Optimiser la comparaison de deux listes en PHP
8 décembre 2007 —Vous avez sûrement déjà rencontré une situation de ce genre :
- Vous avez deux listes d'entités,
- et vous voulez savoir combien des entités présentes dans la première liste sont aussi présentes dans la seconde.
Un exemple typique serait la question suivante :
Combien de mots présents dans une liste A sont aussi présents dans une liste B ?
Pour répondre à cette question, en utilisant une implémentation PHP, vous avez plusieurs solutions, plus ou moins naïves - et dépendant de votre niveau de connaissance du langage et de sa bibliothèque de fonctions.
Certaines de ces solutions sont rapides ; d'autres sont extrêmement lentes !
Au cours de cet article, nous étudierons plusieurs solutions, pour en arriver à la conclusion que la solution naïve, la première à laquelle un débutant penserait peut-être, est loin d'être optimale...
Principe
Je présenterai plusieurs solutions permettant de déterminer combien de mots présents dans une liste A sont aussi présents dans une liste B
.
Ensuite, je fournirai les temps d'exécutions obtenus pour chacune de ces solutions, avec un grand nombre d'appels, afin de constater les différences de rapidité entre chaque solution.
Je terminerai par expliquer pour certains types de solutions sont plus rapides que les autres... Et pourquoi certaines implémentations sont à bannir.
Scénarios
Voici le cadre dans lequel les tests menés ci-dessous on été réalisés :
Machine
Tous mes tests ont été réalisés sur la machine suivante :
- Core 2 Duo E6600 2.4 GHz
- 2Go de RAM
- Disque dur SATA-2 10.000 rpm
- PHP 5.2 utilisé en CLI
- Extension Xdebug 2.0.1 utilisée pour le profiling
Jeux de données
Pour ces tests, le jeu de données utilisé est une extraction aléatoire[1] du flux RSS de ce site.
Pour chaque article du flux, j'ai supprimé le maximum de données inutiles (codes sources, par exemple), afin de ne conserver, globalement, que les textes.
Vous trouverez en pièce jointe à cet article une archive contenant les script utilisés, ainsi que les données de tests.
Deux types de tests
Mon premier scénario de test est le suivant : Recherche du nombre de mots présents à la fois dans un article et un second.
Et le second est une généralisation du premier : Recherche dans N articles de tous les mots présents dans chacun des articles.
Plus précisément : recoupement du premier article avec tous les autres, recoupement du second article avec tous les autres, recoupement du troisième article avec tous les autres, ...
Préparation des données
Voici les données utilisées pour mes tests :
Chargement des listes de mots
J'ai sur ma machine une série de fichiers nommées "article-X.txt", correspondant à chacun à un article de ce blog.
Chaque fichier est constitué de la liste des mots, uniques, du billet correspondant, à raison de un mot par ligne.
Ces fichiers peuvent être chargés à l'aide de la fonction suivante :
function getArticles()
{
for ($i=0 ; $i<=12 ; $i++)
{
$articles[$i] = file("data/textes-articles/article-$i.txt",
FILE_IGNORE_NEW_LINES | FILE_SKIP_EMPTY_LINES);
}
return $articles;
}La variable $articles, utilisée par la suite pour tous les tests est obtenue de la manière suivante :
$articles = getArticles();Calcul nombre de mots distincts
Pour information, voici les nombres de mots obtenus, pour chaque article :
$ wc -l textes-articles/* 683 textes-articles/article-0.txt 370 textes-articles/article-10.txt 430 textes-articles/article-11.txt 163 textes-articles/article-12.txt 439 textes-articles/article-1.txt 496 textes-articles/article-2.txt 542 textes-articles/article-3.txt 674 textes-articles/article-4.txt 334 textes-articles/article-5.txt 584 textes-articles/article-6.txt 257 textes-articles/article-7.txt 500 textes-articles/article-8.txt 478 textes-articles/article-9.txt 5950 total
(Puisqu'on a stocké un mot par ligne dans chacun des fichiers)
Présentation des différents modes de recherche :
Passons maintenant aux différents "moteurs de recherche" répondant à notre problématique...
Pour faciliter le développement, et, surtout, les tests de performance, chacun de ces moteur de recherche a été implémenté sous forme d'une fonction indépendante, l'idée étant de pouvoir comparer les temps d'exécution de chacune d'entre elles.
Double-parcours manuel
La première solution que nous allons voir est la plus naïve : celle à laquelle un développeur ne connaissant pas du tout PHP aurait probablement tendance à penser, puisqu'elle ne requiert aucune connaissance spécifique à PHP ; juste quelques notions d'algorithmique.
Cette portion de code répond exactement à la problématique : on parcourt tous les mots de la première liste, et, pour chacun de ces mots, on parcourt tous les mots de la seconde liste, en les comparant avec le mot courant issu de la première :
function compare_arrays_our($liste1, $liste2)
{
$nbr = 0;
foreach ($liste1 as $mot1)
{
foreach ($liste2 as $mot2)
{
if ($mot1 == $mot2)
{
$nbr++;
}
}
}
return $nbr;
}Le gros problème de cette solution : elle est en O(n*m)... Et une double boucle telle que celle-ci, à 100% en PHP... C'est lent !
Le temps d'exécution de cette première solution est de 176 ms pour trouver le nombre de mots présents à la fois dans le premier et dans le second article.
Parcours manuel, et appel à in_array
Voici une seconde version de ce principe, mais on la boucle interne a été remplacée par un appel à la fonction php in_array :
function compare_arrays($liste1, $liste2)
{
$nbr = 0;
foreach ($liste1 as $mot1)
{
if (in_array($mot1, $liste2))
{
$nbr++;
}
}
return $nbr;
}Fondamentalement, en terme d'algo, cette solution est la même que la précédente.
Mais le remplacement d'une boucle 100% PHP par un appel à la fonction interne in_array améliore grandement la rapidité d'exécution : sur notre cas de test, on passe de 176 ms à 34 ms !
Qu'est-ce que cela nous apprend ?
Une boucle codée en PHP est beaucoup plus lente qu'une boucle codée au sein d'une fonction de la bibliothèque (codée en C, et compilée, plutôt qu'interprétée).
Parcours manuel de Hash, et appel à array_key_exists
A présent, plutôt que d'effectuer un parcours entier de la seconde liste, voyons si on ne peut pas optimiser cela...
Tous nos mots sont uniques, au sein de ladite liste ; on peut donc "retourner" celle-ci, pour avoir un tableau associatif dont les clefs sont les mots, et les valeurs... peu importe.
L'avantage ? SI PHP se débrouille bien, déterminer si une clef existe dans un tableau est plus rapide que de déterminer si une valeur existe : au sein d'un tableau non trié, il faut faire un O(n) pour trouver si une valeur existe...
Alors que si le tableau est organisé en mémoire sous forme d'un Arbre Binaire de Recherche, nous pouvons statuer sur l'existence d'un élément en O(log(n)) dans le cas moyen.
Avant de passer aux tests en eux-même, voici une petite fonction utilitaire, transformant une liste de mots en un tableau associatif au sein duquel les mots sont les clefs :
function toHash($liste)
{
$hash = array();
foreach ($liste as $mot) {$hash[$mot] = 1;}
return $hash;
}Et voici une première idée d'implémentation utilisant le principe que je viens de présenter :
function compare_arrays_hash_keys($liste1, $liste2)
{
$hash2 = toHash($liste2);
$nbr = 0;
foreach ($liste1 as $mot1)
{
if (array_key_exists($mot1, $hash2))
{
$nbr++;
}
}
return $nbr;
}Nous passons de 34 ms avec la méthode précédente à 13 ms avec celle-ci.
Bien que nous prenions le temps de "retourner" la liste, nous avons donc divisé le temps d'exécution par pas loin de trois !
Tester l'existence d'une clef d'un tableau, avec
array_key_existsest plus rapide que de tester la présence d'une valeur dans ce même tableau, avecin_array- même s'il faut retourner le tableau pour cela !
Attention : ici, on peut se permettre cette amélioration parce que chaque mot n'est présent qu'une seule fois dans la liste ; on n'a dont jamais deux mots qui veulent la même place en clef du tableau associatif.
Comptage du nombre d'élément dans la liste d'intersections des deux tableaux : array_intersect
Maintenant, par curiosité, voyons ce que nos pourrions faire pour totalement supprimer les parcours de tableaux côté PHP.
Pour rappel, nous voulons compter combien de mots sont présents à la fois dans une liste A et dans une liste B...
En PHP, pour obtenir une liste d'éléments se trouvant simultanément dans deux listes, il convient d'utiliser la fonction array_intersect.
Et, pour compter combien d'éléments sont présents au sein de cette liste d'intersection, on peut utiliser count.
Ce qui nous donne :
function compare_arrays_intersect($liste1, $liste2)
{
$nbr = 0;
$nbr = count(array_intersect($liste1, $liste2));
return $nbr;
}Et, avec cette solution, on descend à 1.089 ms - soit 13 fois plus rapide que la solution précédente !
Ici, le gain vient du fait que nous n'effectuons plus aucune boucle en PHP : les boucles sont réalisées en interne, par des fonctions de la bibliothèque PHP, qui ne sont pas codées en PHP, mais en langage compilé.
Test de l'existence de clefs dans un Hash construit "à la main" : isset
Une autre solution : nous reprenons l'idée utilisée plus haut, à savoir, tenter de travailler sur les clefs d'un tableau associatif, plutôt que sur les valeurs d'une liste, en espérant que PHP gère cela intelligemment.
Par contre, cette fois-ci, plutôt que de faire appel à array_key_exists pour déterminer si un mot est présent dans le tableau associatif (ie, si un mot est présent comme clef de celui-ci), nous allons utiliser la construction de langage isset[2].
L'idée étant qu'appeler une fonction interne au langage sera peut-être plus rapide qu'appeler une fonction de la bibliothèque PHP - de la même manière qu'appeler une fonction de la bibliothèque PHP était plus rapide qu'appeler une fonction définie par l'utilisateur.
function compare_arrays_hash_isset($liste1, $liste2)
{
$hash2 = toHash($liste2);
$nbr = 0;
foreach ($liste1 as $mot1)
{
if (isset($hash2[$mot1]))
{
$nbr++;
}
}
return $nbr;
}Effectivement,nous y gagnons en performances : la version basée sur l'utilisation de array_key_exists durait 13 ms ; celle-ci ne met plus que 0.696 ms !
Tester l'existence d'une clef d'un tableau avec
issetest plus rapide que de tester son existence par un appel àarray_key_exists
Attention : isset et array_key_exists ne font pas exactement la même chose !
En particulier, isset renverra false si la valeur correspond à la clef demandée existe, mais vaut null !
Test de l'existence de clefs dans un Hash construit via array_flip
La solution proposée juste au-dessus commence à nous donner des résultats intéressants en termes de performance... Mais il doit encore être possible de faire mieux...
Elle commence par "retourner" la liste de un tableau associatif, dont les clefs sont les mots de chaque liste... Et ceci était fait via un appel à une fonction développée par nos soins...
Hors, nous avons vu plus haut que ré-inventer la roue n'était pas optimal question performances... Fouillons donc un peu dans la documentation de la bibliothèque PHP, à la recherche d'une fonction qui pourrait effectuer ce "retournement" pour nous...
Et une telle fonction existe : array_flip.
En la mettant en application, voici le code obtenu pour notre fonction de comparaison :
function compare_arrays_hash_flip_isset($liste1, $liste2)
{
$hash2 = array_flip($liste2);
$nbr = 0;
foreach ($liste1 as $mot1)
{
if (isset($hash2[$mot1]))
{
$nbr++;
}
}
return $nbr;
}Et là, nous descendons à 0.488 ms ! Soit une fois et demie plus rapide que la version précédente, en écrivant moins de code !
Le gain ici est l'utilisation d'une fonction de la bibliothèque PHP pour "retourner" la liste, plutôt que d'une boucle "à la main", en PHP. Il s'agit donc encore du même type de gain que déjà rencontré plusieurs fois !
Pour rappel, la première solution proposée demandait 176 ms pour s'exécuter ; celle-ci demande moins d'une demi-milli-seconde !
Résultats des comparaisons
Mettons maintenant côtes-à-côtes les appels à chacune de ces fonctions, pour déterminer lesquelles sont performantes et lesquelles ne le sont pas.
Premier scénario de tests
Code de test
Voici le premier scénario de tests utilisé ; celui dont les résultats ont été utilisés plus haut pour comparer chacune des solutions proposées :
$nbrIterations = 1;Le principe est simple : on appelle $nbrIterations fois chacune des fonctions pour comparer les deux premiers articles :
$liste1 = $articles[0];
$liste2 = $articles[1];
for ($i=0 ; $i<$nbrIterations ; $i++)
{
$nbr1 = compare_arrays_our($liste1, $liste2);
$nbr2 = compare_arrays($liste1, $liste2);
$nbr3 = compare_arrays_hash_keys($liste1, $liste2);
$nbr4 = compare_arrays_intersect($liste1, $liste2);
$nbr5 = compare_arrays_hash_isset($liste1, $liste2);
$nbr6 = compare_arrays_hash_flip_isset($liste1, $liste2);
}Et voici les résultats obtenus :
Pour une itération
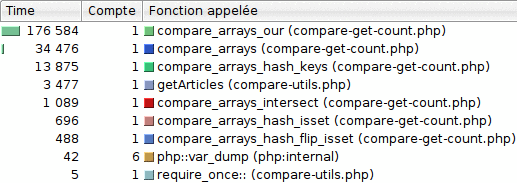
Les fonctions étant classées, de haut en bas, par durée d'exécution décroissante, je pense que cette capture d'écran parle d'elle-même...
Pour 100 itérations : Callgraph
Et voici, pour les plus visuels d'entre vous, ce que donne le graphe d'appels :
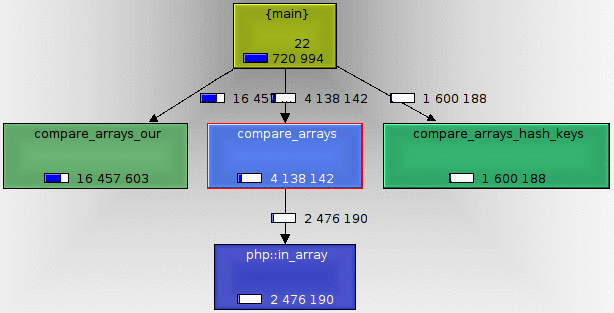
Vous noterez que l'outil que j'utilise ne présent que les fonctions durant plus de 1% du temps d'exécution du test...
Et ici, seules trois des six solutions de recherche proposées sont affichées ! Parlant, n'est-ce pas ?
En supprimant les deux méthodes les plus coûteuses, 100 itérations
En lançant 100 fois le test, en supprimant les deux solutions les plus coûteuses, voici ce que l'on obtient :

Et une autre représentation graphique serait la suivante :
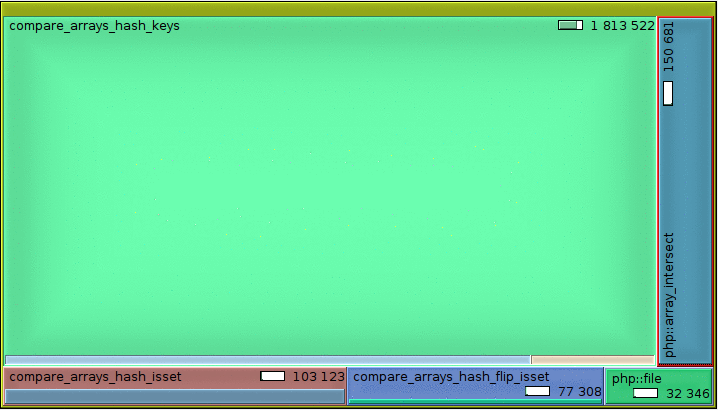
Les tailles de chacun des blocs sont proportionnelles aux temps d'exécution de chaque méthodes dont ils portent les noms...
Voyant ceci, quelle solution adopteriez-vous ? Ou plutôt, quelle solution n'adopteriez-vous pas ?
Second scénario de test
Code de test
Et voici le code du second scénario :
Ici, on compare tous les articles les uns avec les autres - et encore une fois, avec un nombre d'itérations paramétrable.
foreach ($articles as $liste2)
{
foreach ($articles as $liste1)
{
for ($i=0 ; $i<$nbrIterations ; $i++)
{
compare_arrays_our($liste1, $liste2);
}
for ($i=0 ; $i<$nbrIterations ; $i++)
{
compare_arrays($liste1, $liste2);
}
for ($i=0 ; $i<$nbrIterations ; $i++)
{
compare_arrays_hash_keys($liste1, $liste2);
}
for ($i=0 ; $i<$nbrIterations ; $i++)
{
compare_arrays_intersect($liste1, $liste2);
}
for ($i=0 ; $i<$nbrIterations ; $i++)
{
compare_arrays_hash_isset($liste1, $liste2);
}
for ($i=0 ; $i<$nbrIterations ; $i++)
{
compare_arrays_hash_flip_isset($liste1, $liste2);
}
} // Fin second parcours
} // Fin premier parcours(Oui, on aurait pu faire plus élégant, notamment sur les boucles d'itérations...)
Notez que, puisque l'on compare tous les articles les uns par rapport aux autres, et qu'il y avait 13 articles dans le jeu de test, le nombre d'itérations est à multiplier par 13*13 = 169 pour obtenir le nombre d'appels à chacune des fonctions testées !
Voici les temps d'exécution obtenus pour 10 itérations (1690 exécutions)
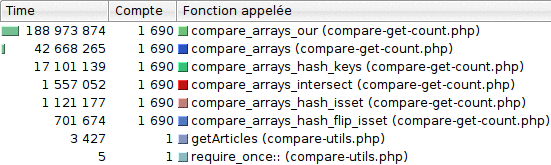
Les résultats obtenus sont proches des précédents : peut-être des variations mineures, mais l'idée globale est proche : ce sont toujours les mêmes implémentations qui sont les plus lentes... Et les autres qui sont les plus rapides.
Et en retournant la liste de mots communs aux deux articles ?
Pour finir, voici une comparaison des mêmes fonctions, mais modifiées pour retourner la liste des mots communs aux deux articles, plutôt que uniquement leur nombre.
Le scénario de test est le suivant :
$liste1 = $articles[0];
$liste2 = $articles[1];
for ($i=0 ; $i<$nbrIterations ; $i++)
{
$tab1 = compare_arrays_our($liste1, $liste2);
$tab2 = compare_arrays($liste1, $liste2);
$tab3 = compare_arrays_hash_keys($liste1, $liste2);
$tab4 = compare_arrays_intersect($liste1, $liste2);
$tab5 = compare_arrays_hash_isset($liste1, $liste2);
$tab6 = compare_arrays_hash_flip_isset($liste1, $liste2);
}Par sécurité, on vérifie que tous les appels ont retourné la même liste :
var_dump(
array_diff(
$tab1, $tab2, $tab3,
$tab4, $tab5, $tab6
)
);Et... oui :
array(0) {
}
Et les résultats, sur 100 it"rations, sont les suivants :

Soit le même type de graphe que ceux obtenus précédemment, lorsque nous ne retournions que les nombres de mots en commun.
Avec une différence tout de même : les temps d'exécution sont légèrement supérieurs à ceux obtenus précédemment - mais il fallait s'y attendre : on doit construire la liste à retourner, plutôt que d'effectuer un simple comptage...
Conclusions
Après avoir vu les résultats obtenus pour différents types de méthodes de comparaisons de tableaux en PHP, ou, surtout, après avoir constaté les écarts énormes entre certains types de solutions, que peut-on ajouter en conclusion, qui soit plus parlante que les graphiques présentés plus haut ?
LE point dont il faut se souvenir, je pense, est le suivant : n'effectuez pas de parcours inutiles !
Les deux boucles foreach de notre première solution sont une catastrophe, d'un point de vue performances !
Même si l'idée d'effectuer un double parcours n'est pas fantastique, en utilisant in_array pour remplacer le foreach interne et la comparaison, on a effectué le plus gros gain de tout cet article !
D'où cette première conclusion :
Ne réinventez pas la roue : utilisez à bon escient les fonctions de la bibliothèque PHP.
Considérant qu'elles sont codées en C, et utilisées tous les jours de manière intensives, il est à parier qu'elles seront plus performantes que vos ré-implémentations en PHP.
Le second plus gros gain a été réalisé en testant l'existence de clefs dans un Hash, plutôt qu'en parcourant une liste à la recherche d'une valeur.
Là, il s'agit de savoir que la recherche d'une clef est plus rapide que la recherche d'une valeur[3].
D'où cette seconde recommandation :
Utilisez au maximum les spécificités du langage avec lequel vous travaillez.
Comment penser à ce genre "d'astuce" ? Souvenez-vous de vos cours d'algorithmique, lorsque vous travaillez sur les arbres binaires et/ou les tables de Hachage...
Même sans savoir comment sont, en interne, implémentés les tableaux associatifs de PHP, il semble probable que ce soit à l'aide d'une solution bien plus optimisée qu'une liste plate !
Notes
[1] J'allais dire "assez ancienne" (ça fait des mois que cet article est dans mes cartons et que je parviens à me décider à le terminer...), mais je suis reparti d'une version à jour avant de le publier ; donc, les données de tests correspondent à une extraction du flux RSS du site, datant de début décembre 2007.
[2] "Construction de langage étant une traduction de "language construct" - quelque chose de directement inclu au langage, autrement dit.
[3] Attention, cela dit, isset n'est pas non plus la solution magique à tous les problèmes ; ne serait-ce parce qu'elle renvoi true quand on l'appelle sur une variable valant null...


