Table des matières
L'optimisation des performances n'est pas une histoire de remplacement de tous vos guillemets doubles par des guillemets simples, en priant que quelques nano-secondes gagnées empécheront Apache d'aller travailler en swap, en envoyant votre serveur mordre la poussière le jour où vous serez listé sur Digg. Il s'agit plutôt d'un processus réfléchi, qui passe par la définition d'objectifs de performance, la réalisation de benchmarks pour mesurer les performances actuelles, l'identification de points inefficaces et de goulots d'étranglement, l'achat de serveurs physiques appropriés, et la recherche de nouvelles tactiques auxquelles vous n'auriez jamais pensé. En d'autres mots, beaucoup de fun en prévision !
Au cours de cette annexe, nous verrons l'optimisation des performances sous la forme de plusieurs approches et techniques souvent utilisées dans le monde réel ; nous ne soucierons pas vraiment de points comme les guillemets doubles (sauf en cas de résultat perceptible). La plupart des points que nous verrons devraient devenir familiers, s'ils ne le sont pas déjà.
Puisque détailler les options orientées performances est une tâche d'envergure, cette annexe sera plutôt longue, mais j'espère qu'elle sera utile. Je n'ai pas l'intention de limiter cette annexe à Zend Framework uniquement, et beaucoup de points que nous aborderons ici s'appliquent à n'importe quelle application PHP.
Avant que nous ne fassions quoi que ce soit, soyons clair sur le fait que vous ne devriez pas sacrifier une conception d'application solide sur l'autel de l'optimisation prématurée. L'optimisation prématurée est, comme Sr. Tony Hoare l'a initialement dit, la cause de tous les maux[1]. Cela dit, ne sortons pas non plus cette phrase de son contexte ! Toujours repousser l'optimisation revient finalement à ne jamais obtenir une application qui soit efficace. Eventuellement, la tentation peut devenir des plus fortes, mais le moment où réaliser les optimisations est important. Optimiser trop tôt peut amener à une conception restrictive, qui ne causera que plus de problème, donc il vaut mieux attendre jusqu'à ce que l'application soit dans un état propice à l'optimisation.
Optimiser est le jeu de
l'élimination des inefficacités mesurables. Le mot important, ici, est
"mesurable". Si vous ne pouvez pas mesurer ou prédire de façon fiable
l'impact d'une optimisation, comment saurez-vous si elle en valait la
peine ? Un bête remplacement de quelques guillemets doubles par des
guillemets simples prenant des heures de temps à un développeur pourrait
vous apporter un gain de performances complétement non-remarquable. Vous
avez juste perdu une heure, en n'avez quasiment rien gagné, ou, en tout
rien, rien qui mérite fierté ! Pendant ce temps, il y a une requête SQL
lente qui, en appliquant un mécanisme de cache en quelques minutes de
travail avec Zend_Cache, vous apporterait un gain
d'une seconde. De toute évidence, la seconde option mérite bien plus votre
attention. Concentrez vos efforts sur les optimisations qui apportent le
plus grand bénéfice.
Il existe trois approches à l'optimisation : suivre vos croyances aveugles, suivre votre intuition expérimentée, et utiliser des outils logiciels pour analyser les applications à la recherche d'opportunités d'optimisation. La troisième est la seule option réellement valable. Les autres sont incertaines, et vous risquez de passer à côté d'optimisations intéressantes, ou de tout simplement gaspiller votre temps sur des points qui n'en valent pas le coup. Ceci ne rend pas les deux premières options totalement invalides, mais elles relèvent souvent du type d'optimisations que n'importe quel programmeur raisonable depuis appliquer tout au long du développement ; pas de domaines qui devraient nécessiter des heures d'attention après-coup.
Un programmeur expérimenté ne créera que rarement une application horriblement inefficace remplie de portions de code source incorrectes. Quelques éléments déjà optimisés niveau performances seront déjà présent dans le design existant, et, donc, ce qu'il reste à faire est de pousser les choses plus loin, de manière réfléchie. Beaucoup d'optimisations relèvent du bon sens, puisqu'une fois que vous avez compris le problème, il n'y a pas tant de solutions différentes entre lesquelles choisir, et la plupart de celles-ci auront déjà été blogguées par la moitié de la planète.
Optimiser ne fonctionne que si vous pouvez obtenir des résultats mesurables et significatifs. Significatifs, ben entendu, est relatif : quelques millisecondes gagnées pour un développeur peuvent représenter des secondes pour un autre. Au fur et à mesure que vous optimiserez les problèmes de performance les plus évidents, moins de problèmes seront visibles facilement, jusqu'à ce que vous atteignez un état dans lequel optimiser plus aille de pair avec un coût qui devienne supérieur au bénéfice final ou à celui de tout simplement ajouter plus de machines. Dans tous les cas, vous devriez avoir un objectif de performance à l'esprit, et atteindre cet objectif requiert de mesurer les performances actuelles pour définir un point de départ, ainsi que de mesurer les performances futures en vue de déterminer si vous avez effectué quelque amélioration significative que ce soit par rapport à ce point de départ.
Les mesures de performances reviennent généralement à quelques métriques. Les utilisations mémoire et CPU sont celles qui sont évidentes, en particulier sur un seul serveur où les ressources sont limitées. Mais même dans un environnement où vous scalez votre matériel, que ce soit verticalement ou horizontalement, maximiser les performances peut vous éviter de dépenser inutilement en serveurs coûteux pour compenser les problèmes d'un code tout sauf optimal. Une autre mesure commune, à côté de ces deux points, est le nombre de requêtes par seconde ; cela revient à déterminer combien de requêtes une partie de votre application est capable de servir par seconde, considérant le matériel qui l'héberge actuellement.
Mesurer l'occupation
mémoire peut être fait aussi bien au niveau du serveur qu'au niveau de
PHP. PHP fourni deux fonctions utiles qui mesurent combien de mémoire il
utilise. memory_get_usage() et
memory_get_peak_usage() peuvent être appelées
pour déterminer combien d'octets sont utilisés soit à un instant précis,
soit au maximum. Ces fonctions sont typiquement utilisées pour avoir une
idée générale du profil d'occupation mémoire d'une application :
déterminer où dans l'application la mémoire est perdue au-delà d'un
seuil de tolérance acceptable. Déterminer ce seuil de tolérance n'est
pas une tâche simple, puisque certaines fonctionnalités peuvent demander
plus de mémoire que d'autres. Si votre php.ini
inclut une limite de mémoire assez haute, c'est pour une bonne raison
!
Une technique utile fait référence à la futilité que représentent des mesures manuelles. Plutôt que de cliquer sur tous les liens possibles et de soumettre tous les formulaires imaginables à la main, définissez simplement quelques emplacements dans le code source où ces mesures peuvent être effectuées. Que vous fassiez cela en utilisant des outils logiciels qui attaquent automatiquement tous les chemins possibles (les Tests Fonctionnels Automatisés peuvent être un bon point de départ, si vous en avez mis en place sur votre projet), ou en collant une étiquette Bêta sur un site de production et en le laissant tourner pour une courte période est un choix qui vous revient.
Une solution possible,
bien qu'un peu brute, est d'écrire un petit Plugin de Contrôleur, qui
implémente la méthode
Zend_Controller_Plugin_Abstract::dispatchLoopShutdown()
:
<?phpclass ZFExt_Controller_Plugin_MemoryPeakUsageLogextends Zend_Controller_Plugin_Abstract{protected $_log = null;public function __construct(Zend_Log $log){$this->_log = $log;}public function dispatchLoopShutdown(){$peakUsage = memory_get_peak_usage(true);$url = $this->getRequest()->getRequestUri();$this->_log->info($peakUsage . ' bytes ' . $url);}}
Vous pouvez l'activer depuis votre Bootstrap lorsque vous voulez l'utiliser :
<?phpclass ZFExt_Bootstrap{// ...public function enableMemoryUsageLogging(){$writer = new Zend_Log_Writer_Stream(self::$root . '/logs/memory_usage');$log = new Zend_Log($writer);$plugin = new ZFExt_Controller_Plugin_MemoryPeakUsageLog($log);/*** Use a high stack index to delay execution until other* plugins are finished, and their memory can also be accounted* for.*/self::$frontController->registerPlugin($plugin, 100);}// ...}
C'est un exemple assez basique, et vous pourriez facilement adapter quelque chose de similaire pour logger des informations similaires à propos de la requête initiale, pour que vous ayez suffisament d'informations pour pouvoir re-jouer ladite requête dans un environnement mieux contrôlé, afin de déterminer précisément la raison expliquant les fuites mémoires. Voici quelques lignes de sorties obtenues depuis le log activé au-dessus :
2009-01-09T15:41:46+00:00 INFO (6): 4102728 bytes / 2009-01-09T15:42:57+00:00 INFO (6): 4103608 bytes /index/comments
Si vous préférez observer l'occupation mémoire à la volée, vous pouvez utiliser un stream PHP différent pour la stratégie d'écriture, ou même utiliser le Writer Firebug pour regarder les résultats en direct lorsque vous utilisez Firefox avec FirePHP.
Une fois que vous avez un profil mémoire un peu grossier, vous pouvez utiliser une approche systématique, comme du profiling de code, pour accumuler des détails sur les points qui expliquent toutes les allocations mémoire. Le Profiling de Code est aussi une bonne solution pour déterminer où du temps est passé à l'exécution.
En dehors des solutions intégrées à l'application, vous pouvez aussi suivre les occupations mémoire et CPU sur le serveur où est déployée l'application, en utilisant un grand nombre d'applications variées. Les systèmes Linux fournissent les outils top, free, vmstat, et bien d'autres. Un de mes favoris est htop, qui affiche un résumé fréquemment mis à jour de la mémoire, du CPU, et des données de chaque processus, avec quelques fonctionnalités pour ordonner les processus en fonction de différentes statistiques.
Ces points sont particulièrement utiles lorsque vous configurez des serveurs pour qu'ils hébergent votre application, mais, de toute évidence, ils peuvent aussi vous aider à voir comment votre application se comporte sur un serveur de test pré-optimisé, lorsque vous lancez des tirs de performance : combien de mémoire est-ce que les processus Apache utilisent, pouvous-nous lancer plus ou moins de clients Apache, quelles parties de l'application consomment le maximum de CPU plutôt que de RAM ?
Les tests de tenue à la charge sont un autre outil utile lorsqu'il s'agit de mesurer les performances d'une application. Les résultats sont influencés, de manière importante, par le matériel sur lequel les tests sont effectués, donc, pour conserver des résultats comparables entre chaque lancement, vous aurez besoin d'un système de test dont les spécifications et la charge générale restent contantes. Leur objectif est de mesurer à combien de requêtes votre application (une URL spécifique, ou un ensemble d'URLs) peut répondre par seconde en moyenne. Le temps pris est souvent moins important (il varie en fonction du matériel), donc c'est la variation relative entre les mesures qui indique si votre application devient plus ou moins performante. Vous remarquerez que la plupart des Benchmarks de Frameworks ont tendance à être obsédés par cette valeur.
L'approche, relativement simple, est de simuler l'effet d'être touché par un nombre spécifique de requêtes réparties entre un nombre donné d'utilisateurs concurrents. Des fois, l'élément de base est une période de temps, à la place d'un nombre fixe de requêtes. Le nombre total de requêtes est ensuite divisé par le temps en secondes pris pour répondre à ce nombre de requêtes. Cette idée est extrêmement efficace lorsqu'il s'agit de noter comment les performances d'une application évoluent alors que vous optimisez l'application et/ou le serveur qui l'héberge.
Deux outils fréquemment utilisés pour cela sont ApacheBench (ab) et Siege.
L'outil ApacheBench
est normalement installé avec les exécutables du serveur HTTP. S'il
manque, parfois, il vous faudra installer un paquet nommé Apache Utils.
Sous Ubuntu, il est généralement enregistré sous
/usr/sbin/ab, qui peut ne pas être inclu dans le
PATH d'Ubuntu par défaut, ce qui signifie que vous devrez soit ajouter
/usr/sbin au PATH de votre utilisateur courant, ou
l'appeler en utilisant son chemin absolu.
Voici la commande ApacheBench permettant de lancer 10,000 requêtes réparties sur 100 utilisateurs concurents (Le slash final est important pour les URLs nues) :
ab -n 10000 -c 100 http://www.survivethedeepend.com/
La sortie obtenue ressemblera à quelque chose de ce type :
Server Software: apache2
Server Hostname: www.survivethedeepend.com
Server Port: 80
Document Path: /
Document Length: 9929 bytes
Concurrency Level: 100
Time taken for tests: 341.355 seconds
Complete requests: 10000
Failed requests: 0
Write errors: 0
Total transferred: 101160000 bytes
HTML transferred: 99290000 bytes
Requests per second: 29.29 [#/sec] (mean)
Time per request: 3413.555 [ms] (mean)
Time per request: 34.136 [ms] (mean, across all concurrent requests)
Transfer rate: 289.40 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 1.7 0 52
Processing: 124 3409 831.1 3312 10745
Waiting: 120 3267 818.5 3168 10745
Total: 124 3409 831.1 3312 10745
Percentage of the requests served within a certain time (ms)
50% 3312
66% 3592
75% 3784
80% 3924
90% 4344
95% 4828
98% 5576
99% 6284
100% 10745 (longest request)
Voici un exemple similaire pour Siege, où vous définissez le nombre total de requêtes en configurant le nombre d'utilisateurs concurrents, avec un facteur de répétition pour chaque. Donc, 100 utilisateurs en concurrence répétant des requêtes 10 fois vous donnera un total de 1,000 requêtes. L'option supplémentaire indique un délai d'une seconde entre les accès concurrents, ce qui est suffisant pour des tests de performance.
siege -c 100 -r 10 -d 1 http://www.survivethedeepend.com
Les résultats sont un brin plus court, mais montrent toujours le nombre de requêtes par seconde, sous l'entrée "Transaction rate" :
Transactions: 1000 hits Availability: 100.00 % Elapsed time: 43.77 secs Data transferred: 3.06 MB Response time: 3.20 secs Transaction rate: 22.85 trans/sec Throughput: 0.07 MB/sec Concurrency: 73.08 Successful transactions: 1000 Failed transactions: 0 Longest transaction: 8.78 Shortest transaction: 0.05
Ces deux outils de test de charge viennent avec une grande variété d'autres options qui méritent de fouiller plus en profondeur. Lorsque vous arrivez au moment de déployer sur un serveur, méler ce type de tests avec le monitoring des ressources de votre serveur comme la mémoire et le CPU peut vous apporter pas mal d'informations utiles à l'optimisation de la configuration Apache.
Et oui, les performances du site web du livre était catastrophiques au moment où j'ai joué ces tests de charge ! Si j'avais caché les pages correctement à ce moment là, les nombres de requêtes par seconde auraient été largement plus élevés.
Notons que les tests de charge prennent en compte à la fois les aspects logiciels et matériels, et sont donc un outil utile pour l'optimisation d'un serveur, en plus de la mesure des performances d'une application.
Plutôt que de sélectionner aléatoirement des portions de code source à optimiser, en croisant les doigts pour la chance, voici quelques méthodes qui permettent d'identifier des problèmes de performance spécifiques.
Un regard d'ensemble, en lançant des tirs de performance et en monitorant l'utilisation des ressources, vous donnera une idée de base des parties de l'applications qui se comportent mieux, ou moins bien, que la moyenne. Cela dit, si vous trouvez un problème de performances, la seule manière qui vous permette de localiser sa cause réelle est de rechercher tout ce qui peut coûter, niveau performances, à travers l'ensemble de tout le code source exécuté. Dans une application simple, lire le source peut être envisageable, mais une application plus complexe pourrait effectuer des opérations en base de données, des traitements sur des fichiers, ou un nombre incalculable d'autres opérations qui ont un effet sur les performances. En considérant que votre application peut aussi dépendre de bibliothèques externes, lire son code source n'est pas aussi simple qu'il paraît.
Le Profiling de Code, ou le Timing de Méthodes, est un moyen de découper une requête de manière à pouvoir examiner le temps d'exécution et l'utilisation mémoire de chaque appel de fonction ou de méthode effectués pour cette requête. C'est une solution qui apporte une aide inestimable lorsqu'il s'agit de diagnostiquer les problèmes de performances et d'identifier des cibles pour l'optimisation.
Un Profiler communément utilisé en PHP est l'extension Xdebug développée par Derick Rethans. Xdebug fournit des fonctionnalités pour le débuggage, le profiling, et l'analyse de couverture de code[2]. La fonctionnalité de Profiling génére des fichiers compatibles avec cachegrind, qui peuvent être analysés sous forme de données lisibles par n'importe quelle application compatible avec cachegrind, comme KCacheGrind (KDE), WinCacheGrind (Win32), ou l'application Web WebGrind.
En fonction de l'application cachegrind que vous choisirez, elle proposera plusieurs méthodes de visualisation du temps passé au sein de chaque fonction, méthode, et mots-clefs. De toute évidence, ce sont les points avec le temps ou l'occupation mémoire les plus importants qui méritent un examen le plus approfondi, afin de déterminer s'ils peuvent être optimisés de manière à obtenir un gain non-négligeable.
La version courant est disponible via PECL, et vous pouvez l'installer avec un simple :
pecl install xdebug
Cette commande téléchargera et compilera Xdebug. Si vous travaillez sous Windows, des binaires précompilés sont proposés au téléchargement sur la page téléchargements du site de Xdebug.
Pour terminer
l'installation, nous pouvons configurer Xdebug pour le profiling en
ajoutant les lignes qui suivent à votre fichier
php.ini, en veillant à remplacer ou à commenter
toute ligne utilisant les options de configuration
zend_extension ou zend_extension_ts qui s'y
trouvait déjà. Voici un exemple de configuration ajouté à un système
Ubuntu dans /etc/php/conf.d/xdebug.ini (Ubuntu
accepte des fichiers spécifiques aux extensions, en plus de
/etc/php5/apache2/php.ini) :
; Xdebug zend_extension = /usr/lib/php5/20060613/xdebug.so ;xdebug.profiler_enable = 1 xdebug.profiler_output_dir = "/tmp" xdebug.profiler_output_name = "cachegrind.out.%t.%p"
Lorsque vous voulez
commencer à profiler, supprimez le point-virgule au début de la ligne de
configuration de xdebug.profiler_enable. Remettez le une
fois que vous avez terminé, à moins que vous n'aimiez avoir des fichiers
cachegrind gigantesques qui remplissent votre disque dur. Voici un
exemple de sortie obtenu via Webgrind sur une machine Windows, qui
indique le pourcentage du temps d'exécution qui est passé pour chaque
fonction/méthode :
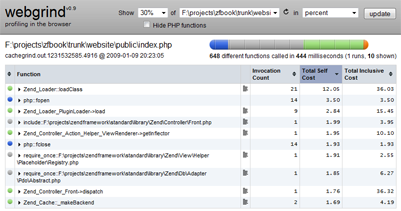
Installer Webgrind ne
demande que de copier ce que vous avez téléchargé vers votre Document
Root Apache, et de modifier le fichier config.php
pour supprimer les options $storageDir et
$storageProfiler (la configuration de Xdebug
fournie plus haut est suffisante pour que Webgrind détecte ces valeurs
automatiquement). Utiliser la configuration reproduite plus haut avec
xdebug.profiler_output_name devrait être suffisant pour
pouvoir lire n'importe quel fichier de sortie cachegrind généré par
Xdebug.
En utilisant du
profiling de code, et en générant des fichiers cachegrind pour une large
plage d'URIs de notre application, nous pouvons maintenant fouiller dans
le code source pour trouver qui est méchant et prend le plus de temps à
s'exécuter. Comme nous le remarquerez depuis la capture d'écran
au-dessus, Zend_Loader semble être plutôt
gourmand, puisqu'il prend quasiment 25% du temps de génération de la
page d'index. De toute évidence, 25% est assez pour mériter notre
attention !
Xdebug vous permettra d'analyser l'exécution de votre code, mais il existe d'autres alternatives ou solutions complémentaires pour vous aider à localiser des opportunités d'optimisation. L'une des cibles les plus évidentes est la base de données.
Se connecter à une base de données implique plusieurs types de problématiques. Tout d'abord, les opérations en base de données sont extrêmement coûteuses. Votre application va devoir ouvrir une connexion vers le serveur de base de données, envoyer la requête, attendre que celle-ci ait été traitée, lire les résultats renvoyés, effectuer quelques traitements de plus, et vraiment... C'est un sacré foutoir ! Dans la plupart des applications web, la base de données sera un goulot d'étranglement majeur, qui prendra une bonne partie de votre temps d'exécution.
Des bénéfices liés à
l'optimisation peuvent être réalisés en examinant la méthode d'accès à
la base de données, qui, dans le cas de Zend Framework, va inclure
Zend_Db_Table et vos Modèles, la complexité et
les besoins en traitements des requêtes SQL, ainsi que la taille des
données récupérées depuis la base de données.
Dans les trois cas ou
presque, où vous avez des cibles d'optimisation évidentes et mesurées,
utiliser du cache est une stratégie qui apportera probablement des
gains, dans les cas où les données obtenues ne changent que peu
fréquemment, et où les données elles-mêmes sont de taille importante, ou
lorsque le résultat est obtenu en jouant une requête identifiée comme
étant lente. Pourquoi constamment bombarder la base de données pour des
données qui ne changent que toutes les quelques heures, jours, ou même
semaines ? Mettez-les en cache ! Cacher en mémoire en utilisant APC ou
memcached serait de toute évidence préférable, mais un cache à base de
fichiers fera l'affaire si les ressources mémoire sont limitées.
Définissez une durée de vie appropriées ou effacez manuellement la
donnée cachée lorsqu'elle change. Zend_Cache rend
l'organisation de la gestion du cache aussi simple qu'une balade au
parc. Voici un exemple utilisant un simple Modèle Comments, où la
configuration du cache est gérée depuis le fichier de configuration
config.ini principal de l'application :
[general] ; SQL Query Cache cache.sql.frontend.name=Core cache.sql.frontend.options.lifetime=7200 cache.sql.frontend.options.automatic_serialization=true cache.sql.backend.name=File cache.sql.backend.options.cache_dir=/cache/sql
<?phpclass Comments extends Zend_Db_Table{protected $_name = 'comments';protected $_cache = null;public function init() {/*** config.ini general sections stored into Zend_Registry* Ideally the static calls would be replaced with dependency* injection*/$options = Zend_Registry::get('configuration')->cache->sql;$options->backend->options->cache_dir =ZFExt_Bootstrap::$root . $options->backend->options->cache_dir;$this->_cache = Zend_Cache::factory($options->frontend->name,$options->backend->name,$options->frontend->options->toArray(),$options->backend->options->toArray());}public function getComments($id){// pull data from cache, or else hit database and cache resultsif (!$result = $this->_cache->load('ENTRY_COMMENTS_' . $id)) {$select = $this->select()->where('entry_id = ?',$id)->where('status = ?','approved')->where('type = ?','comment')->order('date ASC');$result = $this->fetchAll($select);$this->_cache->save($result, 'ENTRY_COMMENTS_' . $id);}return $result;}public function insert($data) {// invalidate existing cache when saving new comments$this->_cache->remove('ENTRY_COMMENTS_' . $data['entry_id']);return parent::insert($data);}}
Si les données
changent en permanence, une situation habituelle lorsque le contenu est
dynamique, généré par l'utilisateur ou dépendant des préférences de
celui-ci, utiliser du cache n'apportera pas un gain important. Le cache
peut devenir invalide avant même que Zend_Cache
ne termine de l'écrire ! Dans ce genre de situation, vous devrez voir si
remplacer l'utilisation de Zend_Db_Table par du
SQL écrit à la main, ou si revoir le SQL lui-même pour améliorer ses
performances, peut avoir un effet perceptible. Lorsque vous travaillez
avec un large jeu de données, assurez-vous que seules les données utiles
soient récupérées. Il est inutile de charger des champs supplémentaires
s'ils ne sont jamais utilisés, et que la seule chose qu'ils feront est
consommer de la mémoire inutilement, privant ainsi votre serveur d'une
quantité non-négligeable de précieuse RAM.
Un point auquel vous
pouvez particulièrement prêter attention, par exemple, est le Log des
requêtes lentes de MySQL. Cette fonctionnalité vous permet de définir,
en utilisant l'option de configuration long_query_time, le
nombre de secondes à partir duquel une requête doit être considérée
comme lente. Toutes les requêtes lentes peuvent être logguées, afin de
pouvoir être examinées plus en détails par la suite. Puisque les
requêtes lentes sont mesurées en temps réel, il est intéressant de noter
que des tirs de performance sur une application vont augmenter son taux
de détection, puisque les ressources CPU et mémoire de la machine seront
fortement utilisées. Utilisez une valeur plus basse pour
long_query_time si vous voulez faire confiance aux logs
générés sur une machine de développement.
Zend Framework inclut
sa propre solution de logging pour toutes les requêtes SQL, pour
profiler celles qui sont jouées, et combien de temps elles prennent, en
utilisant Zend_Db_Profiler. Le profiler peut être
activé en passant une option nommée "profiler" à la valeur
booléenne TRUE avec les autres options, lors de la
construction d'un adapter de base de données. Ensuite, vous pouvez
instancier la classe Zend_Db_Profiler, et
utiliser un ensemble de méthodes pour voir combien de requêtes ont été
jouées, combien de temps elles ont pris au total pour être exécutées, et
obtenir une liste de profils de requêtes sur lesquels effectuer une
analyse plus en profondeur, en utilisant les filtres appropriés. Il
existe même une classe spéciale, nommée
Zend_Db_Profiler_Firebug, que vous pouvez
utiliser pour voir les données de profiling à la volée, via la console
de Firebug dans Firefox.
PHP a un grand nombre d'optimisations bien connues, et d'autres moins connues, qui sont maintenant perçues comme des habitudes standard. Quelques-unes de celles-ci sont devenues plus importantes pendant la durée de vie de PHP 5.2.
L'utilisation d'un cache d'opcode, comme l'extension Alternative PHP Cache (APC), peut avoir un impact significatif sur les performances de toute application PHP, en cachant le code intermédiaire obtenu lors du parsing d'un code source PHP. Sauter cette étape de traitement et réutiliser le cache dans les requêtes suivantes économise de la mémoire et améliore les temps d'exécution. Installer un mécanisme de cache d'opcode devrait être une pratique standard, à moins que vous ne soyez coincé sur un hébergement mutualisé limité.
Installer APC est un processus relativement simple en utilisant pecl. Sous Linux, utilisez :
pecl install apc
Les utilisateurs de
Windows peuvent télécharger une DLL pré-compilée depuis http://pecl4win.php.net.
La dernière étape est
d'ajouter la configuration d'APC à votre fichier
php.ini, ou de créer un nouveau fichier
apc.ini, sous l'installation standard d'Ubuntu,
dans /etc/php5/conf.d/apc.ini :
;APC extension=apc.so apc.shm_size = 50
La configuration que
vous définissez peut avoir des effets supplémentaires sur les
performances, et je vous suggère de lire la documentation accessible à
http://php.net/manual/en/apc.configuration.php.
Faites tout particulièrement attention à apc.shm_size,
apc.slam_defense (ou apc.write_lock),
apc.stat et apc.include_once_override. Vous
devriez vous assurer que apc.shm_size soit, au minimum,
configuré à une valeur suffisante pour mettre en cache toutes les
classes utilisées par votre application (et quoi que ce soit d'autre que
vous hébergiez !). N'oubliez pas de prendre en compte les autres données
que vous pourriez stocker là via Zend_Cache ou
les fonctions d'apc.
Une des nouveautés
dont la configuration a été le plus récemment ajoutée au fichier
php.ini est un cache de chemins réels[3], introduit avec PHP 5.2.0. Il a été conçu pour mettre en
cache les valeurs de chemins réels des chemins relatifs utilisés pour
les instructions include_once et require_once.
Avant cela, à chaque fois que vous appeliez require_once
avec un chemin relatif, toute une série de traitements de fichiers
étaient effectués pour trouver le fichier auquel vous faisiez référence.
Maintenant, ceci n'est plus fait qu'une seule fois, et mis en cache
pendant la durée spécifiée, pour les prochaines recherches.
Les options de
configuration qui correspondent sont realpath_cache_size
and realpath_cache_ttl. La première définit la taille du
cache, et vaut par défaut 16K. Ce n'est de toute évidence pas une grande
valeur, et elle devrait être augmentée pour les applications chargeant
un grand nombre de fichiers. La durée de vie dépend de la fréquence à
laquelle les emplacements de fichiers changent. Si ce n'est que
rarement, vous pouvez envisager d'augmenter cette valeur au-delà des 120
secondes par défaut. J'ai augmenté cette valeur largement au-delà de
plusieurs minutes sans effet négatif, mais je me montrerais plus prudent
si j'avais de grandes quantités de fichiers à déplacer.
Jusqu'à présent, nous avons vu pas mal de points assez généralistes. Zend Framework, en tant que cible d'optimisations, a de quoi faire. Puisqu'il s'agit d'un Framework qui assure la compatibilité antérieure, certaines optimisations sont omises dans la version actuelle, pour maintenir la rétro-compatibilité et supporter une version mimale de PHP.
Cela ne signifie pas que nous devrions passer notre chemin et ne rien faire !
A cause de la façon
dont Zend Framework est structuré, le code source regorge d'une quantité
d'instructions require_once. Bien que cela puisse ne pas
donner l'impression d'être important, considérant la taille du
Framework, cela signifie souvent avoir un grand nombre de fichiers
inutiles chargés, analysés, et préparés pour exécution... Alors qu'ils
ne sont jamais utilisés.
Limiter le nombre de classes chargées peut apporter un léger gain. C'est obtenu en utilisant la fonctionnalité d'autoload de PHP, qui charge dynamiquement les classes à la demande (pour faire simple, c'est une forme de chargement paresseux). Supprimer l'inclusion des classes inutiles réduit la charge de travail de PHP.
Au sein de Zend
Framework, il y a une légère complication, dans le sens que la
fonctionnalité d'autoloading la plus utilisée est fournie par
Zend_Loader. Zend_Loader a
son propre agenda mystérieux qui exige qu'elle effectue des
vérifications de fichiers supplémentaires et d'autres opérations sur
tous les auto-chargements. En dehors de quelques cas particuliers,
toutes celles-ci sont complétement superflues et inutiles.
A partir de Zend Framework 1.8.0,
Zend_Loader::autoload() est devenu une
fonctionnalité dépréciée, ce qui signifie que vous ne devriez plus
l'utiliser dans de nouveaux projets, et que vous devriez sérieusement
envisager de la remplacer par la nouvelle solution
Zend_loader_Autoloader avant la sortie de Zend
Framework 2.0.
Utiliser Zend_Loader peut être utile, d'une
certaine façon, mais puisque Zend Framework respecte la convention PEAR,
qui est des plus prévisibles, ce qui suit fonctionne tout aussi bien, et
évite les opérations de vérification plus coûteuses de
Zend_Loader :
function __autoload($path) {include str_replace('_','/',$path) . '.php';return $path;}
Vous pourriez aussi utiliser ceci sous forme d'une méthode statique pour votre classe de Bootstrap :
class ZFExt_Bootstrap{// ...public static function autoload($path){include str_replace('_','/',$path) . '.php';return $path;}// ...}
Une fonction de quatre lignes ou une classe... Encore une fois, de David et Goliath, qui a gagné ? Notons tout de même que certaines bibliothèques externes auront besoin d'un traitement spécifique si elles ne respectent pas la convention PEAR.
Avec Zend Framework 1.8 et les versions suivantes, une nouvelle
solution nommée Zend_Loader_Autoloader existe,
dont les fonctionnalités méritent que vous l'adoptiez, même si elle
semble plus complexe que le simple remplacement d'autoload que je viens
de décrire. Malgré la complexité de cette nouvelle classe, vous pouvez
toujours gagner en performances en apportant une simple modification sur
la façon dont Zend_Loader_Autoload::autoload()
fonctionne. C'est possible parce que cette nouvelle classe permet aux
développeurs de remplacer l'autoloader par défaut, qui est
Zend_Loader::loadClass(), par une version plus
légère pour éviter toutes les vérifications de fichiers qui sont
généralement inutiles. Notez que si vous utilisez
Zend_Application, cela doit être fait avant le
bootstrapping, ce qui signifie dans
index.php.
$autoloader = Zend_Loader_Autoloader::getInstance();$autoloader->setDefaultAutoloader(array('ZFExt_Bootstrap', 'autoload'));
Utiliser de
l'autoloading n'évitera pas l'impact de toutes ces instructions
require_once dans le code source de Zend Framework
lui-même. Pour maximimer les gains de l'auto-chargement, supprimer
toutes les occurences de require_once des fichiers de
classes n'est pas une mauvaise idée. Vous pouvez effectuer ceci dans une
tâche Phing, depuis la ligne de commandes, ou à l'aide de n'importe quel
script PHP, que vous lancerez sur une copie de Zend Framework.
Depuis la ligne de commande, vous pouvez commenter ces appels en utilisant :
cd path/to/ZendFramework/library find . -name '*.php' -not -wholename '*/Loader/Autoloader.php' -print0 | \ xargs -0 sed --regexp-extended --in-place 's/(require_once)/\/\/ \1/g'
Au sein du Framework,
quelques classes impliquent des opérations coûteuses. Par exemple,
Zend_Db_Table lance une requête DESCRIBE
TABLE en arrière-plan à chaque fois que vous créez une nouvelle
instance d'un de ses types. Considérant que vous pourriez utiliser au
moins quelques unes de celles-ci à chaque chargement de page, ces
requêtes supplémentaires vont vite devenir nombreuses. Un autre exemple
est Zend_Translate, qui va en permanence
ré-analyser les sources de traductions lorsqu'il sera utilisé.
Heureusement, ces deux composants vous permettent de définir un cache, donc, pour éviter de vous sentir bête à l'avenir, assurez-vous de les avoir configurés.
Pour
Zend_Db_Table, vous pouvez définir un cache par
défaut en passant une instance de Zend_Cache à la
méthode
Zend_Db_Table_Abstract::setDefaultMetadataCache().
Zend_Translate offre la même fonctionnalité en
utilisant Zend_Translate::setCache(), tout
comme Zend_Locale utilise
Zend_Locale::setCache(). Tout ceci peut être
configuré depuis votre bootstrap, pour que ces caches soient disponibles
pour toutes les requêtes.
En optimisation des performances, cacher est important, puisque cela peut signifier des gains significatifs de performance en cachant les résultats d'opérations coûteuses pour une période de temps donnée. Cependant, savoir quand mettre en cache lève aussi la question de où mettre en cache.
Prenez l'exemple d'une page dynamique où les éléments dynamiques (peut-être une liste des nouveautés les plus récentes, mise à jour une fois par heure) ne changent pas trop souvent. L'idée la plus évidente est de mettre en cache les données dynamiques pour les nouveautés les plus récentes (au sein d'un Modèle ou d'une aide de Vue, éventuellement). Puisque les modifications se font toutes les heures, la durée de vie du cache serait aux environs de 3600 secondes. Maintenant, les éléments dynamiques ne sont plus mis à jour à partir des nouvelles données que toutes les heures. Cela dit, pour utiliser ce cache, nous devons encore appeler l'application, qui lancera la génération de la Vue qui utilise le cache : chaque requête lance encore l'application, comme précédemment.
Est-ce vraiment
nécessaire ? Si les seuls éléments dynamiques de la page sont mis à jour
une fois par heure, pourquoi ne cacherions-nous pas la page entière pour
la durée de cette heure ? Vous pouvez effectuer de la mise en page de
cache depuis votre Bootstrap en utilisant
Zend_Cache :
<?phpclass ZFExt_Bootstrap{// ...public function run(){$this->setupEnvironment();/*** Implement Page Caching At Bootstrap Level*/$this->usePageCache();$this->prepare();$response = self::$frontController->dispatch();$this->sendResponse($response);}public function usePageCache(){$frontendOptions = array('lifetime' => 3600,'default_options' => array(// disable default caching for all requests'cache' => false),// cache routes to Index and News controllers'regexps' => array('^/$' => array('cache' => true),'^/news/' => array('cache' => true)));$cache = Zend_Cache::factory('Page','Apc',$frontendOptions);// serve cached page (if it exists) and exit$cache->start();}// ...}
Mais est-ce que ce niveau de caching est suffisant ? Nous devons toujours appeler PHP pour le Bootstrap et effectuer au moins un peu de travail, et cela utilise un processus Apache au passage. En fait, la solution de mise en cache la plus rapide serait de cacher ces pages dynamiques pour une heure sous forme de fichiers HTML statiques qui n'ont pas besoin de PHP, et qui, avec une installation utilisant un reverse proxy, peuvent complétement éviter de passer par Apache et être servies par une alternative plus légère, comme lighttpd ou nginx. Bien sûr, puisque les requêtes n'atteignent jamais l'application ni le bootstrap, expirer les caches devient un peu plus compliqué !
Avec ou sans cache
statique physique, une pratique complémentaire serait de déléguer une
partie du cache au client, via l'utilisation d'en-têtes
Etag et Last-Modified. Bien qu'utiles lorsque
vous avez beaucoup de visiteurs qui reviennent régulièrement, ce n'est
pas une solution aussi efficace que la mise en cache de HTML statique
lorsque des visiteurs uniques ou non-réguliers sont la norme.
Cette discussion illustre le fait que, alors que nous déployons des systèmes de cache à travers une application, il est important d'identifier où cette mise en cache peut être utilisée pour apporter le plus grand bénéfice. Rappelez-vous que l'objectif, lorsque l'on utilise du cache, est d'éviter des calculs et utilisations mémoire inutiles ; plus les caches sont proches des couches externes de l'application, plus il y a de chances de nous évitions des traitements.
Dans une application
Zend Framework typique, vous pouvez vous attendre à trouver des classes
un peu partout. Il n'est pas inhabituel d'utiliser des classes depuis
tellement d'emplacements différents que votre include_path
fini par ne plus ressembler à grand chose. Cela a un impact sur les
performances, puisqu'à chaque fois que vous incluez une classe (que ce
soit directement ou via une fonction d'autoload) en utilisant un chemin
relatif, PHP doit rechercher un fichier correspondant en itérant à
travers chacun des chemins enregistrés dans
l'include_path.
Puisque ceci n'est pas désirable, voici deux règles simples à appliquer.
Tout d'abord,
minimisez vos chemins d'inclusion. Lorsque c'est possible, installez les
bibliothèques et même Zend Framework dans des répertoires partagés.
Puisqu'un grand nombre de bibliothèques PHP 5 ont adopté la convention
PEAR, cela ne devrait pas poser de problème. L'exception sera lorsque
vous utilisez des bibliothèques via, par exemple,
svn:externals sous Subversion, lorsque la bibliothèque
externe a des fichiers dans son répertoire de plus haut niveau. Un
exemple d'exception de ce type est HTMLPurifier, qui a des fichiers au
même niveau que le répertoire HTMLPurifier.
Mais, au-delà de ces
quelques exceptions, gardez autant que possible les bibliothèques dans
un répertoire partagé. Ainsi, plutôt que d'avoir dix millions d'entrées
dans votre include_path, vous pouvez rester à une liste
plus efficace, contenant entre 2 et 4 emplacements au maximum.
La seconde règle est de vous assurer que les chemins les plus fréquemment utilisés sont au début de la liste de répertoires d'inclusion. Cela assure qu'ils seront trouvés plus rapidement, et que parcourir les autres emplacements possibles n'est fait que pour les classes plus rarement utilisées.
Peu importe à quel point vous optimisez votre application, un jour ou l'autre, votre serveur arrivera à sa limite en terme de traffic qu'il est capable de gérer. Un des facteurs qui a tendance à être le plus limitant sur un serveur est la quantité de mémoire disponible. Au fur et à mesure que le traffic de votre application augmente, de plus en mémoire sera consommée par les processus Apache et MySQL, jusqu'à ce que le serveur n'ait d'autre possibilité que de commencer à utiliser du swap sur disque.
Utiliser l'espace de swap est incroyablement lent (en fait, toutes les opérations disques sont coûteuses par rapport à l'utilisation de la RAM), et l'éviter autant que possible est fortement souhaitable. Avoir des processus Apache dépendant du swap, ou, pire, avoir un processus Apache père qui crée ses enfants depuis le swap, peut ralentir votre application à un point qui ne se traduira pas par une bonne expérience utilisateur. Ceci est tout particulièrement vrai pour les applications Ajax, où une interface utilisateur réactive est extrêmement importante.
La solution la plus évidente qui soit pour ces problématiques serveur est tout simplement d'investir dans plus de matériel pour résoudre le problème ; c'est un procédé nommé scaling ("mise à l'échelle"). Vous pourriez augmenter la quantité de RAM, ou obtenir un serveur plus puissant (scaling vertical) ou utiliser plusieurs serveurs pour répartir la charge (scaling horizontal). Cela dit, avant que vous ne vous lanciez prématurément dans une mise à l'échelle dans un sens ou dans l'autre, il est toujours important de faire le meilleur usage qui soit des ressources serveur à votre disposition, pour minimiser les dépences en nouveau matériel. Oui, l'optimisation vous permet de réaliser des économies, en même temps qu'elle rend vos utilisateur satisfaits.
En examinant Apache, notre serveur HTTP, il y a plusieurs points qui méritent notre attention. Le fichier de configuration d'Apache, un éternel mystère pour de nombreux développeurs, est là où beaucoup de problèmes liés à la gestion de la mémoire trouvent leur origine. Le problème est qu'Apache a tendance à aimer disposer d'une bonne quantité de mémoire, et ne s'en laisse pas priver sans combattre. L'autre problème est qu'Apache, bien qu'étant un serveur rapide à très grand succès, a des concurrents plus agiles qui nécessitent nettement moins de mémoire (hérésie !).
Une stratégie où nous configurons à la fois Apache pour qu'il soit aussi bon que possible compte-tenu des ressources serveur disponible, et où nous le contournons lorsqu'il n'est pas réellement nécessaire, peut mener à des améliorations conséquentes au niveau des performances. Il existe aussi deux autres facteurs : le premier est de laisser les clients garder du contenu en cache, et l'autre est un effet secondaire de la marche vers les systèmes d'exploitation 64 bits. Commençons par la configuration avant que je ne me retrouve encerclé par des gens portant des torches enflammés et des fourches.
Une vérité de base d'Apache est que votre serveur ne peut efficacement supporter que le nombre de processus enfants qui peuvent tenir en mémoire. Typiquement, un serveur mal configuré permettra à beaucoup trop (ou pas assez) de processus Apache enfants de tourner sans contrôle, utilisant tellement de mémoire que la rencontre avec l'espace de swap sera inévitable. Fixer une limite sur le nombre de processus Apache fils, et garder un oeil sur la consommation mémoire toujours croissante permettra à votre serveur de fonctionner le plus efficacement possible, sans l'envoyer creuser sa tombe prématurément lorsque l'effet Digg viendra frapper à sa porte.
Malheureusement, il n'existe pas de modèle parfait pour la configuration d'Apache. Certains serveurs ont plus de mémoire que d'autres, ou passent plus de temps à servir des fichiers statiques que des contenus dynamiques. Votre configuration devra être ajustée et testée (nous avons parlé de Apache Bench et de Siege plus haut) en fonction du profil de votre propre application, et des logiciels déployés sur votre serveur. Les points cités ci-dessous sont des suggestions ouvertes sur les directions dans lesquelles regarder lorsque vous commencez.
Pour ce qui est de la
gestion de la mémoire, les options de configuration les plus importantes
sont StartServers, MinSpareServers,
MaxSpareServers, MaxClients, et
MaxRequestsPerChild. Puisque PHP fonctionne souvent sous
Apache en mode prefork, chaque requête reçue par le serveur nécessite un
processus fils. Heureusement, les processus enfant peuvent rester
disponibles et servir plusieurs requêtes (ce qui signifie moins
d'attente pour que de nouveaux soient lancés). Cela signifie que chaque
enfant passe du temps à attendre, en occupant une certaine quantité de
mémoire. Pour faire simple, donc, si votre serveur a suffisament de
mémoire (après avoir pris en compte les autres processus comme MySQL,
ssh, ...) pour que 40 processus Apache puissent exister sans commencer à
swapper (directive MaxClients), vous devriez vous assurer
de ne jamais en avoir plus que cela.
Calculer combien de clients autoriser n'est pas forcément évident. Le calcul simple est le suivant :
Ca peut être un calcul qui se fait rapidement, mais Apache consomme de la mémoire différemment en fonction des scénarios. Une requête simple basée sur Zend Framework peut consommer entre 17 et 20 Mo par processues (ce qui correspondrait à 40 processus pour un serveur avec 1 Go de RAM, dont 800 seraient considérés comme disponibles pour Apache). Servir une page statique ou cachée consommerait nettement moins, de l'ordre de 2 à 4 Mo par processus. Ajuster la configuration d'Apache signifie avoir quelques idées sur la façon dont les visiteurs utilisent l'application, à quelle fréquence les pages cachées sont demandées par rapport aux pages dynamiques, et quel niveau de cache est employé (total ou partiel).
A vous de configurer
les options citées plus haut, en monitorant l'utilisation mémoire
(éventuellement, en utilisant un mix entre top,
free, ou l'excellent htop) et en
effectuant quelques attaques avec Apache Bench et Siege, en commençant
par des valeurs modestes (générallement, par défaut après installation).
En vous basant sur le niveau d'utilisation mémoire obtenu, vous pouvez
commencer à ajuster pour autoriser plus ou moins de processus fils au
total (MaxClients) tout en variant les nombres de départ
(StartServers, MinSpareServers).
MaxRequestsPerChild est généralement initialisée avec une
valeur assez élevée, mais vous pouvez envisager de la diminuer si les
processus fils commencent à grossir d'un point de vue utilisation
mémoire au bout d'un certain temps ; réglez cette option à une valeur
qui tue les processus fils s'ils commencent à trop grossir : son but,
après tout, est de combattre les éventuelles fuites mémoire.
Assurez-vous que la valeur de configuration ServerLimit
reste plus élevée que MaxClients.
Voici une capture d'écran montrant htop au travail (bien plus joli que top, avec pas mal de fonctionnalités interactives).
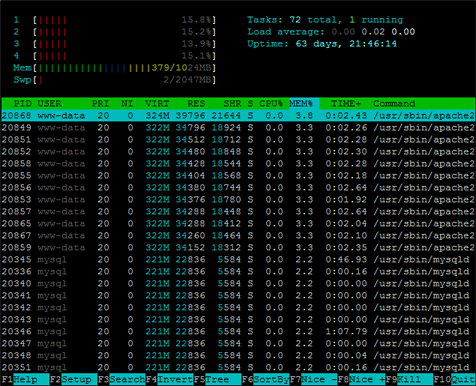
D'autres points
auxquels vous devriez prêter attention incluent KeepAlive
et KeepAliveTimeout. Assurez-vous qu'ils soient activés,
puisqu'ils permettent aux clients de réutiliser les connexions pour
plusieurs requêtes HTTP. Bien entendu, si votre client n'a pas besoin
d'effectuer beaucoup de requêtes supplémentaires,
KeepAliveTimeout devrait être configuré à une valeur qui
empêche les connexions de rester actives trop longtemps lorsqu'elles
pourraient être affectées à d'autres clients en réclamant votre
attention. Commencer avec une valeur de 2 pour
KeepAliveTimeout est généralement suffisant. Certains sites
web avec du code HTML optimisé se comportent même encore mieux lorsque
cette directive est désactivée ou configurée à 1.
Vient ensuite un point
que l'on retrouve chez tout le monde : les fichiers
.htaccess. Si vous contrôlez vos propres Virtual
Hosts, vous devriez envisager de déplacer les directives présentes dans
vos fichiers .htaccess vers le conteneur
Directory approprié de httpd.conf ou
du fichier externe de vhosts. Cela évitera à Apache d'avoir à sans cesse
analyser les fichiers .htaccess.
Mes derniers mots sont
réservés pour le module mod_expire de Apache, qui contôle
les en-têtes HTTP Expire et Cache-Control. Ces
en-têtes indiquent aux clients qu'ils doivent cacher le contenu
statique, et ne pas prendre la peine de les demander à nouveau au
serveur jusqu'à ce qu'ils aient... expiré ! C'est utile pour les images,
CSS, javascript, et autres contenus statiques. Les options de
configuration d'Apache pour ceux-ci peuvent être définies au niveau du
serveur, d'un Virtual Host, ou au niveau d'un Directory, ce
qui permet une configuration précise. Son utilité réside dans le fait de
réduire le nombre de requêtes que les clients effectuent : moins de
requêtes signifie laisser de la mémoire et du CPU libre pour servir les
autres.
Voici un exemple qui concerne les fichiers CSS : il ajoute les en-têtes HTTP pour que les fichiers servis depuis le répertoire donné expirent 30 jours (2592000 secondes) après la date de modification (M) de chaque fichier :
<Directory /home/mrweb/public_html/example.com/css>
ExpiresActive On
ExpiresByType text/css M2592000
</Directory>
Après optimisation,
vous pourrez remarquer que vous avez toujours l'impression d'être aux
environs de 35 à 40 requêtes par seconde, avec autant de processus
Apache que la mémoire peut en contenir, mais htop ou
free insistent sur le fait qu'il vous reste de la
mémoire libre inutilisée même avec Apache Bench en train d'attaquer
votre serveur. Malheureusement, des fois, votre capacité mémoire dépasse
largement la capacité de votre CPU à répondre, créant un goulot
d'étranglement. Il n'y a pas vraiment grand chose que vous puissiez
faire dans cette situation sans investir dans plus de puissance CPU,
sauf peut-être vous assurer que votre application est optimisée pour ce
qui est de l'utilisation du CPU. Mettre en cache joue un rôle évident
ici. Dans ce genre de situations, j'ai tendance à commencer à déplacer
des données d'un cache disque vers des caches en mémoire (par exemple,
en utilisant les backend APC ou memcached pour
Zend_Cache). Pourquoi pas, s'il y a de la mémoire
libre dont vous pouvez profiter ? Les caches en mémoire sont très
rapides, et peuvent être utilisés pour cache le résultat d'opérations
coûteuses en CPU (même si le résultat est quelque chose de petite
taille) pour gagner encore un peu au niveau du CPU.
Parfois, vous avez juste besoin d'éviter Apache. Apache est rapide, mais il utilise beaucoup plus de mémoire, et peut être plus lent, qu'un certain nombre de solutions alternatives, comme Lighttpd et Nginx. Pour cette section, nous verrons comment utiliser Nginx en tant que reverse proxy devant Apache. Cela signifie que Nginx est utilisé comme serveur HTTP en première ligne, faisant passer toutes les requêtes pour du contenu dynamique à Apache en arrière-plan, mais gérant tout le contenu statique lui-même. Cela signifie aussi que Apache enverra tous les contenus à Nginx qui les servira aux utilisateurs, ce qui permettra à Apache de plus rapidement passer au traitement d'une autre requête.
Cette approche apporte un certain nombre d'avantages. Nginx a une occupation mémoire minimale par rapport à celle d'Apache, ce qui signifie que remplacer une utilisation d'Apache par Nginx apporte immédiatement des gains au niveau de la mémoire. Cela est particulièrement vrai lorsque nous servons du contenu statique, pour lequel Nginx est plus rapide et léger que passer par Apache. C'est aussi utile lorsque les clients lents sont fréquents. Les clients lents sont ceux qui prennent plus de temps que la normale pour terminer les requêtes de téléchargement. Pendant que le client travaille, le processus Apache continue à tourner sur le serveur, attendant plusieurs secondes que le client termine. Est-ce que vous préféreriez avec un processus qui occupe plus de 15 Mo pendant une éternité, ou, à la place, avoir Nginx et son occupation mémoire minimale qui attend, laissant le processus Apache libre de passer à une autre requête de contenu dynamique ? La réponse devrait être évidente !
En restant dans la logique Ubuntu de ce livre, installer Nginx est un simple :
sudo aptitude install nginx
Vous pouvez omettre sudo si vous travaillez en tant que root, mais, sérieusement, pourquoi auriez-vous root ne serait-ce que accessible ?
Lorsque l'on configure
un reverse proxy, il est important de prendre en compte les rôles de
Nginx et d'Apache. Apache n'écoutera plus sur le port 80, puisque Nginx
va prendre le relai en tant que serveur frontal ; nous devrions donc
modifier la configuration d'Apache pour, à la place, écouter sur un
autre port tel que 8080. Cela se fait en modifiant le fichier de
configuration principal, ou, lorsqu'il est utilisé,
ports.conf :
NameVirtualHost *:8080
Listen 8080
<IfModule mod_ssl.c>
Listen 443
</IfModule>
Vous devriez aussi modifier les configurations de vos Virtual Hosts pour utiliser aussi le port 8080 :
<VirtualHost *:8080> ServerAdmin webmaster@example.com ServerName example.com.com ServerAlias www.example.com DocumentRoot /var/www </VirtualHost>
En passant à Nginx,
nous utilisons une configuration du style Ubuntu avec un fichier de
configuration principal, et des sous-configurations pour les Hôtes
Virtuels (Les servers Nginx). Il y a un peu de duplication
ici, puisque Nginx aura souvent besoin d'un conteneur de configuration
"server" pour chaque Virtual Host Apache pour lequel nous
voulons utiliser le reverse proxy. Voici un exemple de fichier de
configuration principal, enregistré sous
/etc/nginx/nginx.conf sous Ubuntu :
# Ubuntu Intrepid
user www-data www-data;
worker_processes 2;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
use epoll;
}
http {
server_names_hash_bucket_size 64;
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log;
client_body_temp_path /var/spool/nginx-client-body 1 2;
client_max_body_size 32m;
client_body_buffer_size 128k;
server_tokens off;
sendfile on;
tcp_nopush on;
tcp_nodelay off;
keepalive_timeout 2;
# include per-server (Virtual Host) configurations for enabled sites
include /etc/nginx/sites-enabled/*;
}
Nginx a tendance à
avoir réputation de documentations obscures, puisque les textes
originaux sont tous écrits en Russe. Les traductions anglaises sont
disponibles sur http://wiki.codemongers.com/.
Vous ne trouverez ici pas de directive MaxClients, mais
l'équivalent est déterminé par la multiplication des options
worker_processes et worker_connections. La
documentation traite des autres options citées ici, et certaines
sembleront familières pour un utilsateur ayant déjà travaillé avec
Apache.
A la fin de ce fichier
de configuration, ou dans un fichier séparé placé dans le répertoire
/etc/nginx/sites-enabled/, vous pouvez créer des
configurations par serveur. Celles-ci sont proches de ce que nous
mettons en place pour la configuration des Virtual Hosts Apache :
server {
listen 80;
server_name example.com www.example.com;
# Default Gzip Configuration (Set Exceptions Per Location)
gzip on;
gzip_comp_level 2;
gzip_proxied any;
gzip_types text/plain text/html text/css text/xml application/xml application/xml+rss \
application/xml+atom text/javascript application/x-javascript application/javascript;
# Handle Static Content Here
location ~* ^.+\.(jpg|jpeg|gif|png|ico)$ {
root /var/www;
access_log off;
gzip off;
expires 30d;
}
location ~* ^.+\.(css|js)$ {
root /var/www;
access_log off;
expires 1d;
}
location ~* ^.+\.(pdf|gz|bz2|exe|rar|zip|7z)$ {
root /var/www;
gzip off;
}
# Proxy Non-Static Requests to Apache
location / {
# Proxy Configuration
proxy_pass http://your-servers-ip:8080/;
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_max_temp_file_size 0;
client_max_body_size 10m;
client_body_buffer_size 128k;
proxy_connect_timeout 90;
proxy_send_timeout 90;
proxy_read_timeout 90;
proxy_buffer_size 4k;
proxy_buffers 4 32k;
proxy_busy_buffers_size 64k;
proxy_temp_file_write_size 64k;
}
}
![[Attention]](images/docbook/caution.png)
La configuration du
server pointe vers le même document root que le Virtual
Host Apache que nous utilisions précédement. Pensez à ceci comme à un
filtre et une passerelle. La toute première partie de la configuration
de notre server définit la compression des contenus comme
utilisant gzip par défaut. J'ai ajouté trois conteneurs
location qui utilisent des expressions rationnelles pour
intercepter les requêtes sur des types de contenus spécifiques.
Lorsqu'ils sont détectés, ceux-ci seront servis directement par Nginx
sans aller déranger Apache. En fonction du type de fichier, j'ai aussi
indiqué à Nginx s'il devait ou non gzipper le contenu, et quel en-tête
Expires indiquer (si nécessaire). Ces trois conteneurs
permettent de s'assurer que Apache n'aura jamais besoin d'utiliser de la
mémoire, coûteuse, pour du contenu statique que Nginx peut
servir.
Le quatrième et
dernier conteneur location affecte tout ce que les
conteneurs précédent n'ont pas géré, c'est-à-dire les contenus
dynamiques et les fichiers statiques que les expressions rationnelles de
Nginx n'auront pas pris en compte. Ici, nous configurons Nginx pour
qu'il transmette la requête vers le port 8080 du serveur local, où
Apache écoute. Une fois qu'Apache a terminé la requête, la réponse est
immédiatement renvoyée à Nginx (ce qui laisse Apache libre de faire
autre chose) qui la prendra en charge.
Nous avons vu toute une série d'astuces d'optimisations pour des applications basées sur Zend Framework, et avons même jeté un coup d'oeil à quelques problématiques matérielles. Il y a sans aucun doute beaucoup d'autres idées d'optimisations que nous n'avons pas mentionné ici, puisqu'il s'agit, comme vous pouvez le voir, d'un vaste domaine.
Le message principal à retenir de cette annexe est que optimiser demande de mesurer les progrès effectués par rapport à un benchmark des performances de départ et à d'autres métriques. Ce n'est qu'en utilisant une méthodologie carrée que les véritables opportunités d'optimisation sont identifiées et leurs gains potentiels jugés. Perdre votre temps sur des optimisatons aléatoires n'apportant qu'un gain minimal est quelque chose qui vaut le coup d'être évité !