos retours ;-)
Vous trouverez en-dessous de chaque slide le texte correspondant, éventuellement enrichi de quelques informations que je n’ai pas données lors de la présentation, puisque celle-ci ne durait que 40 minutes questions incluses.

Bonjour à tous ! Je suis ici aujourd’hui pour vous raconter une histoire, autour de l’environnement de développement avec lequel je travaille au quotidien.
L’installation d’un environnement de développement est parfois, ou souvent, vue comme un réel bizutage par les nouveaux embauchés… Alors que l’expérience gagne à être plus positive que cela !

Il y a trois ans, j’ai changé d’employeur.

Lors de mon arrivée au bureau le premier jour, un de mes collègues m’a dit « Bienvenue ! ». Il a enchaîné par « tu veux un café ? ». Ceux qui me connaissent devineront sans mal ma réponse.
C’était sympa, accueillant…

… Mais, ensuite, il a continué avec ces quelques mots : « tu vas mettre une semaine à installer ton poste ».

Bon, il n’y avait pas eu de nouvel arrivant dans la boîte depuis quelques temps, la plate-forme était peut-être un peu compliquée et il y avait certainement quelques petites choses à améliorer ou qui n’étaient pas encore parfaitement en place.
Je peux comprendre, les collègues avaient eu pas mal de boulot ces derniers temps, après tout.

Quelques heures plus tard, après m’avoir présenté le gros de l’architecture de la plate-forme, un autre collègue – mon chef – en a remis une couche avec cette phrase : « ils ont dû te dire, tu vas en avoir pour deux semaines à installer ta machine ».

Et là, tout de même, je me suis dit « what ??? ».

Parce que même si l’archi était effectivement un peu complexe, je me suis sacrément posé des questions : pendant deux semaines, je n’allais rien faire ? Je n’allais rien déployer en production ? Je n’allais pas être productif ? Et aussi, un peu d’inquiétude : comment allais-je prouver que j’avais ma place dans cette entreprise, si je n’étais pas en mesure de montrer quoi que ce soit après tout ce temps ?

Alors, avant de continuer, un peu de contexte, à la fois pour mettre un cadre autour de l’histoire et, peut-être, pour tenter d’expliquer pourquoi ces deux semaines…

Je bosse dans une société qui s’appelle « TEA, The Ebook Alternative ». On est une start-up dans l’univers du livre numérique, à Lyon, créée il y a un peu plus de 5 ans.

Ajourd’hui, on est une petite vingtaine de personnes, dont 10 dans l’équipe technique. Mais, il y a trois ans, quand j’ai rejoint cette équipe technique qui était de taille plus réduite, je n’étais que le 4ème développeur.
Même si nous sommes autant que possible multi-task, certains d’entre nous sont plus orientés front, d’autres back, certains s’y connaissent plus en admin système que d’autres, … Et selon les personnes et les moments, nous allons du stage en alternance à 10+ ans d’XP.

Plusieurs choses sont aujourd’hui fixées (et certaines l’étaient déjà il y a trois ans) et nous n’envisageons pas, aujourd’hui, de les remettre en cause :
- Nous bossons sous Git avec Github – en faisant des PR pour tout
- Nous avons des PCs sous Linux (distrib au choix) ou des Mac ; des portables, aujourd’hui.
Un point extrêmement important pour moi : quand un truc ne va pas, on l’améliore. Quand un truc va à peu près, on l’améliore. Quand un truc va super bien, on trouve autre chose à améliorer.
Et enfin (et ça peut avoir son importance pour la suite de cette conférence), même si on a des notions d’ops, ce n’est pas vraiment notre métier (et on a vraiment plein d’autres choses à faire – même à 20, on aurait encore du boulot), donc on a choisi de payer un hébergeur pour s’occuper des serveurs : nous ne sommes pas root sur nos machines de production et si nous avons besoin d’installer un service, nous saisissons un ticket.

En parlant de production, nous utilisons plein de services différents, plein de technos différentes, plusieurs langages, différents frameworks ; bref, on ne s’ennuie pas !

Sur tout ça, nous faisons tourner une vingtaine de projets avec une bonne dizaine de technos différentes. Et nos applications peuvent, dans certains cas, être fortement liées, communiquant par APIs (avec, donc, des clefs d’API configurées des deux côtés) ou via des requêtes base-à-base (même si c’est peu élégant, en somme, ça marche).

Bien sûr, ces projets et technos utilisés en production, nous les retrouvons sur nos environnement de développement et ça participe à leur complexité.
En effet, autant que possible, nous souhaitons que nos environnements de développement soient proches de la production, pour être confiant dans le fait que nous ayons pris en compte les contraintes correspondantes ; et que ça marchera quand nous déploierons.
Nous nous permettons toutefois une exception : on ne reproduit pas, en environnement de développement, ce qui est du genre load-balancing, fail-over, réplication de base de données, … Tout ça, c’est du ressort de l’hébergeur et n’a généralement pas trop d’impact sur nos développements applicatifs.

Quand je suis arrivé chez TEA, nous n’avions aucune automatisation pour la mise en place d’un poste de développement. Rappelons qu’au départ, il n’y avait que 2 devs pour tout faire – et pour une startup qui démarre, il faut livrer avant tout.

En regardant ce que mes nouveaux collègues utilisaient, j’ai vu du VirtualBox sur leurs postes. Cool, de la virtualisation, c’est bon signe !
Mais en fait, aucun système de provisionning n’était utilisé. À la place, il fallait passer par une installation à la main d’une ISO (idéalement, la même qu’en prod), puis installer à la main tous les logiciels et services. Et ensuite, toujours à la main, il fallait mettre en place toute la configuration.

Heureusement, il y avait de la doc \o/.
Mais elle était sur un wiki… En fait non, sur deux ! Et les deux n’étaient pas toujours d’accord entre eux ! Et ces documents étaient composés de notes allant un peu dans tous les sens, de commandes à copier-coller et/ou de fichiers à adapter ou d’instructions du genre « remplacer X par la bonne valeur ».
Et bien sûr, ils n’était aussi pas mis à jour aussi régulièrement qu’il n’aurait fallu.

Au final, pour réussir à installer mon poste, je me suis retrouvé à devoir me connecter sur un peu tous les serveurs de prod pour voir quels services tournaient dessus, en quelles versions, et comment ils étaient configurés. Alors que je venais d’être embauché.
Bah… J’aime autant vous dire que ce n’est pas bien drôle ^^

Et malgré tout ça, je ne m’en sortais quand même pas, je n’arrivais pas à installer et configurer l’ensemble des projets !
Finalement, pour que je m’en sorte, il a fallu qu’une de mes collègues prenne son PC (fixe à l’époque ; donc une tour + un écran) et vienne s’installer avec moi à mon bureau… Pendant une semaine !
Donc, pendant deux semaines, je n’ai pas été productif ; et en plus de ça, pendant une semaine, elle non plus ! Ca fait mal !
Et à force d’essayer un truc puis un autre, mon poste tout récemment installé, c’était un gros mélange de tentatives ratées et de fichiers de configuration qui tenaient avec des bouts de scotch !

Quelques mois après, nous avions pour objectif d’accueillir plusieurs nouveaux dans notre équipe. Et donc, il devenait temps de réellement songer à améliorer cette partie !

En termes d’outillage, nous avons gardé VirtualBox, qui marchait bien, que ce soit sous Linux ou sous Mac.
Et on a ajouté Vagrant et Chef pour automatiser.

Vagrant, en faisant très simple, ça permet d’automatiser la création d’une machine virtuelle, de manière à ce qu’elle soit configurée à l’identique chez tout le monde.

Par exemple, ici, nous avons un extrait de fichier Vagrantfile, qui permet de définir un nom de machine, une adresse IP, une quantité de mémoire…
Et vous utilisons un outil nommé chef solo pour le provisionning.

Chef, c’est une grosse usine à gaz qui permet d’installer des logiciels de façon automatisée et reproductible sur plein de serveurs.
Ca fonctionne également sur une seule machine, comme dans le cadre de la VM créée juste avant avec Vagrant.

Voici un exemple de recette Chef, qui installe un serveur Percona (une version de MySQL), crée un fichier de configuration à partir d’un template en l’affectant au bon utilisateur, active MySQL au démarrage de la machine et configure son utilisateur root.
C’est juste un exemple, mais il est proche de l’installation de notre machine virtuelle base de données – et l’exécution de cette recette donne toujours le même résultat : un serveur MySQL installé et configuré à l’identique, de manière automatique, chez tous les développeurs de l’équipe.

Arrivés ici, on a des VM qui sont créées, avec les services installés et configurés. Il ne reste plus qu’à injecter des données dedans pour pouvoir bosser.
Nous avons des backups réalisés régulièrement en production. Nous pouvons donc les télécharger, puis les adapter en supprimant les données confidentielles ou en anonymisant certaines choses. Pour cela, nous avons fait simple : un peu de script bash et quelques requêtes SQL.
Un autre exemple de données : pour le moteur de recherche Solr que nous utilisons sur certaines applications, nous reconstruisons ses indexes depuis les données importées en base juste avant.

Avec tout ça, monter un environnement de développement pour un projet devrait se résumer à quelques étapes : récupérer les sources du projet, créer et provisionner la machine virtuelle, installer les dépendances, et voila !

Mais en fait non : après ces étapes, les tests des applications ne passent pas (et elles ne fonctionnent pas – ce n’est pas un problème du côté des tests).

En effet, il reste un point important à prendre en compte : l’application doit être configurée correctement – et ce n’est pas aussi simple qu’on pourrait le croire. Rappelez-vous : nous avons de nombreuses applications, qui échangent parfois des données par le biais d’APIs, avec une clef secrêtes partagées des deux côtés.
Au départ, nous suivions une logique assez classique dans la communauté PHP : des fichiers .dist commités. Pour installer une application, il fallait trouver tous les fichiers .dist du projet, les copier pour créer les fichiers correspondant sans le .dist, puis trouver toutes les valeurs à renseigner.
C’était juste infernal : les fichiers .dist commités n’étaient pas toujours à jour… Et allez deviner les bonnes valeurs à renseigner pour plusieurs dizaines de fichiers de configuration répartis sur plusieurs applications !
Du coup, on a complètement laissé tomber ce principe et nous avons choisi d’utiliser un petit utilitaire en ligne commande. Quelque chose d’extrêmement pratique et disponible sous Linux et sous Mac : stow.

La meilleure façon de parler de stow, c’est de montrer ce qu’il fait.
Ici, on a un morceau d’arborescence d’un projet, extrait depuis Git. Notez l’existence du répertoire que nous avons nommé config-dist : il contient un répertoire par environnement – et le seul environnement qu’on ait ici est notre environnement de développement, nommé local. Ce répertoire contient tous les fichiers de configuration, avec les bonnes valeurs pour que le projet fonctionne.
On peut se permettre de commiter ces fichiers, puisque chaque développeur de l’équipe a le même environnement et que les mots de passe ou clefs d’API en développement, c’est du genre “toto” et “tutu”.

Une fois le projet extrait depuis Git, on lance la commande stow en lui indiquant le répertoire config-dist où sont placées les configurations et le nom de notre environnement local.

Quand on lance cette commande, stow recrée toute l’arborescence, via des liens symboliques depuis le projet vers l’environnement dans config-dist/local.
Et bonus intéressant : si quelqu’un modifie un fichier de configuration, la modification passe dans la PR de la feature sur laquelle il bossait et tous les collègues en profitent immédiatement.

En production, nos applications se parlent via des noms de machine : « serveur de base de données », « moteur de recherche », …
Sur nos environnement de développement, nous souhaitons reproduire ce principe (et pas passer par des IP, par exemple). Donc, au départ, nous tenions à jour les fichiers /etc/hosts manuellement… Sur les 5 machines virtuelles et sur le poste physique de chacun des développeurs.
À raison de 4 développeurs dans l’équipe à ce moment là, nous avions 24 endroits à adapter à chaque modification. L’enfer !

Pour simplifier, nous avons regardé un peu ce qu’il se faisait dans la communauté et nous avons choisi d’installer un serveur DNS nommé dnsmasq (bien plus facile à configurer que bind) au seul endroit qui soit toujours lancé : la machine physique.
Donc : nous n’avons plus qu’un seul endroit où effectuer les configurations IP ↔ nom de machine. Oui, c’est encore un peu manuel ; mais la manipulation n’est plus à effectuer qu’une seule fois par développeur… Il y a déjà du mieux !

Et donc, enfin, on a atteint notre objectif \o/
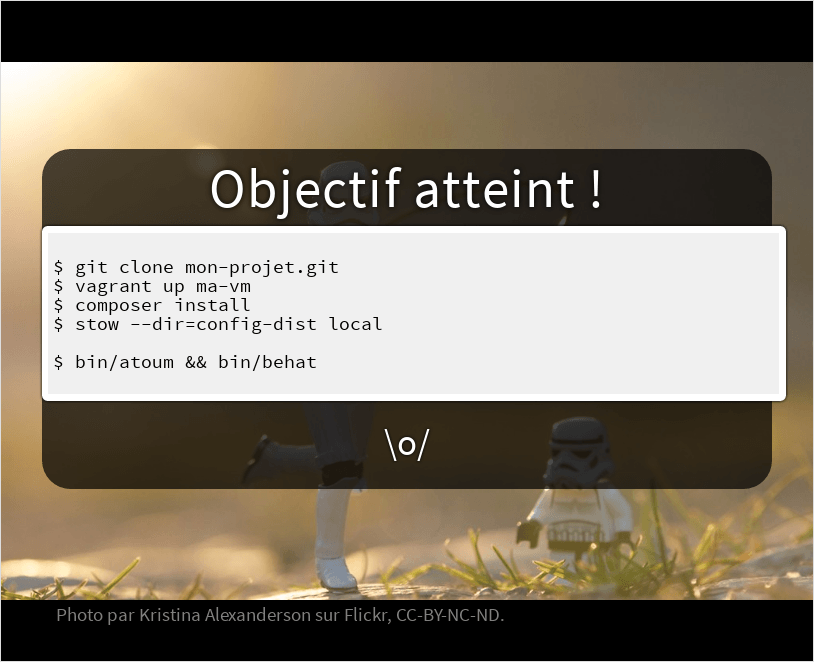
Nous n’avons plus que quelques commandes à exécuter pour récupérer les sources d’un projet, lancer sa machine virtuelle (ça la crée et lance le provisionning), installer les dépendances et déployer la config… Et, succès, les tests passent \o/

Quand j’ai donné cette présentation pour la dernière fois, au PHP Tour Lyon il y a deux ans et demi, on s’était arrêté là…
Mais, depuis, on a continué à améliorer ! Et notamment, on a rapidement commencé à s’intéresser à un outil dont on parlait beaucoup, à l’époque, dans la communauté : docker. Points intéressant : isolation de services et plus virtualisation de machines (donc, moins gourmand en RAM – parce que 5 VM sur 8 GB de RAM, ce n’est pas facile, surtout quand on descend l’ensemble du jeu de données de la production !)

Au risque d’en froisser quelques-uns, pour résumer rapidement, ce dont on a besoin pour notre environnement de travail se base sur trois idées :
- Un fichier nommé
Dockerfilepermet de décrire comment créer une image - La commande
docker buildpermet de créer cette image à partir duDockerfile - Et la commande
docker runpermet d’exécuter un conteneur à partir de cette image.

Nous voulions tester docker, mais sans pour autant basculer vers docker : l’environnement sous vagrant/virtualbox fonctionnait et, même si nous souhaitions tester un second environnement d’exécution, nous voulions initialement conserver les recettes Chef.
Objectif : un seul moyen de construire l’environnement de développement pour toute l’équipe (chef), même si deux environnements d’exécution (virtualbox / docker) étaient utilisés.

Pour cela, nous sommes passé par un Dockerfile qui part d’une image Debian (à l’époque, une wheezy), y ajoute les recettes chef créées précédemment, puis les exécute – à l’aide du même chef solo que celui employé pour le provisionning sous Vagrant.

À l’époque, il n’y avait pas d’outil bien foutu pour gérer le démarrage d’un container à partir d’une image (pas de docker compose ; et fig, son ancêtre, ne faisait pas ce dont on avait besoin). Donc on a fait quelque chose de bien moche (mais qui marchait et qu’on savait mettre en place facilement).

Pour chaque projet, nous avons créé un fichier run.sh, qui contient la commande qui permet d’exécuter le conteneur correspondant – avec le partage de dossier contenant le code source, le pointage vers le serveur dnsmasq en local, …
Les dernières ligne en bas de l’écran, c’est la récupération de l’IP du container pour l’ajouter à la config dnsmasq et relancer dnsmasq. Non, ce n’est clairement pas parfait ; mais ça marche pas trop mal ; et ça répond à notre besoin.

Il reste que constuire une image en exécutant les recettes chef, ça prend du temps, surtout quand on n’a pas la fibre au bureau.
Donc, pour faciliter les choses, une seule personne construit / met à jour une image et la partage aux autres. Ce partage se fait par le biais d’un registre (comme hub.docker.com qui permet d’obtenir des images de la communauté) interne à l’entreprise.

Malgré tout, la maintenance des environnements est compliquée : puisqu’on n’a que rarement besoin de faire évoluer les recettes chef, nous ne sommes pas vraiment montés en compétence sur le truc… Et on galère pas mal !
Quand on a changé d’hébergeur, on a même proposé nos recettes (qui fonctionnaient !) à notre nouvel hébergeur, pour qu’il voit ce dont on avait besoin et peut-être même pour qu’ils s’en servent pour installer nos machines… Ils nous ont fait « oué en fait non, on va faire à notre façon »… Vous en tirerez le message que vous voulez ^^ (bon, ils utilisent un outil nommé puppet et pas chef, ça joue aussi)

Tout à l’heure, je parlais du fichier Dockerfile, qui décrit comment construire une image docker.
Pour tester une migration vers PHP 7.0 et voir si une de nos applications tournait sur cette version, je ne voulais pas passer des heures à me battre avec des recettes chef. Donc j’ai tout refait, pour ce projet, uniquement via un Dockerfile.

En simplifiant un tout petit peu, un Dockerfile, c’est juste une suite de commandes shell. En fait, à peu de choses près, on peut exécuter des commandes apt-get, les tester, et si elles marchent les copier-coller vers un fichier, rajouter RUN devant… Et voila, on a un Dockerfile !
Et une suite de commandes shell, dans l’équipe, tout le monde sait faire. Donc, une fois qu’on a vu à quel point c’était plus facile pour nous, on a décidé petit à petit de virer les recettes chef sur tous les projets, au fur et à mesure qu’on avait besoin de modifier des choses dedans (ça fait bientôt un an, il reste du chef sur deux-trois images qu’on ne reconstruit quasiment jamais, mais elles vont disparaitre dans le futur, je n’en doute pas).

Le registre interne pour partager les images crées ou mises à jour, bien sûr, on l’a conservé : gros gain de temps, qui permet à tout le monde d’avoir une image à jour en 3 minutes (il suffit de pinguer sur Hipchat pour que tout le monde lance un docker pull et récupére l’image re-construite par quelqu’un d’autre).

En plus, Docker est fort pratique pour valider des nouveautés, comme tester des nouvelles versions de PHP ou une nouvelle version de nginx qui permette d’activer HTTP/2.
Typiquement, quand j’ai une demi-heure à un moment, je peux switcher de version de PHP pour un projet (il suffit d’arrêter un container et d’en lancer un autre) et corriger une ou deux éventuelles incompatibilités ;-)

Pendant des années, nous n’avions pas d’intégration continue ; et c’est quelque chose qui nous manquait ! À raison de deux semaines pour installer une machine, malheureusement, ce n’était juste pas possible.
Maintenant, il suffit d’un docker pull pour récupérer une image depuis notre registre interne ; et cette image marche, puisqu’elle est utilisée quotidiennement par les développeurs de l’équipe !
Donc, on a lancé un jenkins, puis on a joué les tests sur master d’un projet toutes les nuits… Et on a vu que des fois, on oubliait de lancer les tests en local et qu’on avait livré la veille des trucs cassés ! Puis on a fait pareil sur tous les projets. Et puis ensuite sur les PR (on fait toujours des PRs pour tous nos développements) d’un projet, et enfin sur les PR de tous les projets, avec intégration des résultats directement dans github \o/
Donc, le travail qu’on a fait sur nos environnements de développement, ça nous a également apporté en qualité et en confiance sur l’ensemble de nos projets !

En fait, il est super important d’expérimenter : c’est comme ça qu’on a mis en place vagrant + chef. Puis qu’on les a viré parce qu’on a trouvé quelque chose qui répondait mieux à nos besoin !
Et puis, expérimenter, c’est aussi tester des logiciels, ou tester des choses (comme plusieurs versions de PHP) sur nos projets et applications ;-)
Par exemple, la prochaine chose qu’on va tester, c’est mettre à jour notre Elasticsearch. Facile, quand il suffit de stopper un container / en lancer un autre : pas besoin de passer des heures en installation ou de casser un environnement pour tester !

Dans tous les cas, l’environnement de développement, la première chose qu’on lance le matin avant même de commencer à coder, c’est comme le code des projets : ça demande du travail pour corriger, améliorer et créer de nouvelles images quand on lance de nouveaux projets.
Et aussi et surtout, il faut savoir faire des compromis : les puristes diront qu’il faut faire ceci et cela, ou que ce que nous avons fait est moche. Et des fois, ça l’est, effectivement ! Mais ça marche et ça nous fait gagner énormément de temps – et c’est ce qui compte : notre métier, ce n’est pas de mettre en place des environnements de développement, mais de mettre des projets en prod !

Finalement, aujourd’hui, monter notre environnement de développement n’est plus un bizutage !
Ou presque ?

Bien sûr, on a encore du boulot et des choses qu’on peut améliorer.

Il y a quelques semaines, un nouveau développeur a rejoint notre équipe. Son 3ème jour chez nous, en début d’après-midi, il a déployé en production pour la première fois. Oui, il lui a fallu moins de 3 jours pour installer son poste, découvrir un projet, commencer à coder, passer la pull-request et déployer !
Par rapport aux deux semaines qu’il m’avait fallu quelques années auparavant, hein ! J’aime autant dire que j’étais fier du travail accompli par toute l’équipe pour faciliter l’intégration des nouveaux arrivants !

Mais pourtant, quand j’en ai parlé avec lui pour préparer cette conférence, il m’a dit quelque chose qui m’a rappelé ce que j’avais moi-même dit lorsque j’étais à sa place : « je ne me suis pas senti productif ».
Et là, on voit le pouvoir du nouveau : percevoir les choses différemment. Là où un ancien voit que les choses se sont (nettement) améliorées, un nouveau qui n’a pas la même histoire en tête verra qu’elles ne sont pas encore parfaites et qu’elles pourrait être améliorées encore !

En fait, il reste encore plein d’opérations manuelles pour installer un poste de développement, malgré tout ce qu’on a automatisé et simplifié : il faut installer l’OS et les logiciels (avec une connexion ADSL, ça prend un moment), il faut cloner tous les repos de tous les projets, déployer leur configuration, installer toutes les dépendances, obtenir les images docker depuis le registre interne, télécharger les dumps depuis la prod (connexion ADSL à nouveau) puis les importer en local, créer/déployer les clefs SSH, configurer compte github, configurer compte google, …
Et bien sûr : il faut également comprendre comment le tout fonctionne !

On dit souvent que passer du temps à dérouler des étapes d’installation est bien pour un développeur, que ça lui permet de découvrir la plate-forme.
Mais, quand même, une plate-forme entière présentée en moins de trois jours ? Aucune chance que le nouvel arrivant retienne tout, au contraire, vous allez l’assomer ! Encore plus si c’est un débutant, qui doit découvrir plein de technos en plus de vos projets !
Et puis, au fur et à mesure que l’équipe grossit, d’autre profils vont la rejoindre. Des dev front ou des intégrateurs HTML, par exemple. Et ils n’ont pas besoin de comprendre les subtilités des composants backend de la plate-forme !
Et aussi, puisque ça peut arriver à tout le monde et que ce n’est jamais drôle : il y a un peu plus d’un an et demi, en arrivant au bureau un matin, la porte était arrachée, tous les PC volés (aucun mac, bizarrement – ça doit pas permettre de bosser ?). Et là, c’est plus de la moitié de l’équipe qui a dû réinstaller son poste. Dur niveau productivité, si ce n’est pas une opération rapide !

Au long de cette conférence, j’ai parlé de pas mal de choses, j’ai raconté un peu ce qu’on avait fait chez TEA ces dernières années.
Aujourd’hui, si je devais vous proposer une façon d’avancer, ça serait probablement celle-ci :
- Commencez par mettre en place une image docker pour un projet ; celui que vous connaissez le mieux, celui qui vous amuse le plus, ou le plus simple.
- Une fois que ça marche, parlez-en autour de vous, pour convaincre vos collègues que le gain de temps est réel.
- Pour faire gagner encore plus de temps, d’ailleurs, un registre interne peut vous aider : c’est une image docker à lancer.
- Bien sûr, documentez : ça peut servir si vous passez sous un bus !
- Et puis, une fois que ça roule sur un projet, passez au suivant. Ou mieux encore, mettez-vous à deux avec un/une collègue, pour diffuser la connaissance dans votre équipe !

Bien sûr, expérimenter ne mène pas toujours à une solution parfaite – et encore moins du 1er coup ! Mais c’est comme ça qu’on avance, par petits incréments.
Gardez tout de même à l’esprit que nous ne sommes pas là pour mettre en place un environnement de dev de façon parfaite ; on est là pour travailler sur nos projets !

Je m’appelle Pascal MARTIN, vous avez mes infos de contact à l’écran. Je bosse chez TEA, à Lyon.
Merci tous pour votre attention :-)

Pour terminer et avant de prendre quelques questions, j’aimerais vous parler d’un projet qui me tient particulièrement à coeur : j’ai participé à l’écriture d’un livre nommée « PHP 7 avancé », publié il y a tout juste deux semaines. Si vous connaissez des étudiants ou avez des collègues qui souhaitent se mettre à PHP, pensez-y, ce livre est fait pour eux ;-)
Merci !


