Intégration continue d'un projet PHP avec Jenkins
27 septembre 2011 —Cet article fait suite à Intégration continue avec Jenkins : installation et configuration de base -- et pré-suppose que vous avez installé une plate-forme d'Intégration Continue Jenkins, avec les plugins qui seront nécessaires à la mise en intégration continue d'un projet PHP.
Nous allons maintenant passer à l'utilisation de la plate-forme que nous avons installé il y a quelques jours, en la configurant pour qu'elle effectue l'intégration continue d'un projet PHP.
Oh, et, avant de commencer : si vous cherchez juste des fichiers de configuration << quasi tout-fait >> pour Jenkins + PHP et n'êtes pas intéressés par un guide << étape par étape >>, vous devriez faire un tour là : Template for Jenkins Jobs for PHP Projects ;-)
Sommaire :
- Intégration Continue d'un projet PHP ?
- Un projet PHP ?
- Un job Jenkins pour notre projet PHP
- Script de construction : build.xml
- Publier les résultats du build
- Et maintenant ?
(Ne prenez pas peur en regardant la taille de l'ascenceur affiché par votre navigateur : sans les nombreuses captures d'écrans, cet article n'est finalement pas si long)
Intégration Continue d'un projet PHP ?
Je disais dans l'article précédant celui-ci qu'un des principes de l'Intégration Continue est de vérifier, à chaque modification du code-source d'une application, que le résultat de cette modification ne produit pas de régression sur l'application en question.
Outils d'analyse PHP
Cela implique donc la mise en place d'outils capables d'analyser une application et son code-source, afin de produire différents rappors de qualité -- que ce soit au niveau de la qualité du code-source, ou au niveau de la qualité / stabilité de l'application.
Dans le monde PHP, les outils les plus fréquemment utilisés pour chaque type d'analyse sont les suivants :
- Test Unitaires : PHPUnit
- On pourrait aussi entendre parler de SimpleTest, mais, depuis des années, n'est plus vraiment un projet vivant
- Ou de Atoum qui, bien que prometteur, n'est pas encore très répandu.
- Vérification du respect des normes de codage : PHP_CodeSniffer
- Dépendances entre composants : PHP Depend
- PHP Mess Detector pour la remontée de statistiques susceptibles de mettre en évidence des portions de code-source de qualité médiocre
- phpcpd pour la détection de portions de code copié-collé (portions qui devraient souvent être factorisées)
- phploc pour la collecte de statistiques du type nombres de méthodes, nombres de classes, nombres de lignes de code, ...
- Génération de documentation d'API :
- Historiquement parlant, on pensera tout de suite à phpDocumentor (qui n'est plus tellement vivant, et a quelques difficultés avec PHP >= 5.3)
- Ou on se penchera plutôt vers phpdox, pour PHP >= 5.3, qui semble prometteur.
- Et enfin, pour intégrer un navigateur de code à Jenkins, qui prenne en compte une partie des résultats issus d'outils cités ci-dessus, nous penserons à PHP_CodeBrowser.
Sans entrer dans les détails, la série de commandes suivantes devrait permettre d'installer le plus gros de ces outils -- notez que cette liste est extraite d'un script d'installation que je joue sur à peu près toutes mes machines de développement PHP, et contient donc quelques outils / bibliothèques que nous n'utiliserons pas par la suite :
# Mise à jour des extensions PEAR déjà installées
sudo pear upgrade-all
sudo pear config-set auto_discover 1
# Installation de quelques extensions supplémentaires (pas forcément toujours utilisées, mais suffisament "souvent" pour que je les installe "par défaut")
sudo pear config-set preferred_state beta
sudo pear install --alldeps PHP_CodeSniffer PhpDocumentor php_CompatInfo Log Text_Diff HTML_QuickForm2 Image_GraphViz MDB2 Mail_Mime PHP_Beautifier-beta SOAP XML_Beautifier XML_RPC Structures_Graph components.ez.no/Graph VersionControl_SVN-alpha Horde_Text_Diff XML_RPC2 VersionControl_Git-alpha
# PHPUnit
sudo pear channel-discover pear.phpunit.de
sudo pear install --alldeps phpunit/PHPUnit
# Autres outils "QA"
sudo pear channel-discover pear.pdepend.org
sudo pear channel-discover pear.phpmd.org
sudo pear install pdepend/PHP_Depend
sudo pear install phpmd/PHP_PMD
sudo pear install phpunit/phpcpd
sudo pear install phpunit/File_Iterator
sudo pear install phpunit/phploc
sudo pear install --alldeps phpunit/PHP_CodeBrowser
# DocBlox (en alternative plus récente (et compatible PHP 5.3) à PhpDocumentor)
sudo pear channel-discover pear.docblox-project.org
sudo pear install --alldeps docblox/DocBlox(Pour les scripts d'installation de machine de développement PHP dont je parlais juste au-dessus, vous pouvez jeter un coup d'oeil à https://github.com/pmartin/vm-dev-php/)
<< Builder un job >>
Avec Jenkins, l'Intégration d'un projet passe par un job : c'est ce job qui définira tout le processus d'intégration de votre application :
- Extraction des sources depuis votre système de gestion de versions,
- Opérations de construction -- en particulier, lancement des outils d'analyse de qualité que nous avons vu plus haut,
- Et publication des résultats de cette construction.
Chaque construction de votre application, idéalement, après chaque commit d'une modification, est appelée un build -- et, par extension, lorsque Jenkins exécute un build de votre application, celle-ci sera buildée.
Jenkins vous permettra alors, pour chaque job, de consulter l'historique des builds, ou de déclencher un nouveau build.
Automatisation du process de build
Bien entendu, le processus de build est piloté par un outil d'automatisation : vous configurez le build, et celui-ci sera rejoué à l'identique à chaque construction, ce qui permettra de comparer les builds, d'avoir un historique cohérent, et de mesurer l'évolution du projet.
Jenkins étant un outil JAVA, c'est, par défaut, le programme Ant qui est utilisé pour le processus de build.
Pour faire super-simple, Ant prend en paramètre un fichier XML définissant des tâches à effectuer, et les lance les unes à la suite des autres, tant qu'aucune n'a échoué.
Ces tâches peuvent être fort simples, comme << effacer un fichier >>, plus complexes, comme << lancer une commande >>, voire même correspondre à du code personnalisé, répondant aux attentes d'un programme spécifique ou d'un besoin propre à votre projet.
Phing comme outil d'automatisation
Pour ma part, je trouve dommage, dans le cadre d'un projet PHP, d'utiliser l'outil Ant ; et j'ai tendance à lui préférer Phing, qui se veut être un clone de Ant, en PHP.
Avec, au minimum, trois avantages majeurs pour Phing :
- Puisqu'il s'agit d'un programme développé en PHP, il peut être utilisé sur une machine sans VM JAVA -- votre poste de développement, ou votre serveur de production, par exemple,
- Il fourni en standard plusieurs tâches correspondant à certains des outils PHP que nous avons vu plus haut,
- Et il est extensible en PHP : libre à vous de développer toute nouvelle tâche dont vous auriez besoin[1].
Si besoin est, l'installation de Phing est des plus simples -- via pear, bien entendu :
# Phing
sudo pear channel-discover pear.phing.info
sudo pear install --alldeps phing/phingAu cas où vous ne l'auriez pas encore deviné, notez que, pour la suite de cet article, j'utiliserai Phing comme outil de build -- et pas Ant.
Un projet PHP ?
Pour les besoins de cet article, je travaillerai avec un mini-projet PHP d'exemple, avec SVN comme système de gestion de versions, à l'URL suivante : https://svn.myserver/test-repository/trunk.
Note : ce projet étant en pleine phase de développement, c'est le trunk que nous placerons en Intégration Continue ; mais il va de soit qu'au fur et à mesure que de nouvelles branches seront crées, nous ajouterons de nouveaux jobs à notre plate-forme d'IC, correspondant à celles-ci.
Pour ce qui est des sources du projet en lui-même, elles sont plutôt minimalistes, et correspondent à l'arborescence suivante :
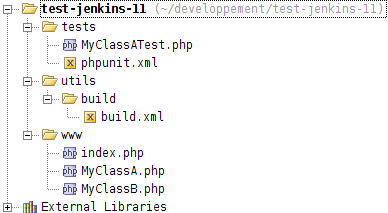
Pour faire simple :
- L'application web que nous développons se trouve sous
www, - Le répertoire
utilscontiendra les différents scripts utilitaires -- dont le script Phing correspondant au processus de build :build.xml, - Et nos tests automatisés ont tout naturellement leur place sous
tests.
Un job Jenkins pour notre projet PHP
Maintenant que nous avons un projet PHP, sur son système de gestion de versions, passons à sa mise en Intégration Continue sous Jenkins.
Vous vous souvenez peut-être qu'à la fin de l'article Intégration continue avec Jenkins : installation et configuration de base, après que nous nous soyons identifiés, Jenkins nous proposait de << créer un nouveau Job >> ?
Et bien, c'est le moment ou jamais ;-)
Initialisation du job
La première étape est de spécifier le nom de notre job ; et de choisir de quel type il sera :
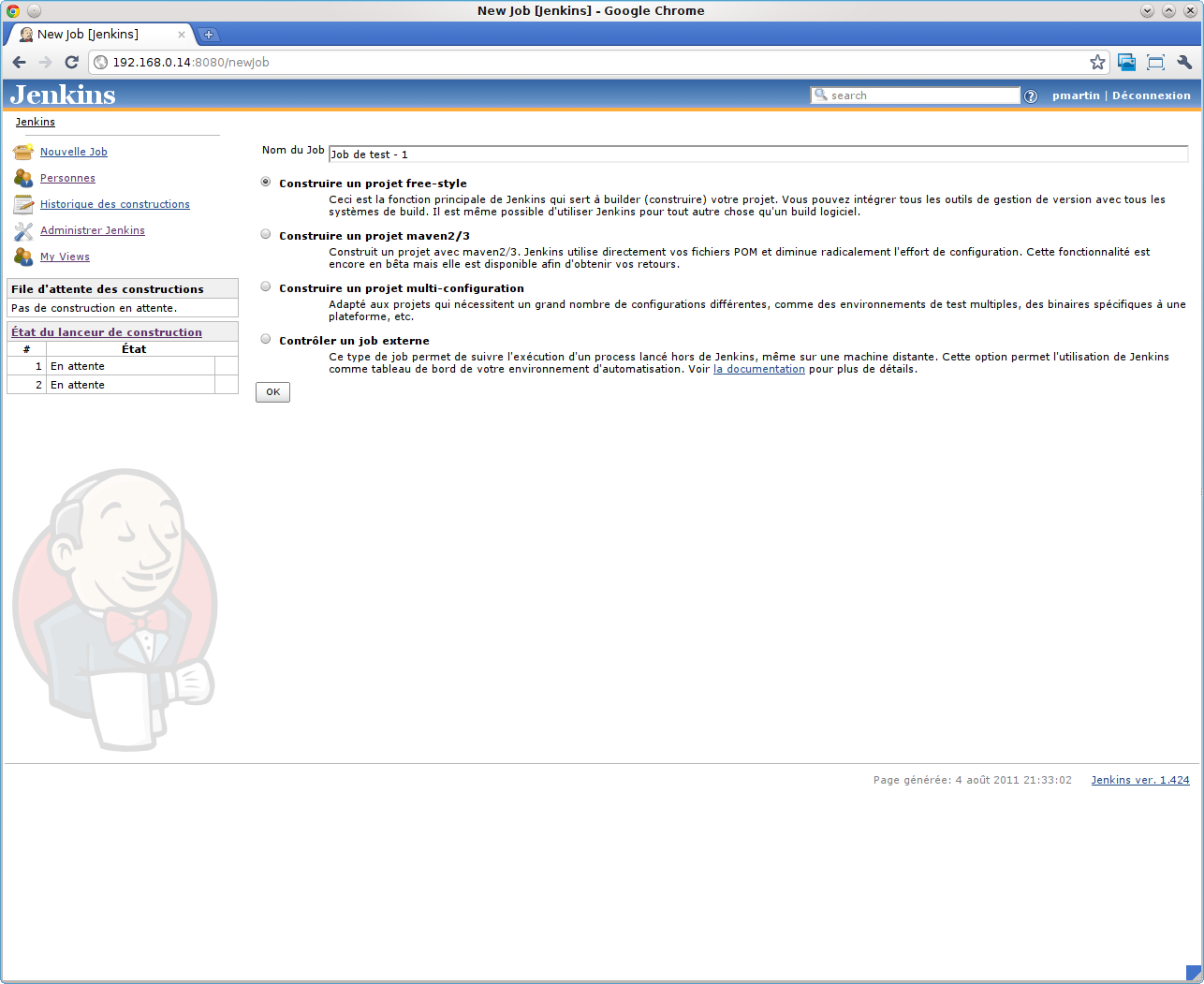
Dans le cadre d'un projet PHP, où nous gérerons nous-même le processus de Build (via un script Phing dans mon cas, ou un script Ant dans le cas par défaut), c'est la première option que nous choisissons : << Construire un projet free-style >> ; cela nous laissera toute liberté sur la configuration, tout en étant suffisant pour la plupart des projets.
Une fois cet écran renseigné, vous arriverez sur la page de configuration de votre job -- celle où vous allez pouvoir le paramétrer, indiquer à Jenkins quel script Phing est à utiliser pour construire votre projet, et quels types de rapports doivent être publiés :
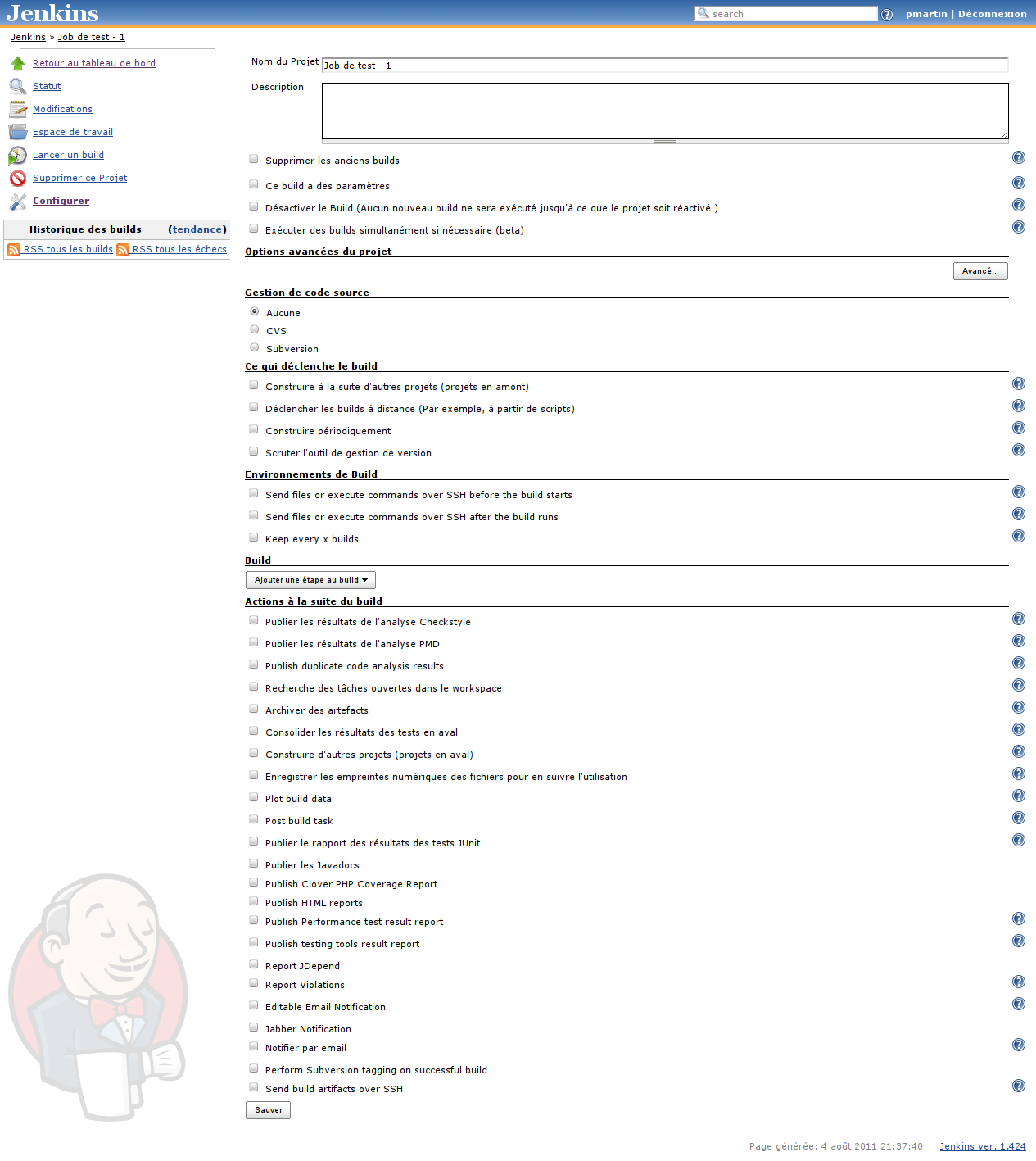
Comme vous pouvez déjà le constater, cette page est un peu longue -- et encore, de nombreuses options sont masquées, leurs blocs étant repliés ; dans les faits, cet écran peut vous demander un peu de temps avant que vous ne l'ayez vraiment pris en main... N'hésitez donc pas à le parcourir, en cliquant sur les nombreux boutons << Aide >> figurant à côté de quasiment chaque option.
En fonction de l'espace disque dont vous disposez sur votre serveur d'intégration, ainsi que de la taille de chacun des builds de votre projet (généralement assez faible, lors de la mise en place d'une plate-forme d'IC au début d'un projet ; mais elle peut rapidement augmenter), vous ne pourrez probablement pas conserver l'ensemble de l'historique des builds...
Vous tirerez donc certainement parti de la fonctionnalité de suppression des anciens builds :
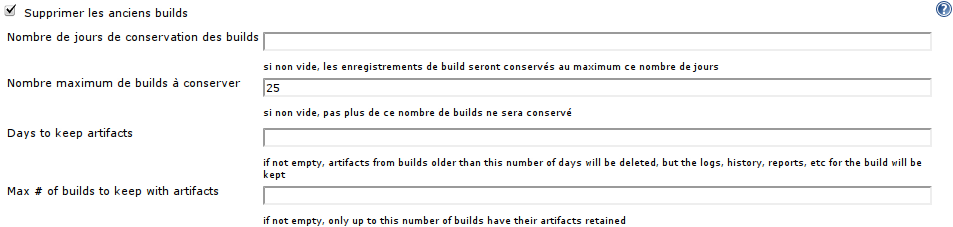
Tout en sachant que :
- Il est intéressant de conserver un certain nombre de builds, afin d'avoir un peu d'historique sur le projet, et de pouvoir mesurer les progrès accomplis,
- Vous pourrez indiquer manuellement, pour certains builds particulièrement intéressants, qu'ils devront être conservés sans limite de temps
- Vous aurez la possibilité un peu plus loin, gràce aux plugins que nous avons installés, d'indiquer à Jenkins qu'il doit conserver un build de temps en temps :
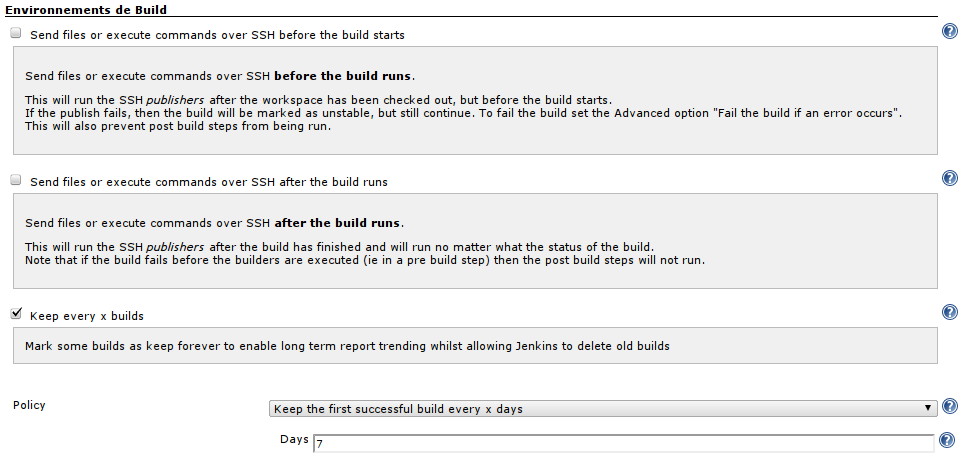
(Cette option se trouve plus bas sur la page de configuration -- mais j'en parle ici, afin que tout ce qui est << nettoyage et conservation des anciens builds >> soit regroupé)
Au passage, notez que, si besoin est, Jenkins vous permet de désactiver un job :

Je vois deux cas où ceci est utile :
- Lorsque vous savez que les modifications que vous allez faire sur le code-source de votre application vont la << casser >> pendant un bon moment (au début d'une grosse phase de rework -- que vous aurez menée, pour une raison ou une autre, sur le
trunk, au lieu de passer par une branche), et que vous ne souhaitez pas importuner votre équipe avec des mails indiquant -- inutilement -- des build failed. - Lorsqu'un projet n'est plus en développement actif pendant quelques temps ; si vous avez un nombre important de jobs sur votre plate-forme d'IC, en marquer quelques uns comme inactifs permet de mieux mettre en évidence ceux qui sont utiles à un instant donné.
Accès au système de gestion de versions
L'étape suivante (placée avant le configuration d'accès au gestionnaire de versions -- ce qui peut sembler étrange) est de configurer la << Période d'attente >>.
Dit simplement : si un build est sur le point de se lancer alors qu'un commit a eu lieu très peu de temps auparavant, alors, le build sera repoussé de quelques secondes ; l'objectif étant de permettre aux développeurs de pousser leurs modifications vers le gestionnaire de versions en plusieurs commits, et d'éviter qu'un build ne se lance qu'avec la moitié des commits effectués[2].
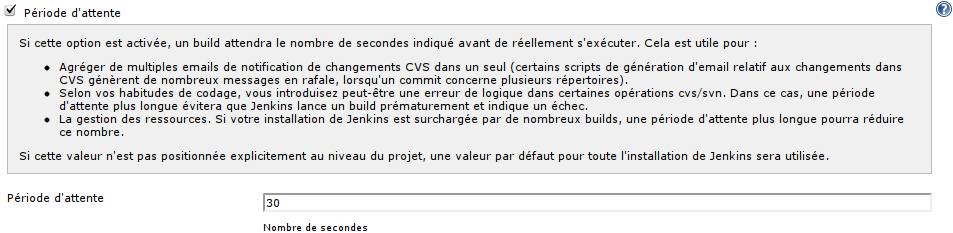
Nous pouvons maintenant passer à la configuration d'accès au système de gestion de versions -- pour ce projet, il s'agit de SVN.
Les écrans sont assez parlant, et Jenkins essaye de vous guider au maximum (par exemple : bien souvent, dès qu'un champ de formulaire perd le focus, une vérification est effectuée sur ce que vous y avez saisi), mais, dans les grandes lignes :
- Vous devez renseigner les informations d'accès à votre serveur de versions,
- Au besoin, vous devrez indiquer un couple login / password permettant à Jenkins de s'identifier, si besoin est (si votre repository ne permet pas l'accès anonyme, par exemple)
Voici à quoi peut ressembler la saisie des informations d'accès à un serveur SVN :
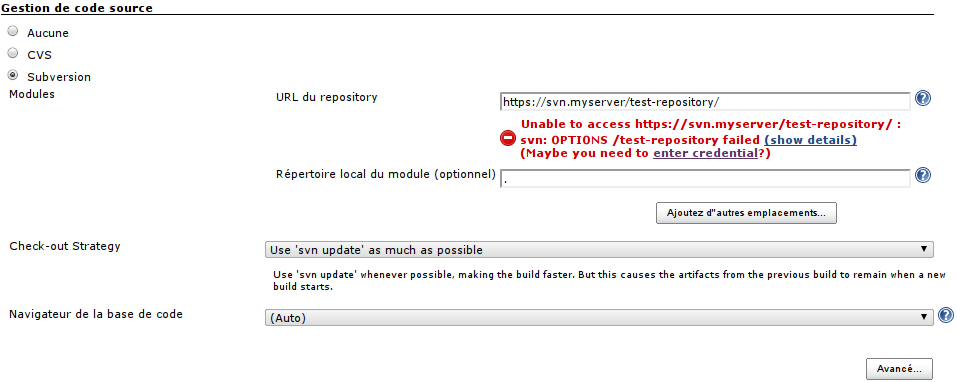
Et en cliquant sur << Enter credentials >>, vous arriverez sur le formulaire suivant :
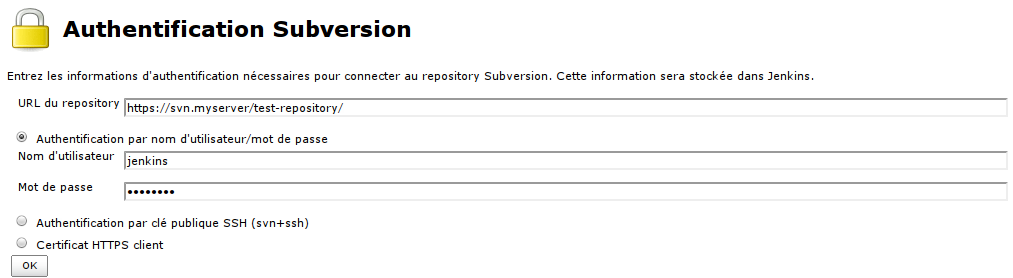
Attention tout de même : l'URL à renseigner correspond à celle du répertoire qui héberge les sources que vous souhaitez placer en intégration continue.
Autrement dit, vous ne travaillerez pas forcément à la racine du projet : il arrivera fréquemment que ce soit le répertoire trunk que vous intégrerez :
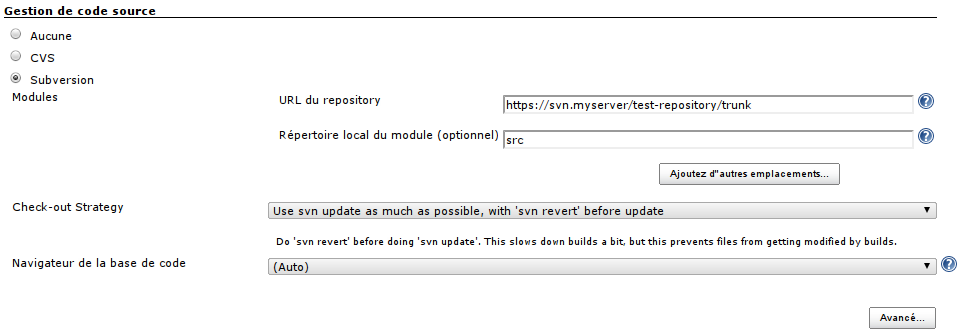
Vous noterez aussi que j'ai choisi de spécifier un nom de << répertoire local >>, que j'ai nommé src, par habitude.
De la sorte, l'extraction SVN du code-source de notre application se fera vers ce répertoire src -- et nous serons libre de travailler << à côté >> de ce src ; par exemple, notre script de build, que nous verrons plus loin, créera ses rapports d'audit de code dans un répertoire build, au même niveau que src, et sans risque d'interférer avec le contenu de celui-ci.
Une fois les informations d'identification saisies, Jenkins aura accès à votre système de gestion de sources ; et vous pourrez, au besoin, configurer quelques options supplémentaires :
Il ne reste plus qu'à indiquer à Jenkins quand construire notre projet.
Dans une logique d'Intégration Continue, le principe est généralement de scruter régulièrement le système de gestion de versions, pour déterminer si des modifications ont été apportées aux sources du projet ; et, si c'est le cas, de déclencher un build.
On aura donc souvent tendance à cocher << Scruter l'outil de gestion de version >>, et à renseigner le champ << planning >> juste en-dessous :
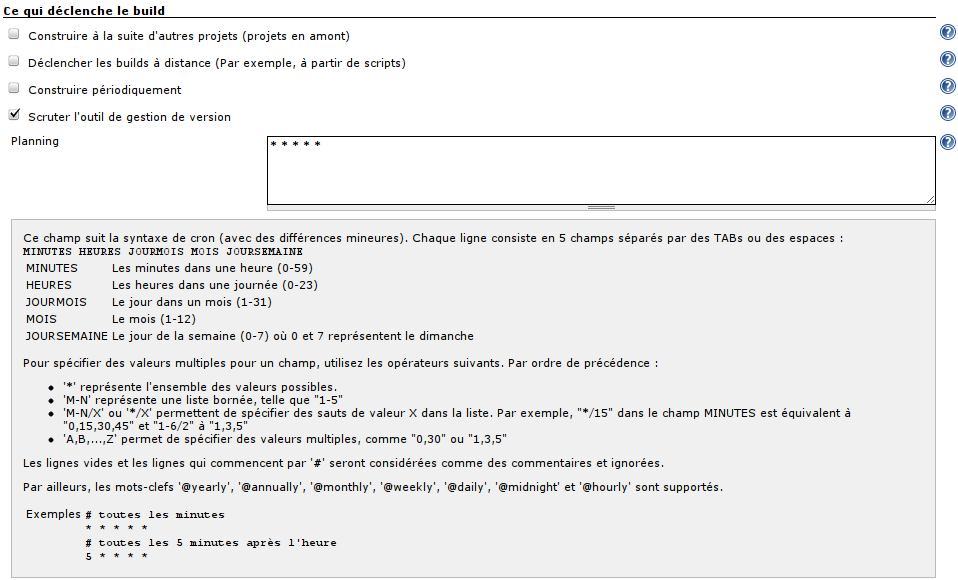
Bien sûr, en fonction de votre projet, vous pouvez spécifier autre chose que toutes les minutes de toutes les heures de tous les jours.
Par exemple, pour ne scruter le gestionnaire de versions que pendant les heures et jours de travail :
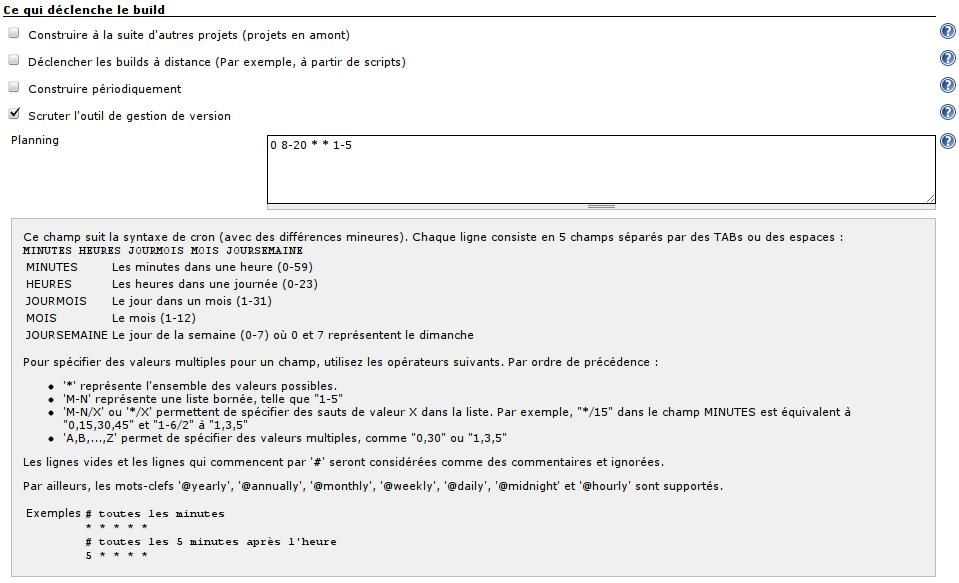
Si vous enregistrez la configuration en cet état, sans compléter la suite de l'écran, le job devrait fonctionner -- il ne fera qu'une seule chose : extraire les sources depuis le système de gestion de versions ; mais cela vous permettra de vérifier que cette première étape est fonctionnelle.
Après enregistrement, un build va être lancé automatiquement par Jenkins.
Une fois qu'il sera terminé, si vous cliquez dessus dans << l'historique des builds >>, vous aurez accès, dans le menu gauche, à une entrée << Sortie de la console >> ; ceci vous amènera à un écran affichant le détail de la sortie console obtenue pendant l'exécution du build.
Dans notre cas, voici à quoi cette console ressemble :
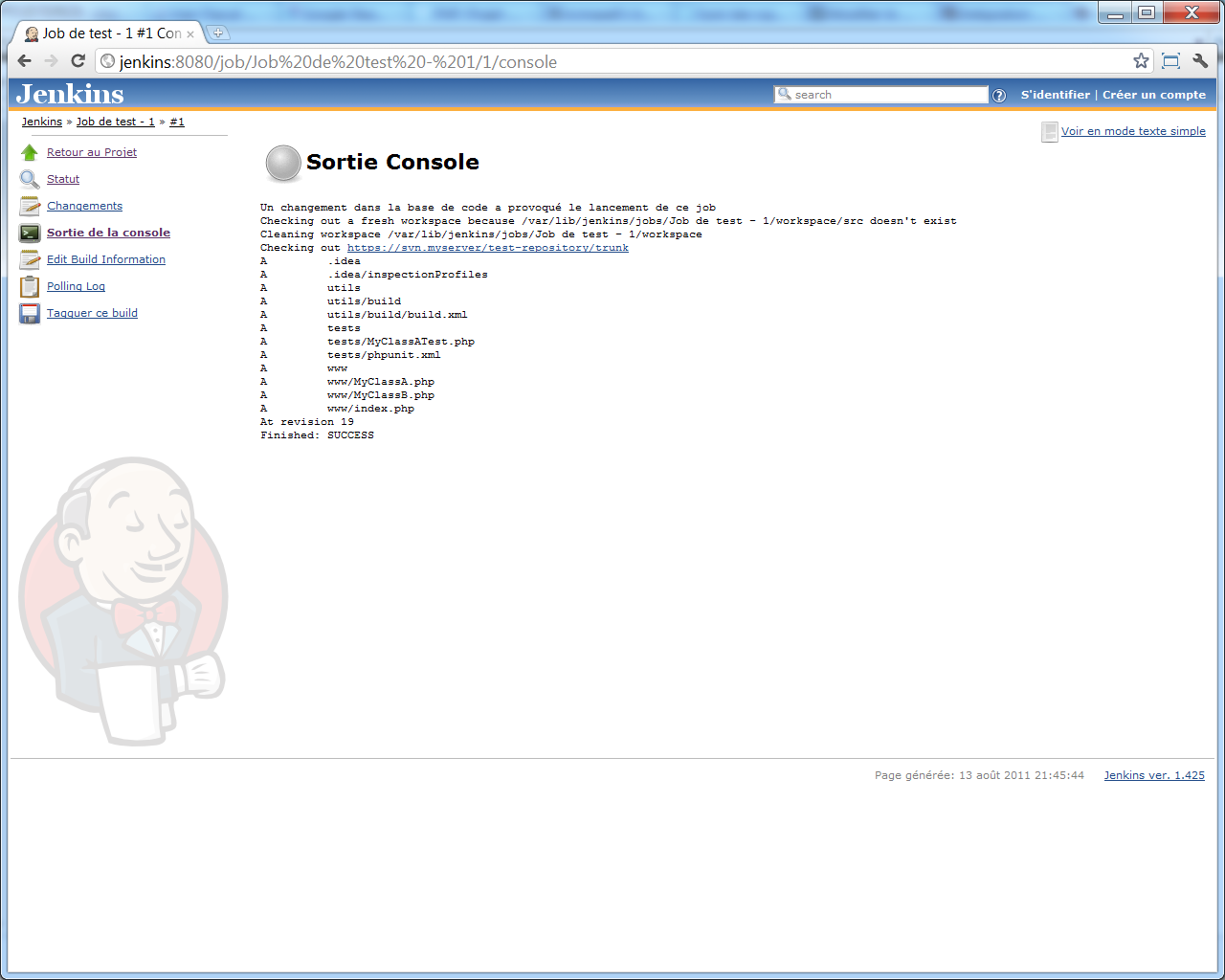
Autrement dit, les sources de notre projet ont été extraite depuis le serveur SVN avec succès ;-)
Depuis l'écran principal du job dans Jenkins, vous pourrez aussi accèder à l'écran << Espace de travail >>, qui vous permet de naviguer à travers les fichiers extraits -- ceux-ci l'ayant été vers le répertoire src configuré plus haut :
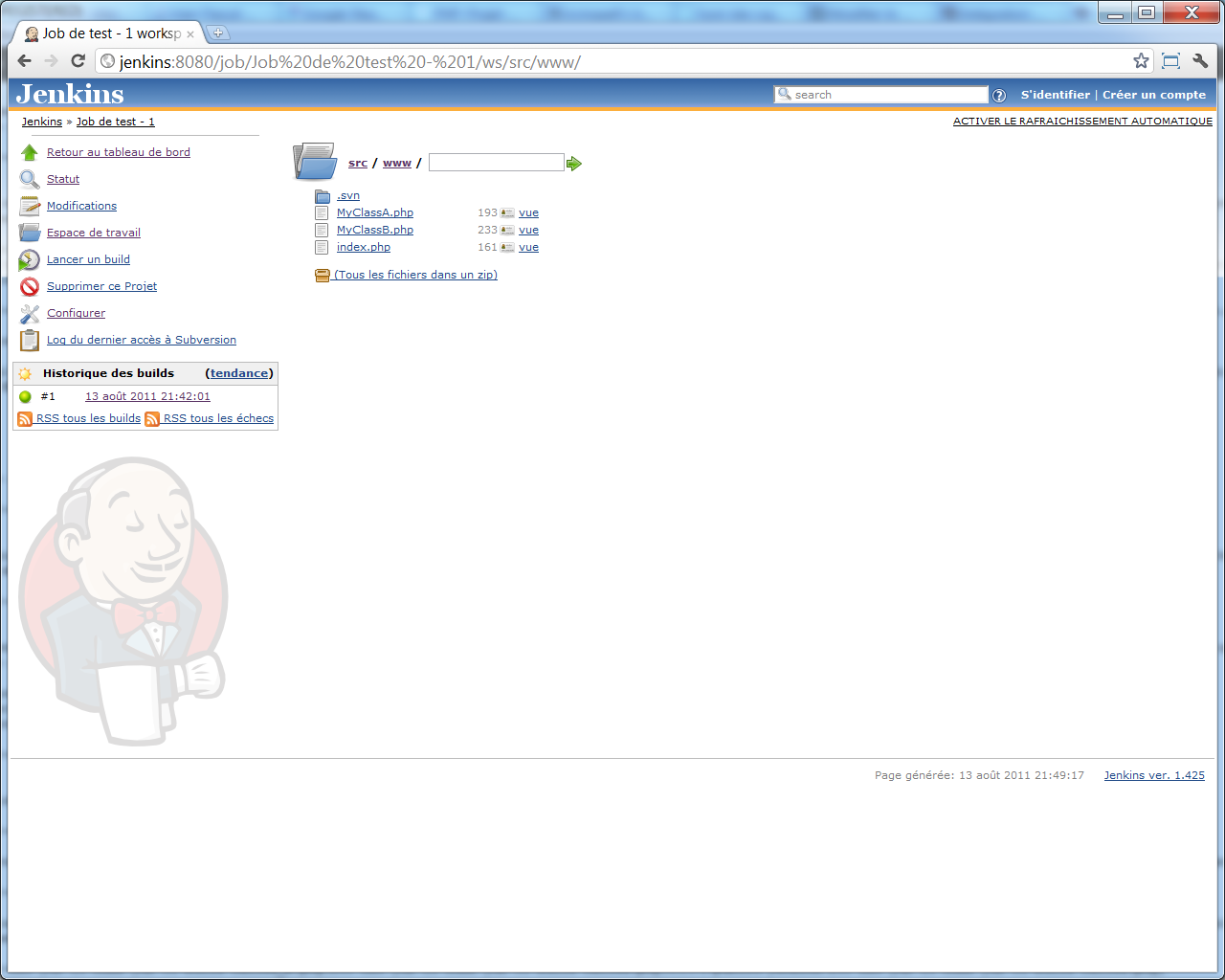
Utiliser Phing comme outil de build
Maintenant que nous savons que les sources de notre projet sont extraites avec succès, et que Jenkins parvient à accéder à notre système de gestion de versions, il ne reste plus qu'à retourner sur l'écran de configuration de notre job, afin d'indiquer que le build va être effectué par Phing.
Pour cela, nous allons << ajouter une étape au build >>, qui invoquera une target phing :

Nous renseignons ensuite à la fois la liste << Targets >> (pour ce projet, le build entier est invoqué depuis la target ci, comme nous le verrons plus bas), et le chemin vers le script de build (le fichier build.xml, dans le projet dont j'ai montré l'arborescence un peu plus haut) :

La dernière étape de configuration de notre job serait de sélectionner et configurer les actions à effectuer à la suite du Build : typiquement, publier les résultats des analyses de qualité sur le code-source de notre application.
Mais, pour l'instant, nous ne cocherons rien :
- Avant de se préoccuper des outils de contrôle qualité, nous aimerions nous assurer que notre job fonctionne,
- Et nous allons de toute façon, pour cela, mettre en place le script de build Phing :
build.xml-- sinon, notre projet ne se construira de toute manière pas.

Une fois la configuration du job enregistrée, sa page d'accueil devrait ressembler à quelque chose de ce type :
Et, à chaque fois que vous commiterez une modification sur le code-source de votre application, un nouveau build devrait se lancer (Cf << Historique des builds >>, à gauche de l'écran) :
Bon, comme je disais plus haut, tant que nous n'avons pas mis en place build.xml, ça risque de ne pas très bien se passer, et les builds échoueront (une puce rouge indique un build en échec, dans l'historique) :
Et sur l'écran de détail du build :
Script de construction : build.xml
Un peu plus haut, nous avons indiqué à Jenkins, en configurant notre job, que celui-ci devait être construit via une target phing nommée ci, dans le fichier utils/build/build.xml.
Initialisation de build.xml : 3 targets
Cette target ci dépendra elle-même de deux autres targets :
clean, pour le nettoyage des répertoires de reporting (où les outils d'analyse enregistreront leurs rapports),- et
qa, pour le lancement des outils (qui généreront les rapports que Jenkins mettra à disposition des utilisateurs).
Créons donc ce fichier, en initialisant les trois targets correspondantes :
<?xml version="1.0" encoding="UTF-8"?>
<project name="TestJenkins" default="ci" basedir="../../..">
<property name="source" value="src" />
<target name="ci"
description="Tâche principale d'intégration continue"
depends="clean,qa"
/>
<target name="clean" description="Vide les répertoires d'artefacts">
</target>
<target name="qa" description="Lance les outils d'analyse">
</target>
</project>Vous remarquerez que j'ai commencé par initialiser une propriété, nommée source, qui contient le nom du répertoire où les sources seront extraites sur la plate-forme d'Intégration Continue -- si vous avez suivi ce que je disais plus haut, vous utiliserez la même valeur que moi : src.
Si vous commitez ce fichier et attendez quelques instants, Jenkins lancera un build ; et la sortie de la console correspondant à son exécution sera la suivante :
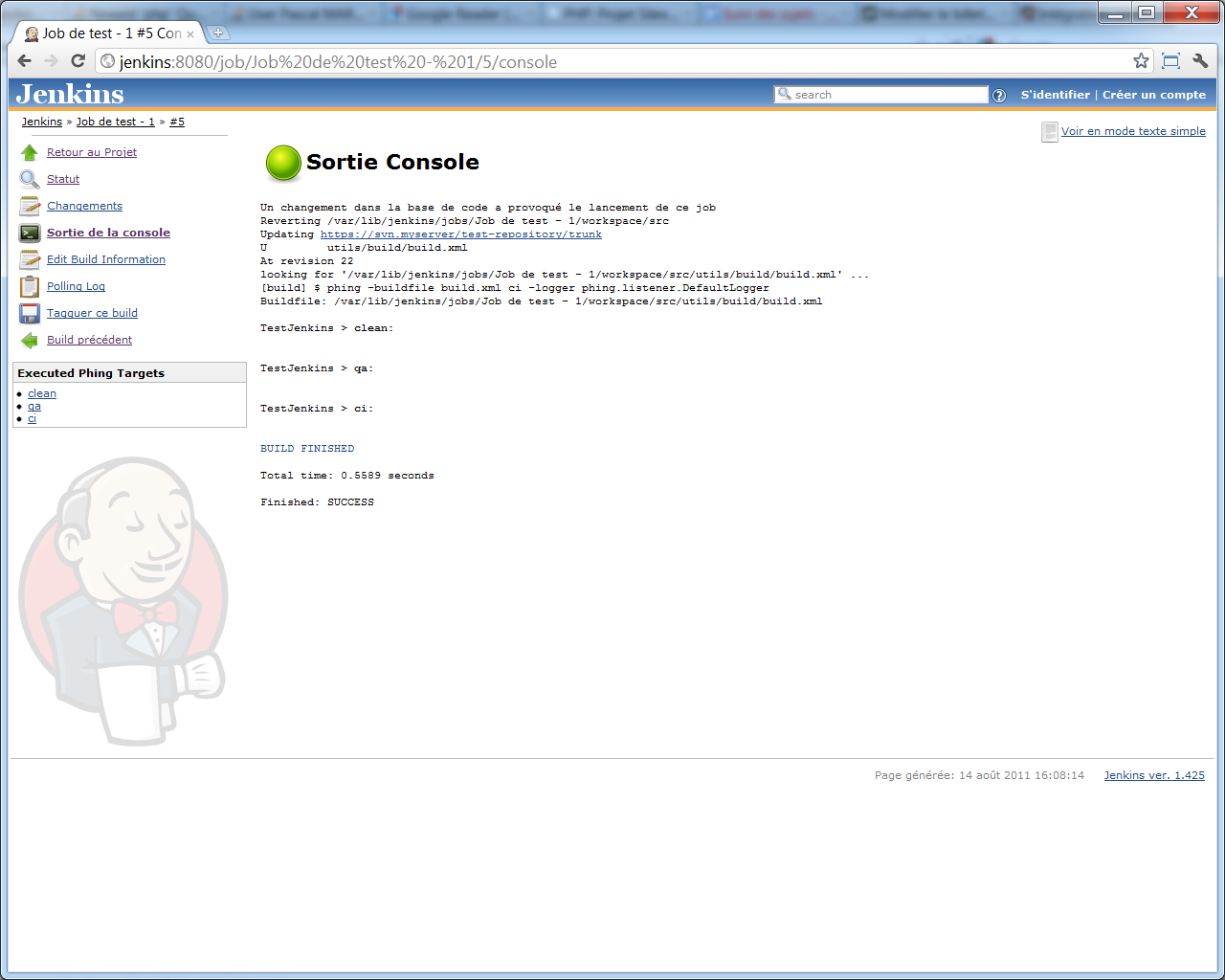
Autrement dit :
- Le build a réussi : le fichier
utils/build/build.xmlexiste, et correspond bien à un fichier Phing valide, - Nos trois tâches ont été lancées :
- Tout d'abord, la tâche
clean, - Puis la tâche
qa, - Et enfin, la tâche
ci, dont le seul rôle était de dépendre des deux autres, pour assurer leur bonne exécution.
- Tout d'abord, la tâche
Target clean
La première étape de notre build est de supprimer les éventuels résultats d'analyses du précédent (pour être sûr que les reporting n'utiliseront que les données issues du build courant), et, au besoin, de créer les répertoires qui contiendront les résultats de ces analyses.
Les répertoires à vider / créer dépendent des outils d'analyse que vous utiliserez sur votre projet, mais, en supposant que vous utiliserez ceux que je vais mettre en place plus loin, votre target clean devrait ressembler à ceci :
<target name="clean" description="Vide les répertoires d'artefacts">
<delete dir="${project.basedir}/build/api" />
<delete dir="${project.basedir}/build/code-browser" />
<delete dir="${project.basedir}/build/coverage" />
<delete dir="${project.basedir}/build/logs" />
<delete dir="${project.basedir}/build/pdepend" />
<mkdir dir="${project.basedir}/build/api" />
<mkdir dir="${project.basedir}/build/code-browser" />
<mkdir dir="${project.basedir}/build/coverage" />
<mkdir dir="${project.basedir}/build/logs" />
<mkdir dir="${project.basedir}/build/pdepend" />
</target>Et, une fois build.xml commité, la sortie console de Jenkins devrait afficher quelque chose de ce type :
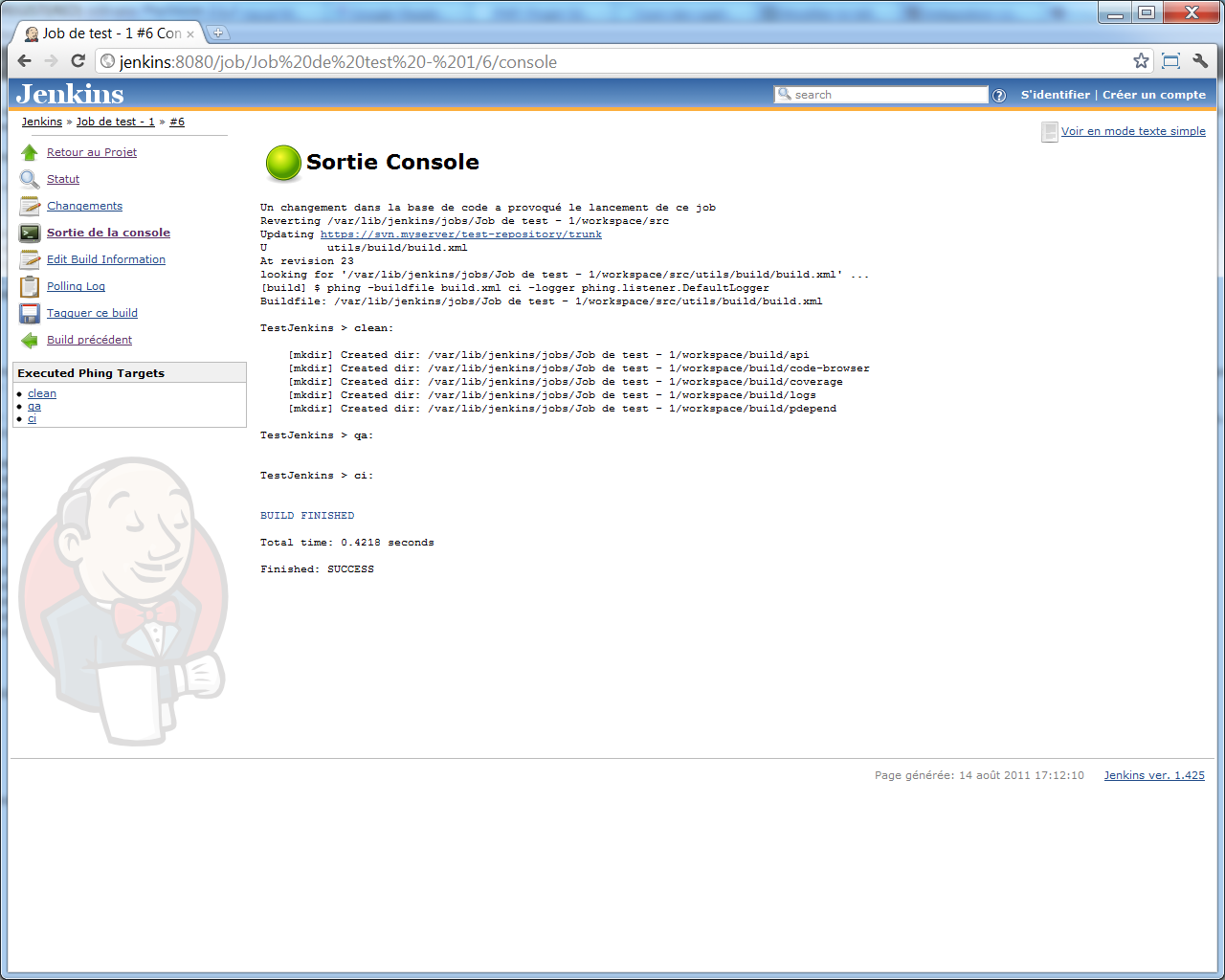
Et si vous jetez un coup d'oeil au workspace de votre projet depuis Jenkins, vous y retrouverez les répertoires que nous venons de créer, dans un répertoire build se trouvant au même niveau que notre répertoire src contenant le code-source de notre application (les résultats d'analyse ne viennent donc pas s'enregistrer au même endroit que notre code) :
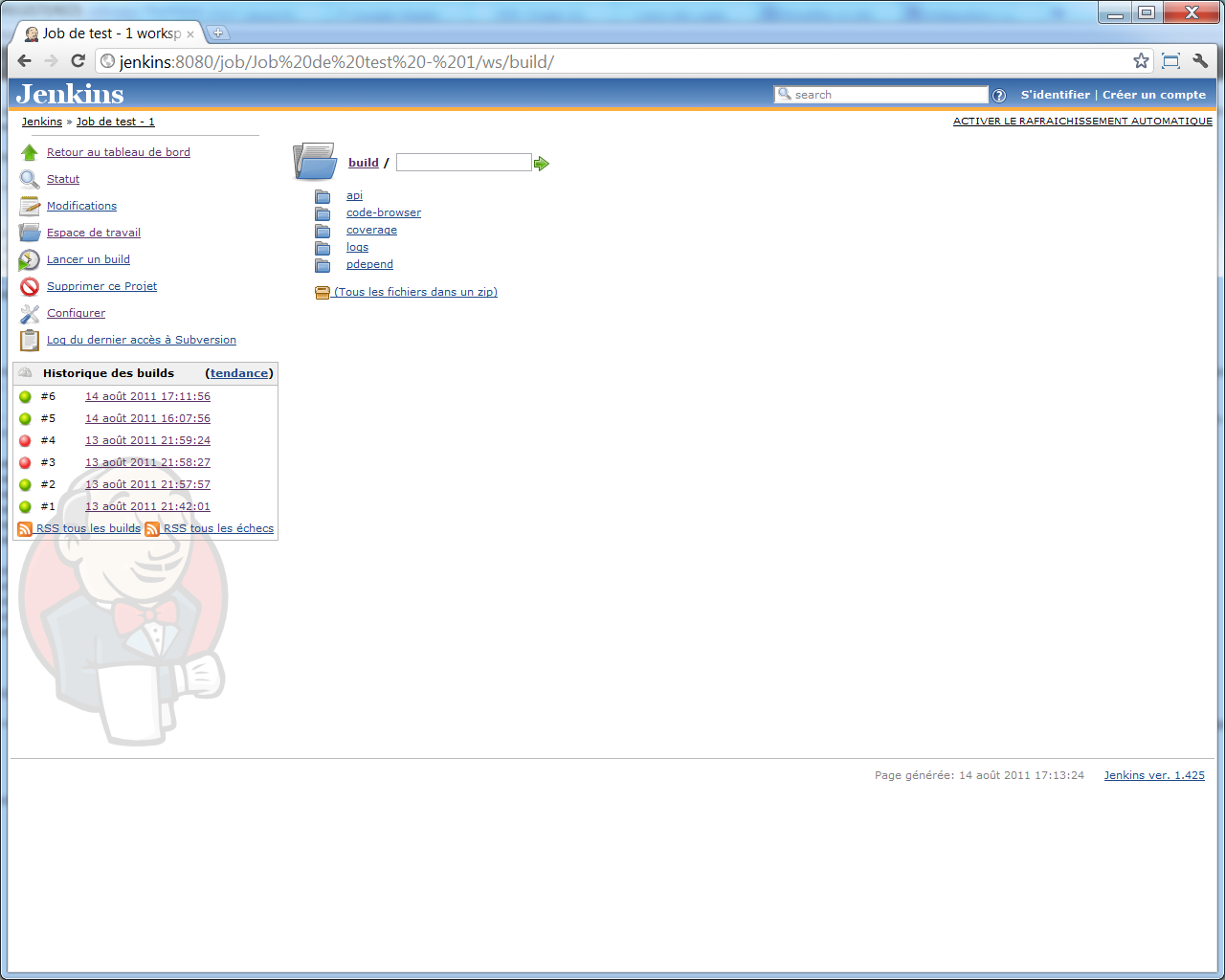
Target qa : les outils d'analyse de qualité
Nous en arrivons enfin à la partie la plus intéressante de notre script build.xml : la mise en place des outils d'analyse de qualité.
Principe
Dans le principe, ma target qa ne fait généralement rien d'autre qu'appeler d'autres targets : une par outil.
Typiquement, elle ressemblera donc à quelque chose de ce type :
<target name="qa" description="Lance les outils d'analyse">
<phingcall target="premier-outil" />
<phingcall target="second-outil" />
<phingcall target="troisime-outil" />
</target>Les targets spécifiques à chaque outil étant définies plus bas :
<target name="premier-outil" description="...">
<!-- Ici, le gros du boulot pour le premier outil ;-) -->
</target>
<target name="second-outil" description="...">
<!-- Ici, le gros du boulot pour le second outil ;-) -->
</target>
<target name="troisime-outil" description="...">
<!-- Et là, le gros du boulot pour le dernier ;-) -->
</target>Je vois deux avantages à cette solution :
- D'une part, les targets spécifiques à chaque outils portent des noms explicites, et ne font que quelques lignes de long ; elles sont donc plus facile à comprendre,
- Et, d'autre part, il suffit de commenter ou dé-commenter une
<phingcall>pour activer ou désactiver un outil d'analyse.
Ci-dessous, donc, à chaque nouvelle target que nous implémenterons pour un nouvel outil, il faudra penser à ajouter son appel, via <phingcall>, à la target qa.
Target pdepend
La première target que je reproduis ci-dessous est celle qui permet d'invoquer l'outil PHP Depend :
<target name="pdepend">
<phpdepend file="${project.basedir}/${source}/www">
<logger type="jdepend-xml" outfile="${project.basedir}/build/logs/jdepend.xml" />
<logger type="jdepend-chart" outfile="${project.basedir}/build/pdepend/dependencies.svg" />
<logger type="overview-pyramid" outfile="${project.basedir}/build/pdepend/overview-pyramid.svg" />
</phpdepend>
</target>On notera trois choses, ici :
- Tout d'abord (et c'est le cas pour un bon nombre des targets que nous verrons ensuite), phing fourni une tâche spécifique pour cet outil :
<phpdepend>-- ce qui signifie que nous n'avons pas besoin de passer par un tâche<exec>pour directement lancer le binaire correspondant[3]. - Dans pas mal de cas, nous allons specifier des formats de sortie correspondant à ceux des outils du monde JAVA -- ces formats étant déjà acceptés par Jenkins
- Et, enfin, nos fichiers de sortie seront générés dans le répertoire
build, que nous avons présenté plus haut.
Target phpmd
Branchons ensuite l'appel à l'outil PHP Mess Detector, pour la remontée de statistiques susceptibles de mettre en évidence des portions de code-source de qualité médiocre :
<target name="phpmd">
<phpmd file="${project.basedir}/${source}/www">
<formatter type="xml" outfile="${project.basedir}/build/phpmd.xml" />
</phpmd>
</target>Ici encore, nous utilisons une tâche fournie spécialement par Phing, et indiquons que le fichier en sortie doit être généré vers le répertoire build.
Target phpcpd
Passons ensuite à l'appel de l'outil phpcpd, pour la détection de portions de code copié-collé :
<target name="phpcpd">
<phpcpd file="${project.basedir}/${source}/www">
<formatter type="pmd" outfile="${project.basedir}/build/logs/pmd-cpd.xml"/>
</phpcpd>
</target>Target phploc
Enchainons ensuite avec la collecte de statistiques du type nombres de méthodes, nombres de classes, nombres de lignes de code, ... avec l'outil phploc :
<target name="phploc">
<exec logoutput="true" dir="${project.basedir}" command="phploc --log-csv '${project.basedir}/build/logs/phploc.csv' '${project.basedir}/${source}/www'" escape="false" />
</target>Ici, le fichier généré en sortie sera un fichier .csv -- Jenkins ne saura pas en faire grand chose en l'état, mais, avec un peu de configuration, nous obtiendrons des graphes de nombres de lignes de code, de nombres de méthodes, ...
Target phpcs
Vérifions ensuite le respect des normes de codage, avec PHP_CodeSniffer :
<target name="phpcs">
<phpcodesniffer standard="Zend">
<fileset dir="${project.basedir}/${source}/www">
<include name="**/*.php"/>
</fileset>
<formatter type="checkstyle" outfile="${project.basedir}/build/logs/checkstyle.xml"/>
</phpcodesniffer>
</target>Target phpdoc
Si vous utilisez phpDocumentor pour la génération de votre documentation d'API, voici une target qui devrait vous intéresser :
<target name="phpdoc">
<phpdoc title="API Documentation"
destdir="${project.basedir}/build/api"
sourcecode="false"
output="HTML:Smarty:PHP">
<fileset dir="${project.basedir}/${source}/www">
<include name="**/*.php"/>
</fileset>
<projdocfileset dir=".">
<include name="README"/>
<include name="INSTALL"/>
<include name="CHANGELOG"/>
</projdocfileset>
</phpdoc>
</target>Notez que si vous utilisez phpdox, Phing fourni aussi une tâche <docblox> ;-)
Target phpunit
Pour invoquer PHPUnit, Phing fournit une tâche <phpunit>, mais je n'ai pas réussi à la faire fonctionner en utilisant un fichier phpunit.xml pour la configuration des tests.
Ne souhaitant pas dupliquer la configuration de PHPUnit (une fois ici, dans build.xml, et une fois dans phpunit.xml tel qu'attendu par PHPUnit), j'ai préféré utiliser la tâche <exec>, pour invoquer directement l'utilitaire phpunit en ligne de commande :
<target name="phpunit">
<exec logoutput="true" dir="${project.basedir}/${source}/tests" command="phpunit" escape="false" />
</target>Et voici un exemple de fichier phpunit.xml, qui colle au projet d'exemple que j'ai utilisé pour rédiger cet article :
<phpunit>
<testsuites>
<testsuite name="My Test Suite">
<directory>./</directory>
</testsuite>
</testsuites>
<filter>
<whitelist>
<directory suffix=".php">../www</directory>
</whitelist>
</filter>
<logging>
<log type="coverage-html" target="../../build/coverage" title="Name of Project"
charset="UTF-8" yui="true" highlight="true"
lowUpperBound="35" highLowerBound="70"/>
<log type="coverage-clover" target="../../build/logs/clover.xml"/>
<log type="junit" target="../../build/logs/junit.xml" logIncompleteSkipped="false"/>
</logging>
</phpunit>Immense avantage : ce fichier phpunit.xml va être utilisé à la fois par chacun des développeurs de votre équipe sur leurs postes de développement, et par la plate-forme d'Intégration Continue.
Target phpcb
Et pour finir, voici la target invoquant PHP_CodeBrowser, pour intégrer un navigateur de code à Jenkins, qui prenne en compte les résultats issus d'outils cités ci-dessus :
<target name="phpcb">
<exec logoutput="true" command="phpcb --log '${project.basedir}/build/logs' --source '${project.basedir}/${source}/www' --output '${project.basedir}/build/code-browser'" escape="false" />
</target>Ici encore, Phing ne fourni pas de tâche spécifique, et nous passons donc par <exec>[4].
Target qa complète
Maintenant que nous avons mis en place les targets correspondant à chacun de nos outils d'analyse, nous pouvons revenir à la target qa, chargée de les invoquer les uns après les autres, et la compléter :
<target name="qa" description="Lance les outils d'analyse">
<phingcall target="pdepend" />
<phingcall target="phpmd" />
<phingcall target="phpcpd" />
<phingcall target="phploc" />
<phingcall target="phpcs" />
<phingcall target="phpdoc" />
<phingcall target="phpunit" />
<phingcall target="phpcb" />
</target>Résultat du build
Si nous commitons notre fichier build.xml et attendons quelques instants qu'un build se lance, et allons faire un tour sur l'écran << Sortie de la console >> de Jenkins, nous verrons que l'ensemble des outils d'analyse ont été invoqués.
Je ne reproduis pas toute la sortie ici, mais voici un bref aperçu du début de la sortie (On voit notamment que les targets pdepend et phpmd ont été invoquées) :
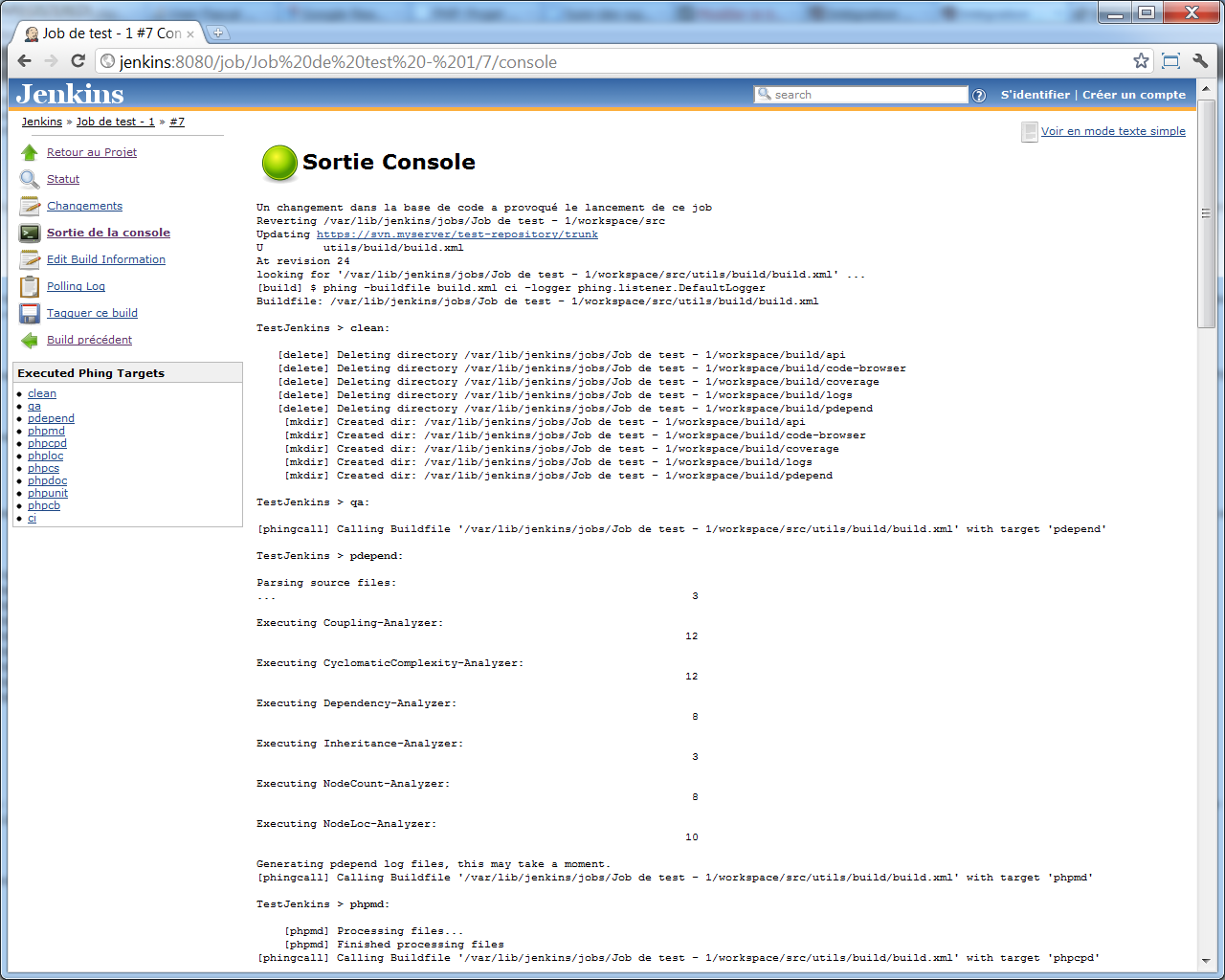
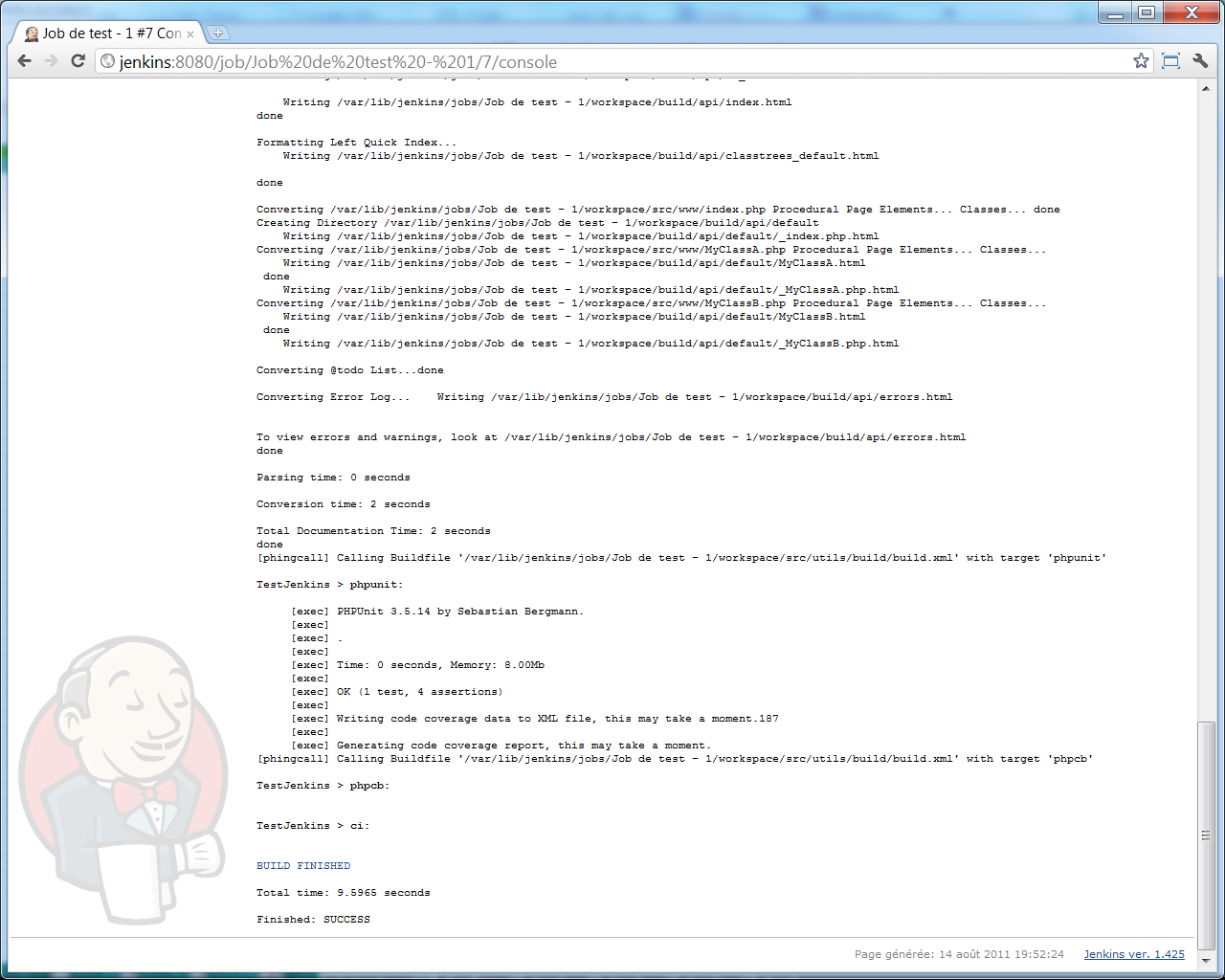
Et voici un aperçu de la fin de la sortie console (ici, on voit que les targets phpunit et phpcb ont été invoquées, et que le build s'est terminé avec succès) :
Publier les résultats du build
Où en sommes-nous ?
Nous avons un projet PHP, nous avons mis en place une plate-forme d'intégration continue, nous avons créé notre script de build, celui-ci lance plusieurs outils d'analyse sur le code de notre projet... Il ne nous reste donc plus qu'à publier les résultats de ces analyses, n'est-ce pas ?
Pour mettre en place la configuration de ces résultats d'analyses, nous allons retourner sur la page de configuration de notre job, sur l'interface web de Jenkins : en bas de cette page figure une section << Actions à la suite du Build >>, que nous n'avions pas renseignée, plus haut :

Nous allons donc configurer les actions de publications correspondant aux outils que nous avons mis en place lors du build.
Analyse checkstyle
Dans notre fichier build.xml, nous avons invoqué l'outil PHP_CodeSniffer, en lui demandant de générer en sortie un fichier build/logs/checkstyle.xml.
Renseignons donc ce chemin dans le champ de formulaire correspondant :

Si vous souhaitez configurer plus finement certaines options, vous pouvez cliquer sur << Avancé >>, pour accéder au formulaire complet :
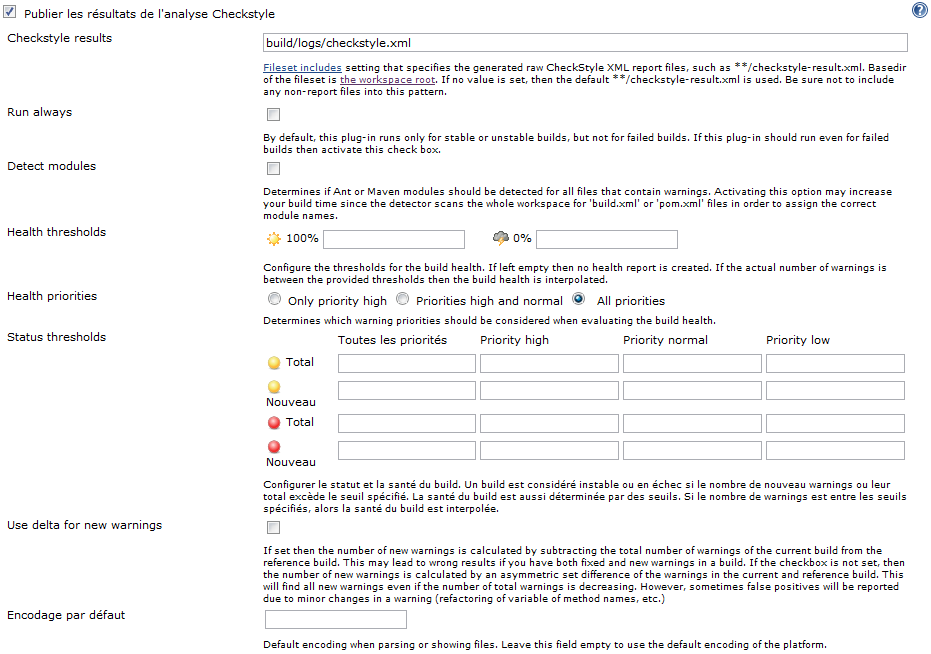
Une fois ceci configuré, enregistrez le job ; et lançons manuellement un build (puisqu'aucune modification de code source n'a été effectuée sur le gestionnaire de versions, Jenkins ne lancera pas de build automatiquement)...
Tout à la fin de la sortie console du build, nous voyons que Jenkins a analysé le fichier checkstyle.xml que nous venons de lui indiquer :

Une entrée << Résultats Checkstyle >> figure maintenant dans le menu de notre projet, à gauche de l'écran :
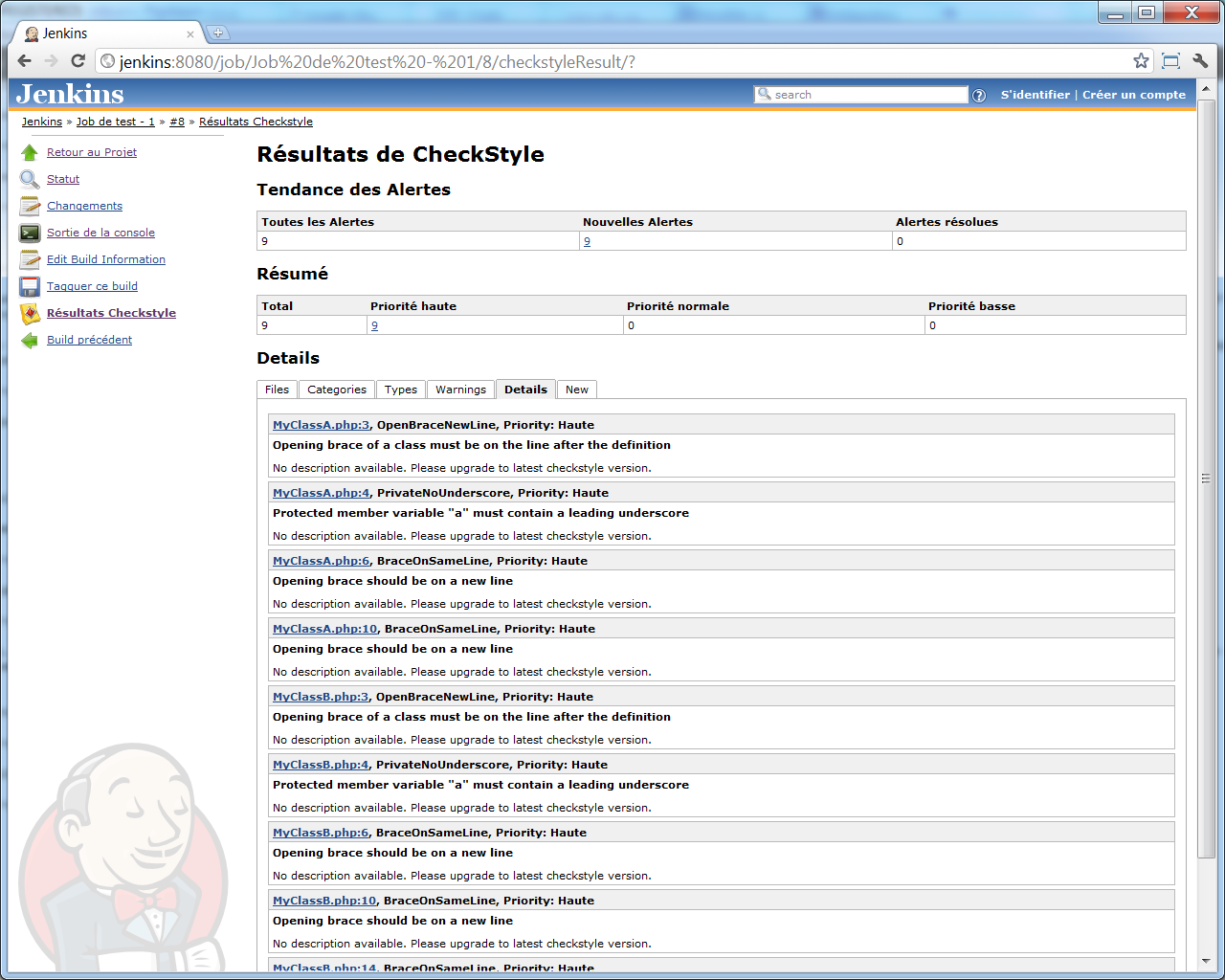
Et cliquer sur cette entrée nous mène à une série d'écrans / onglets nous permettant de consulter les résultats de l'analyse checkstyle :
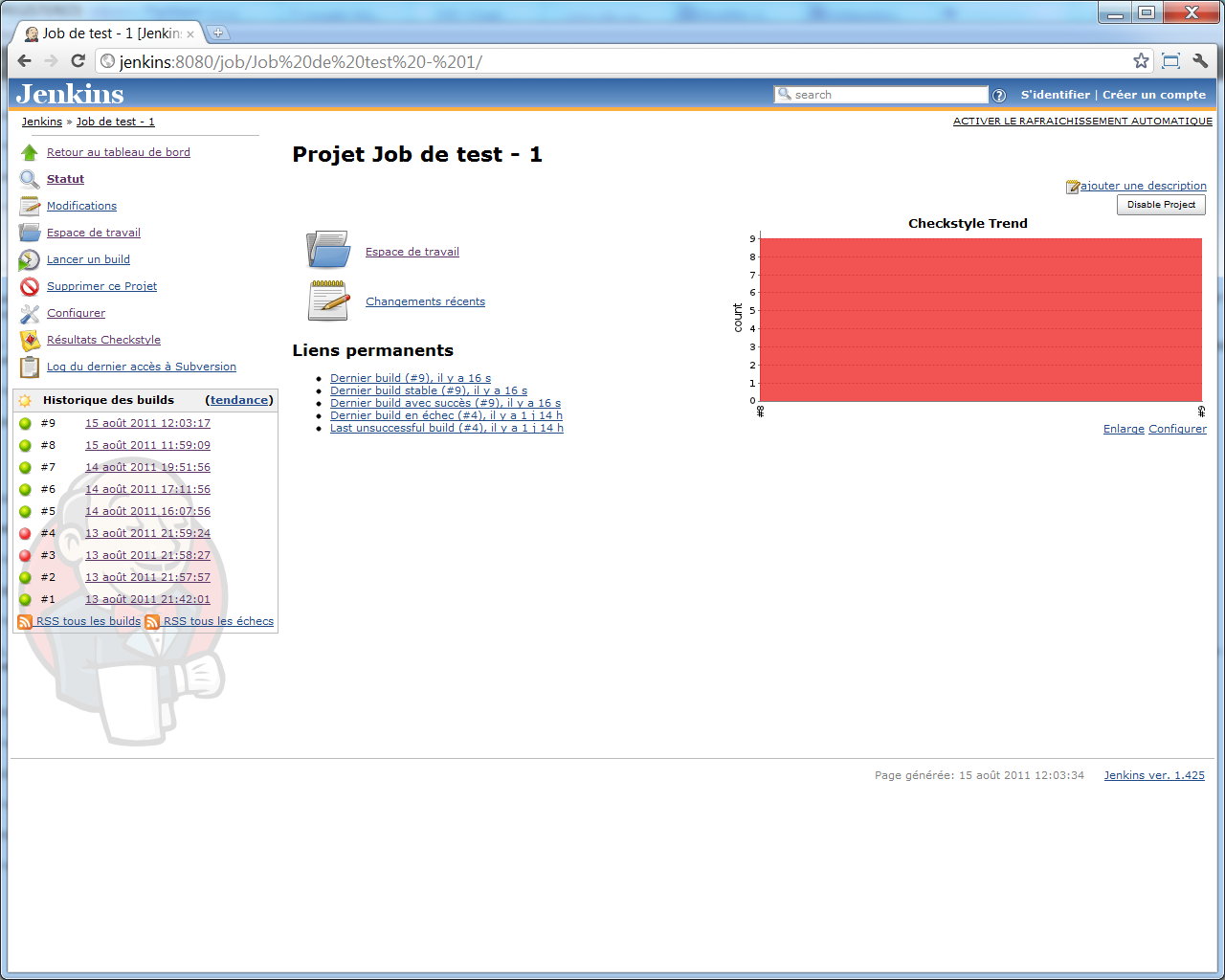
Enfin, si nous re-lançons un build, nous verrons que, une fois son exécution terminée, un graphe remonte sur l'écran d'accueil de notre projet, mettant en évidence la << tendance >> des résultats de notre analyse (un seul build n'étant pas assez pour tracer un graphe de progression : il en faut au moins deux, pour qu'une comparaison soit possible) :
Analyse PMD
L'étape suivante est d'activer la publication des rapports d'analyse PMD :

Avec, ici aussi, la possibilité de configurer le publieur de manière un peu plus poussée :
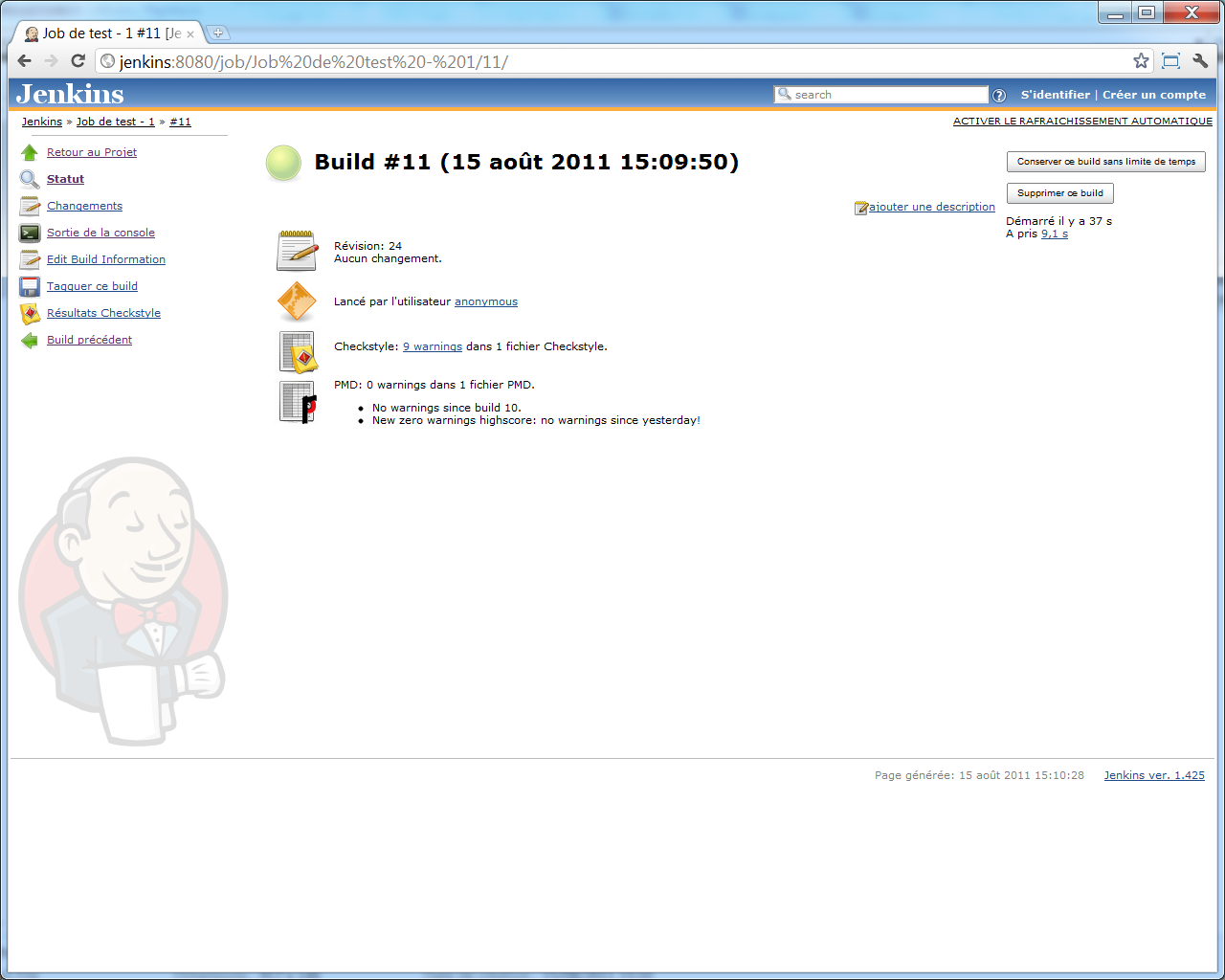
Une fois un build lancé, nous pouvons constater à la fin de sa sortie console que les résultats de l'analyse PMD ont été pris en compte :

Le nombre de problèmes relevés est indiqué sur la page principale du build :
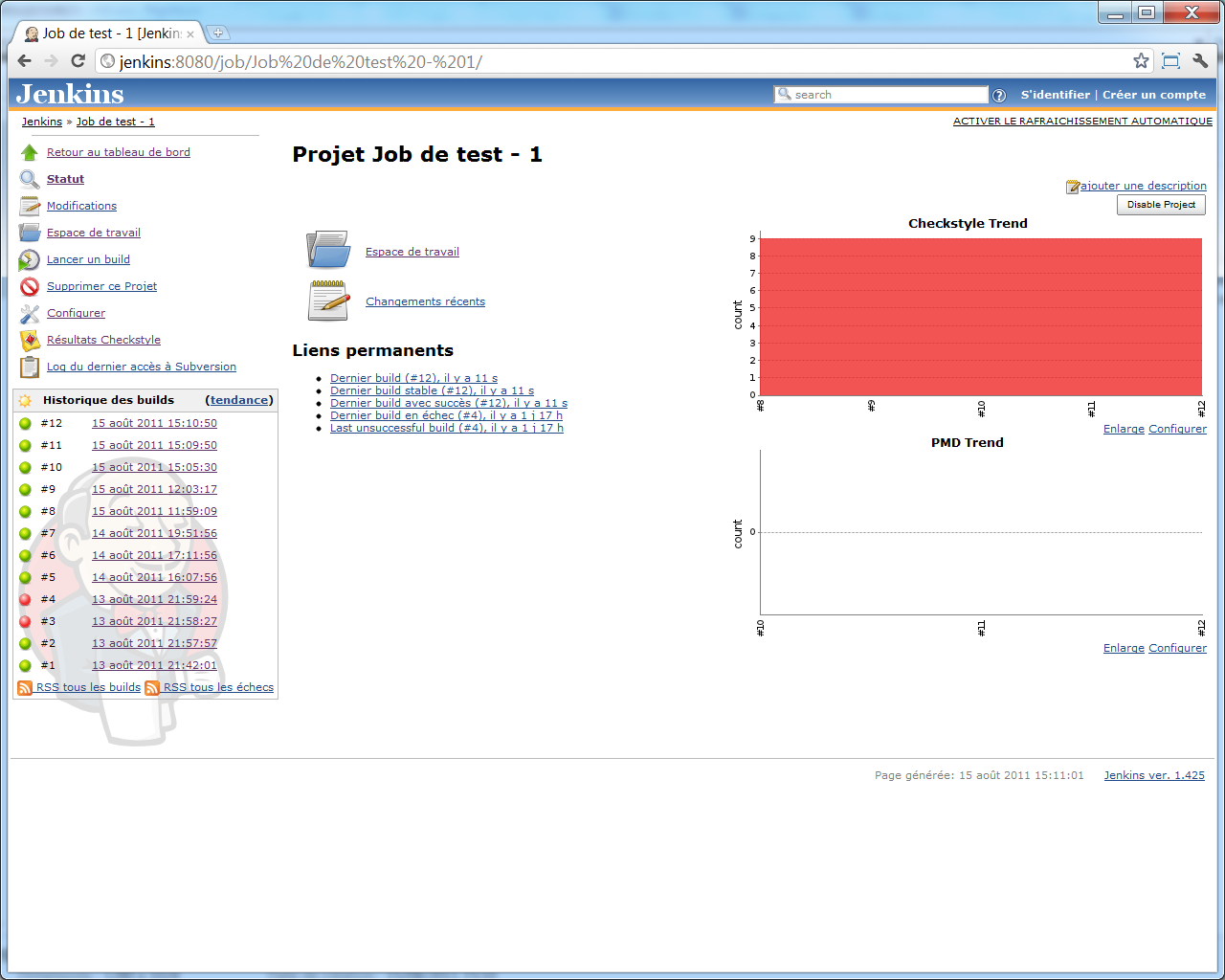
Et après quelques builds, l'écran d'accueil de notre job voit apparaitre un nouveau graphique de tendances :
Analyse CPD
Après cela, passons à l'activation de la publication des rapports de l'analyse de détection de code copié-collé :
Ou, pour la version << avancée >> :
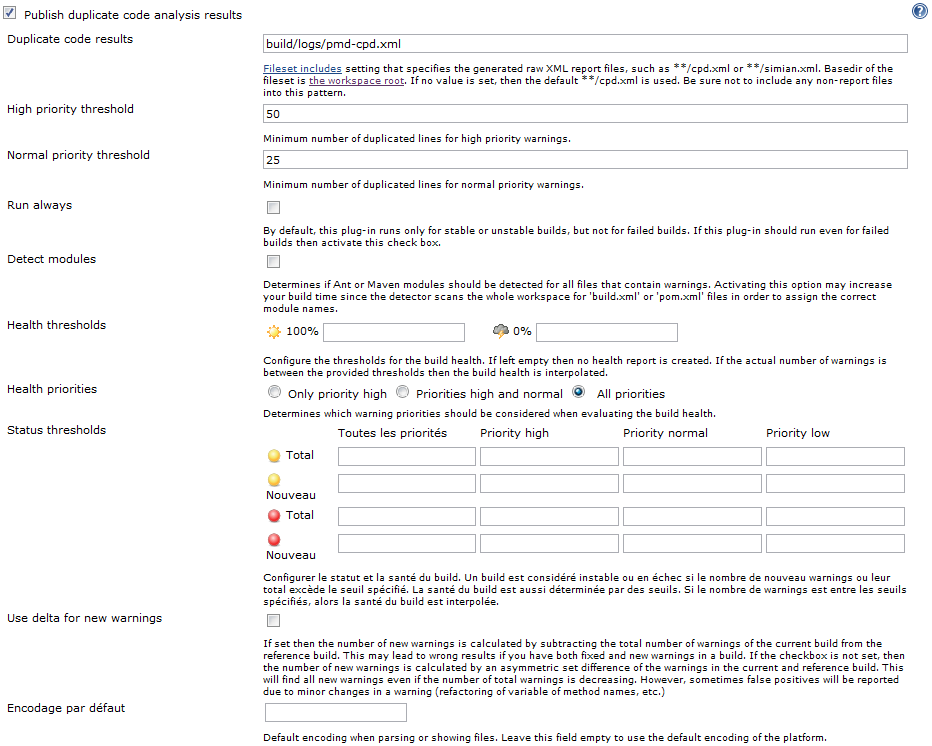
Et la sortie console d'un build, une fois cette publication activée (pour vérifier que notre demande de publication a bien été prise en compte -- et que nous n'avons pas raté un point lors de sa configuration) :

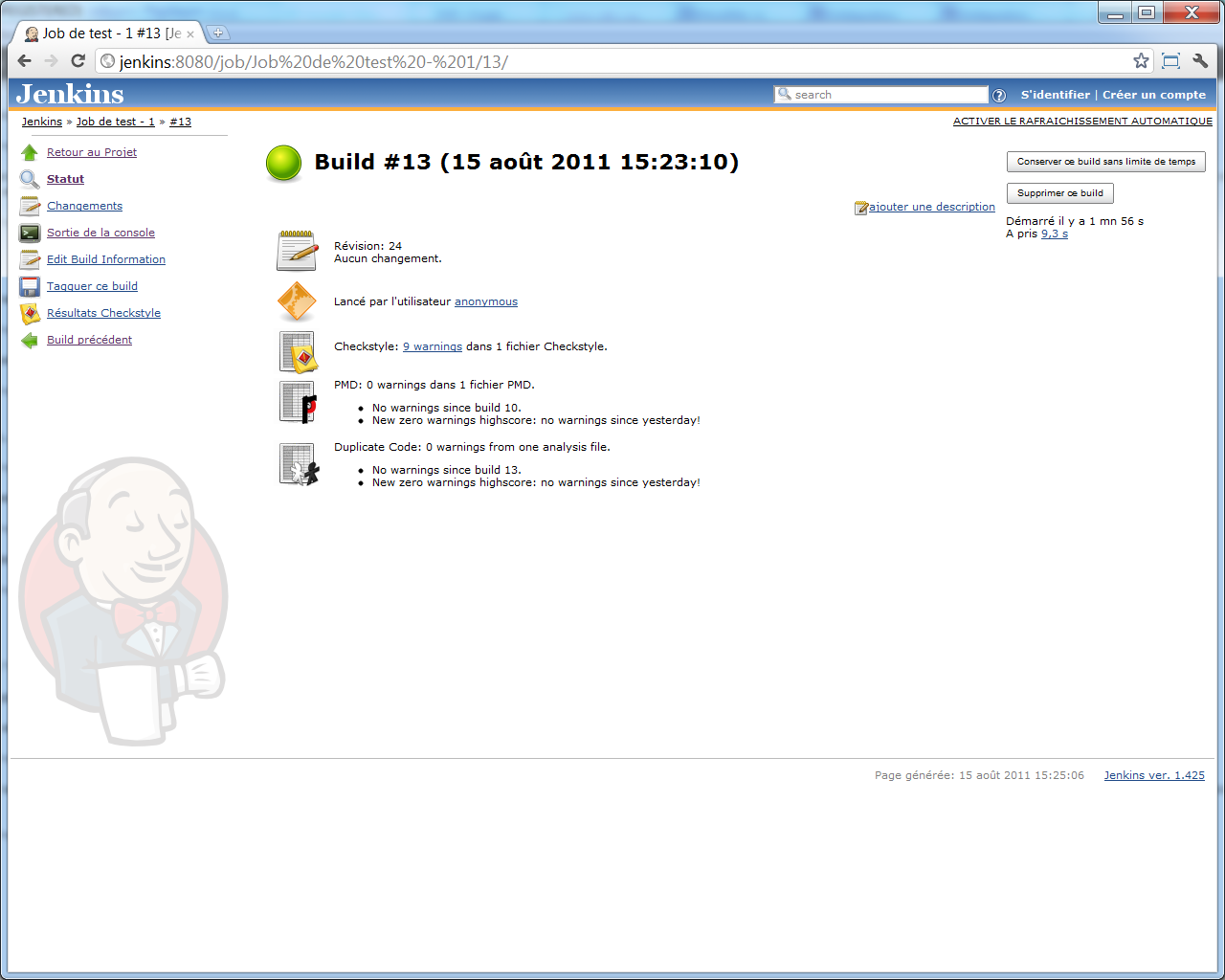
Une section supplémentaire s'ajoute à l'écran de détail de notre build, indiquant le nombre de portions de code dupliqué qui ont été relevées par l'analyse (vu la taille de notre projet d'exemple, il aurait été difficile de vraiment trouver des portions de code copiées-collées...) :
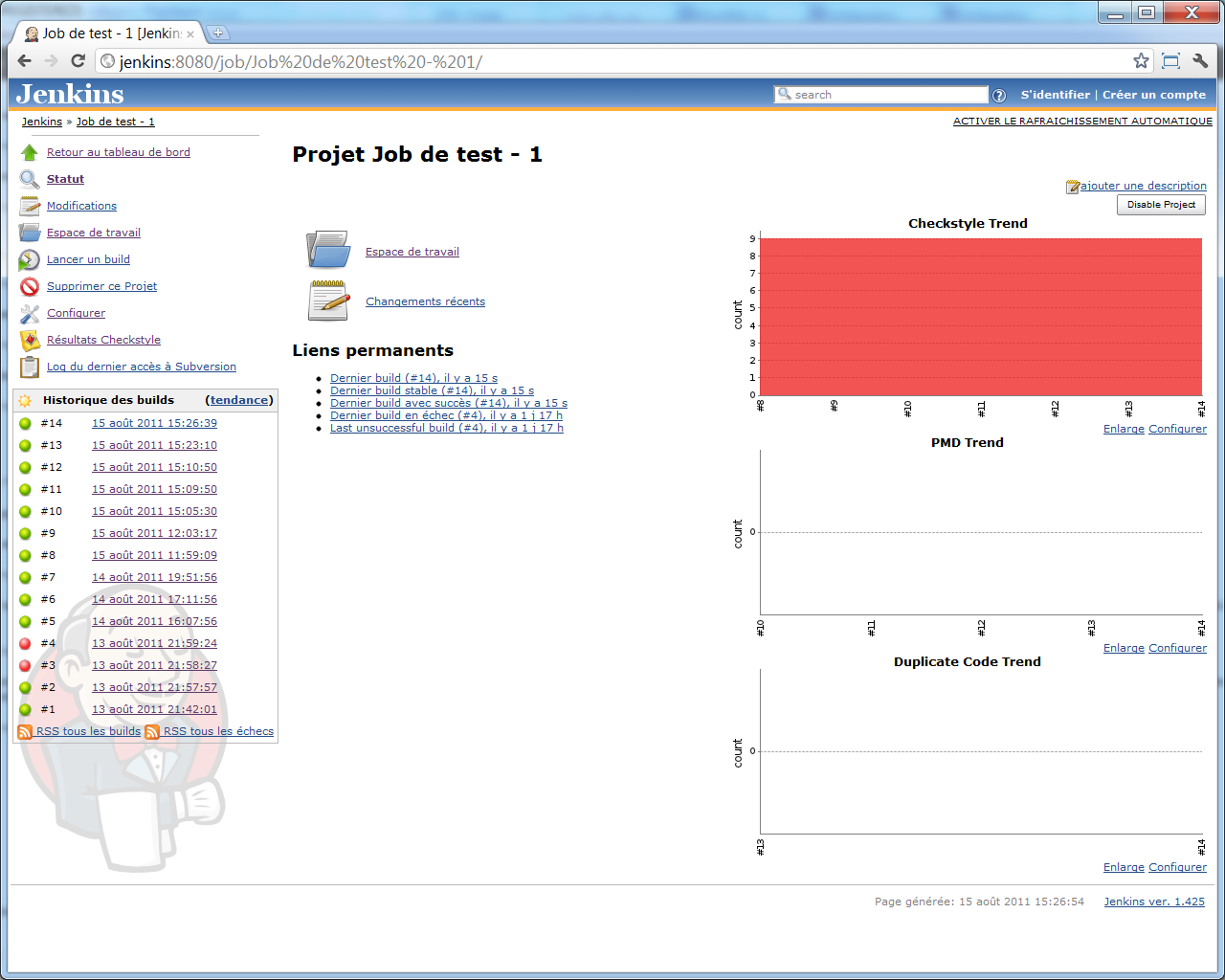
Et ici encore, au bout de quelques builds, un nouveau graphique vient s'ajouter à l'écran principal de notre job, illustrant la tendance :
Rapports de Tests Unitaires
Au tour, maintenant, des rapports de tests PHPUnit. Fort heureusement, PHPUnit est capable de générer des fichiers de rapports au format JUnit du monde JAVA -- ce qui tombe plutôt bien, quand notre plate-forme d'Intégration Continue est un outil du monde JAVA ;-)
Donc, activons la publication des rapport JUnit (PHPUnit, donc, mais faisons comme si) :

Une fois la configuration de notre job enregistrée, lançons un build, et vérifions la console :

Une entrée supplémentaire apparait sur l'écran principal de chaque build :
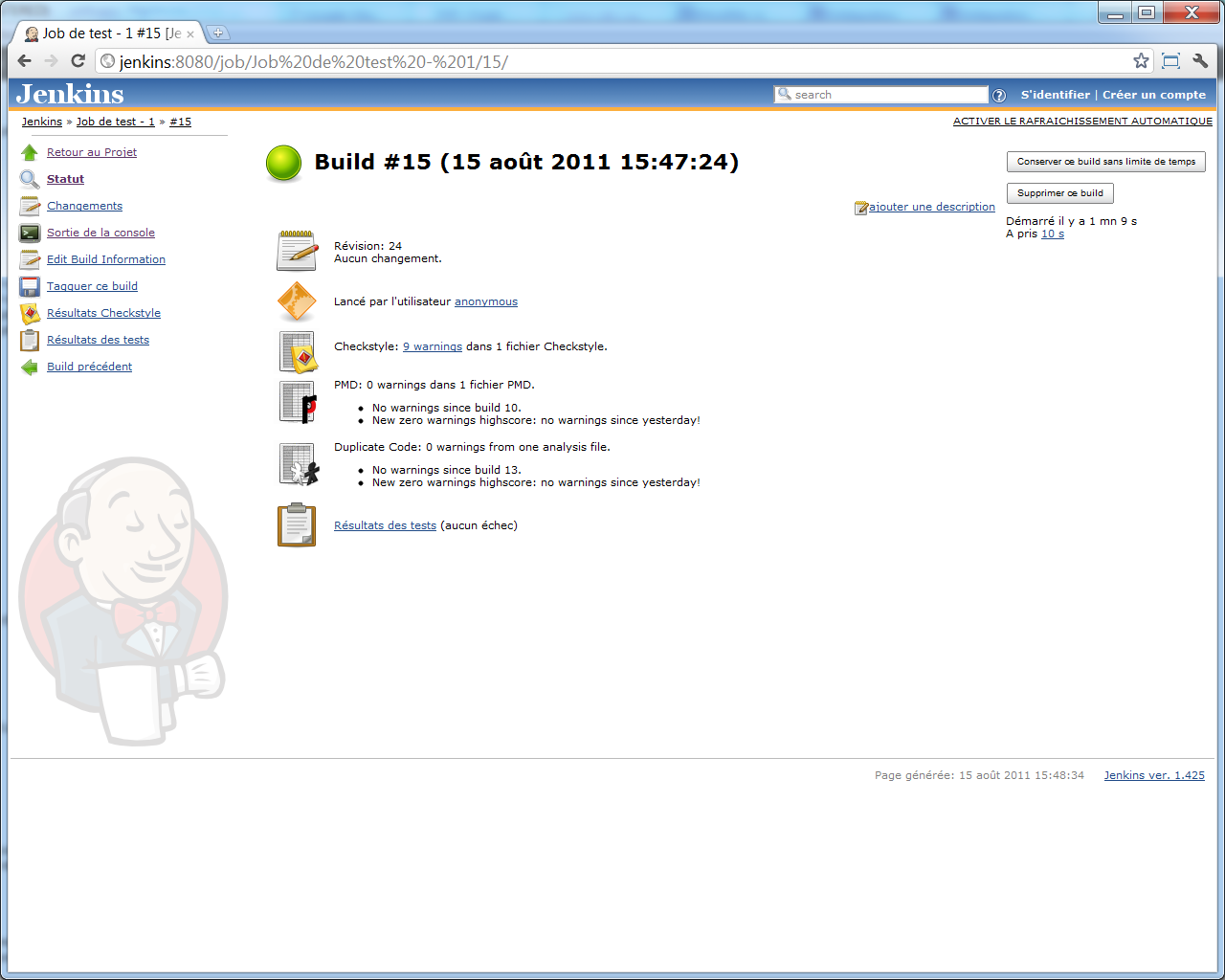
Et si nous cliquons sur le lien << Résultats des tests >>, nous pourrons naviguer plus en profondeur dans nos classes et méthodes de tests :
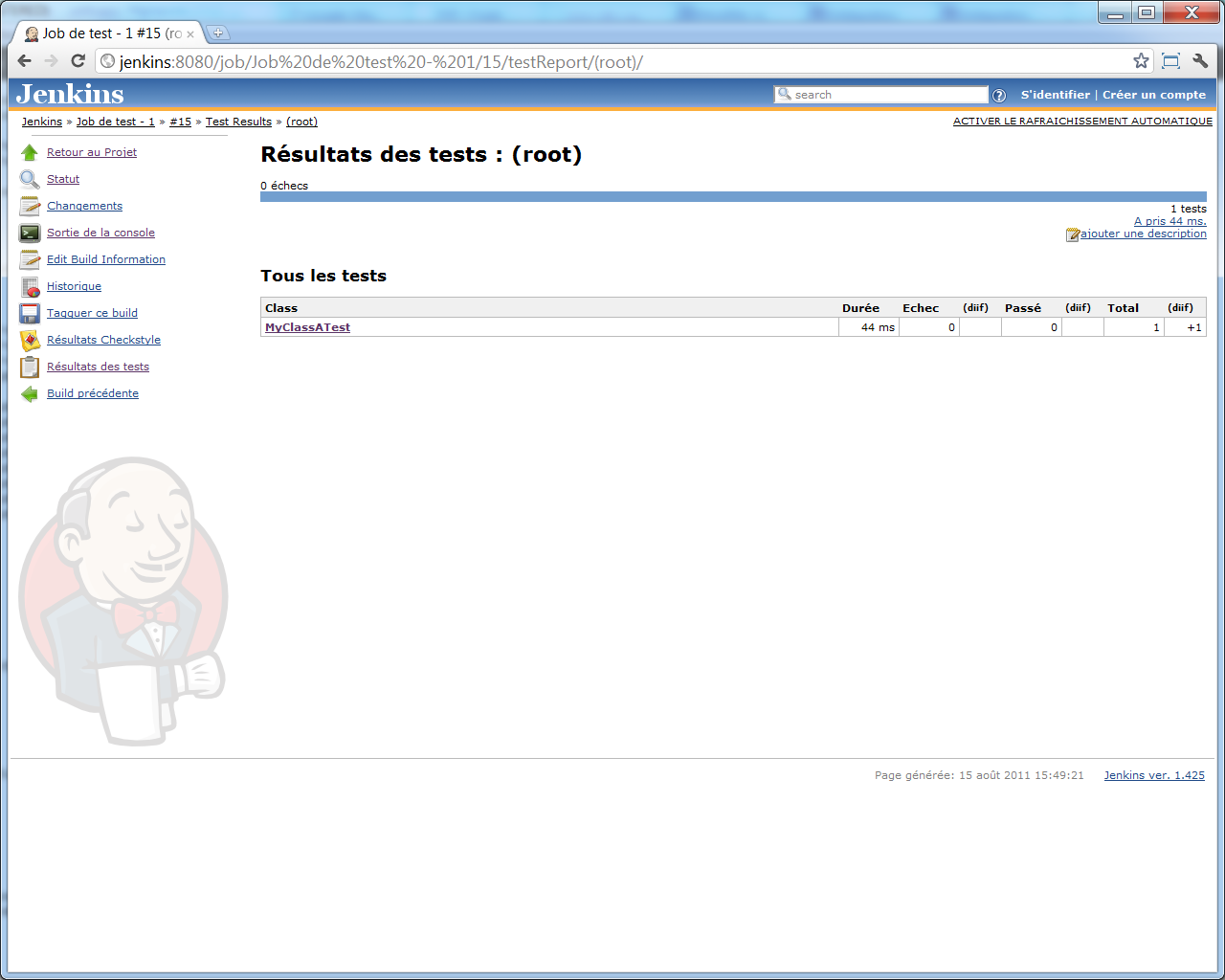
Une fois un second (ou plus) build lancé, nous constaterons une fois de plus qu'un graphique supplémentaire vient s'ajouter à l'écran principal de notre projet, affichant la tendance de résultats de tests :
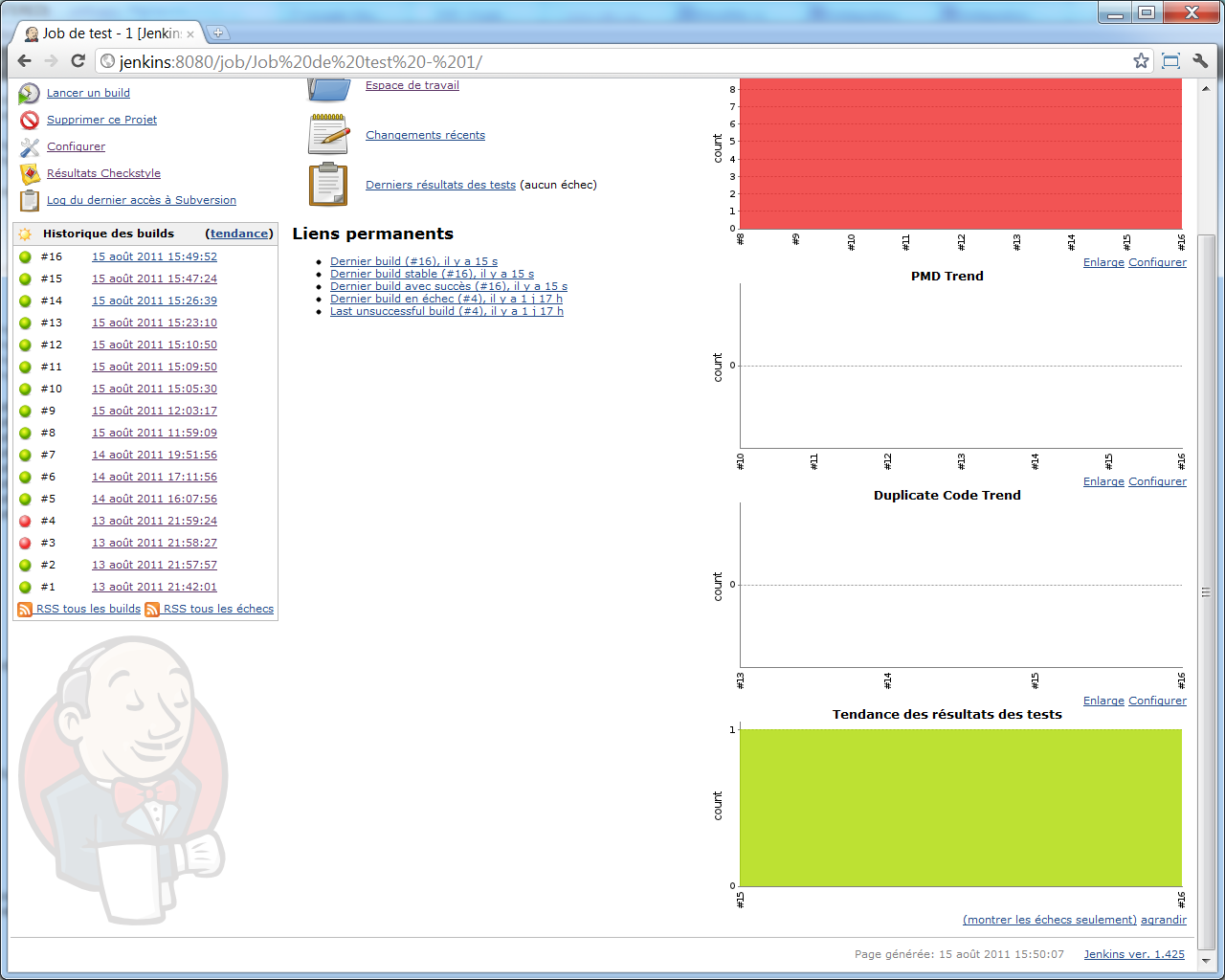
Rapports de Couverture de Code
L'exécution des Tests Unitaires, dont nous venons de publier le rapport, a permis la création des rapports de couverture de code (qui mettent en évidence les lignes de code exécutées lors des tests unitaires -- et donc, le ratio de code testé vs code non testé).
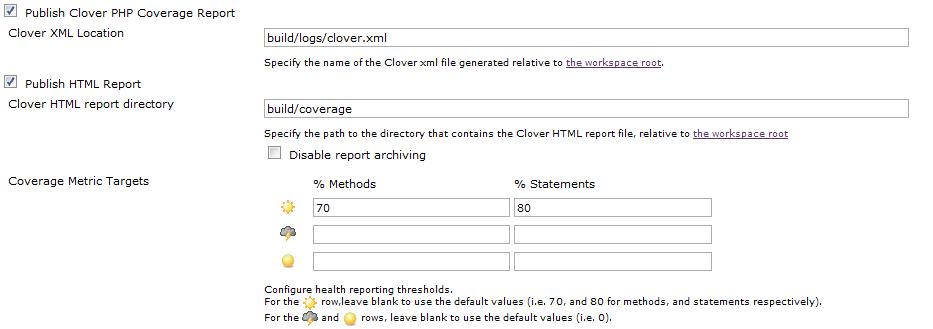
Activons donc la publication de ces rapports ; en tenant compte à la fois du rapport XML (utilisé par Jenkins pour afficher ses statistiques) et du rapport HTML (qui permettra de naviguer dans le code, en visualisant les lignes exécutées ou non) :
Encore une fois, vérifions la sortie console du build que nous lancerons après avoir enregistré notre configuration, pour nous assurer que ce nouveau point est bien pris en compte en fin de build :

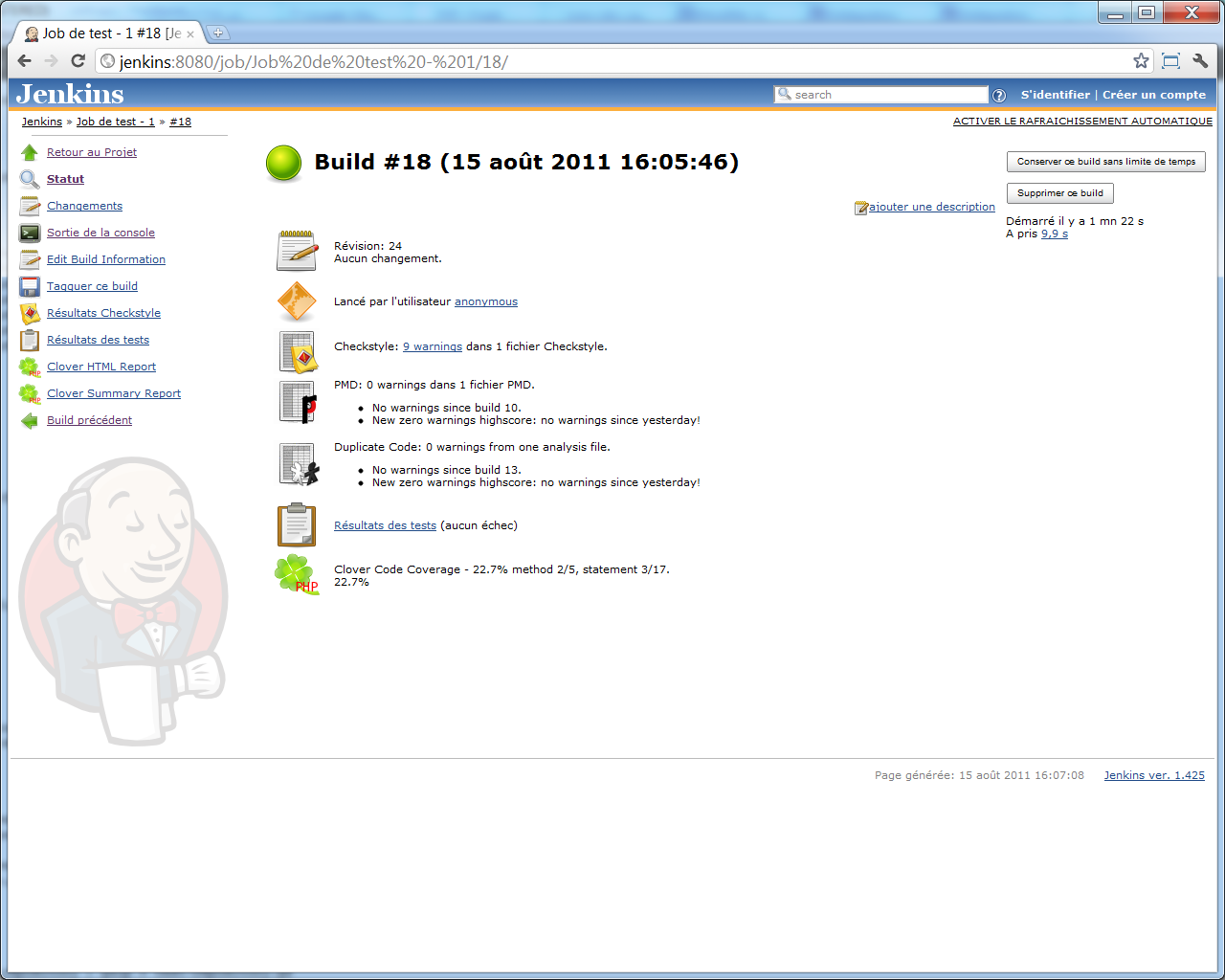
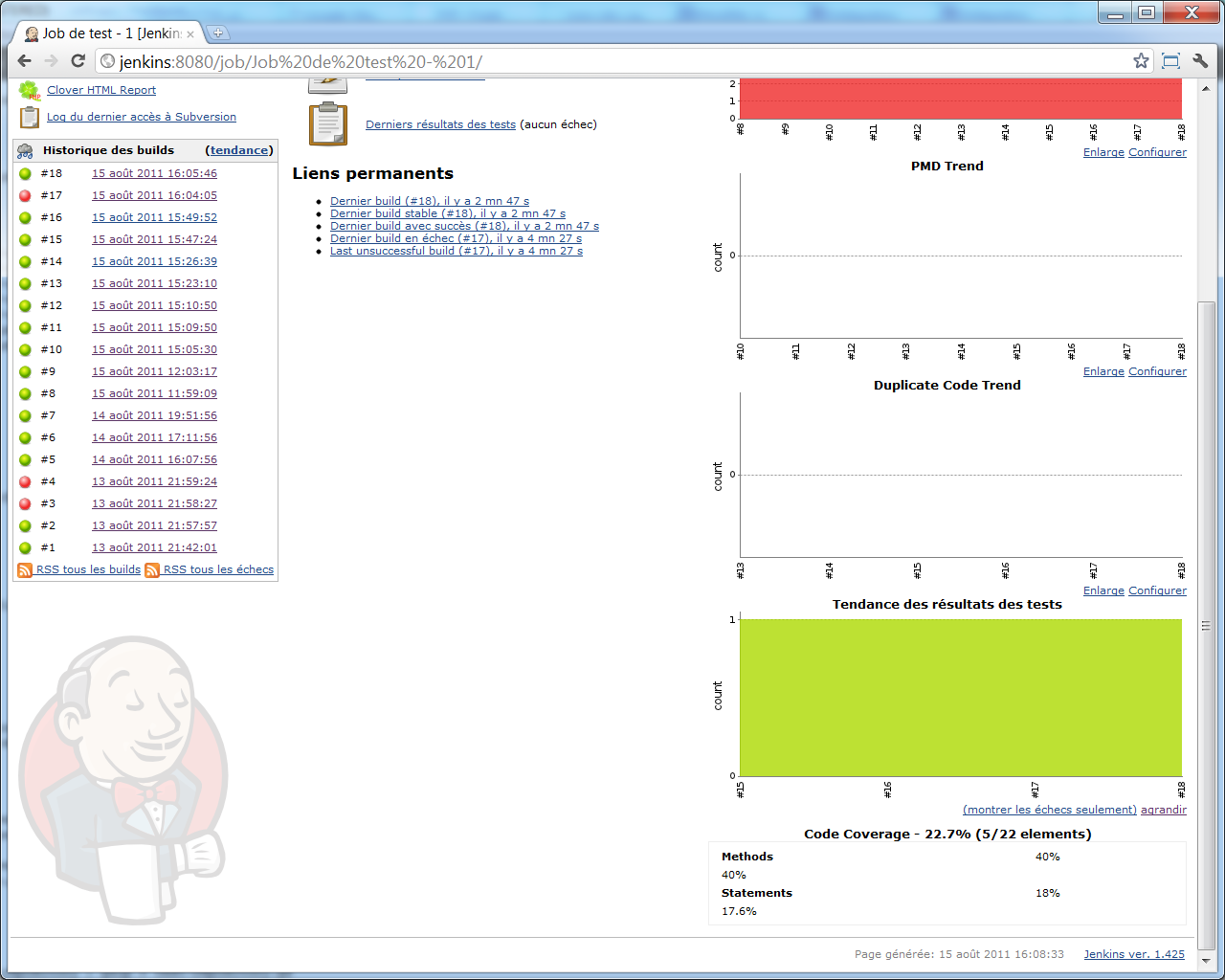
Et sur l'écran de détail du build le plus récent, nous voyons apparaitre une section << Clover Code Coverage >> (bon, 22%, c'est pas terrible ^^) :
En naviguant vers << Clover HTML report >>, via le menu à gauche, nous arrivons sur le rapport HTML généré par PHPUnit, qui permet de naviguer dans le code, en visualisant ce qui a ou non été couvert par nos tests automatisés :
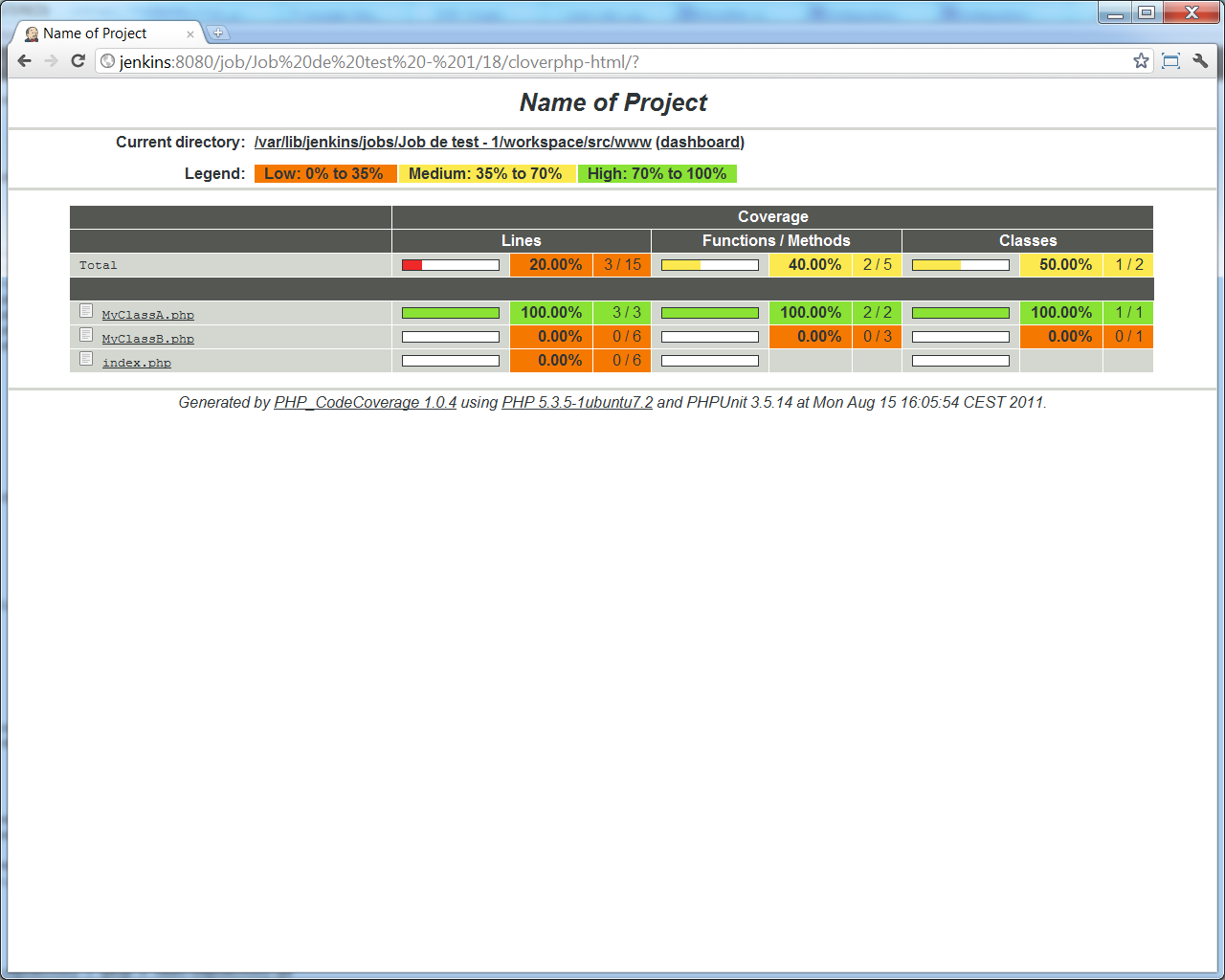
Et en choisissant << Clover Summary report >>, nous avons, présentées de façon un peu plus succinte, quelques statistiques :
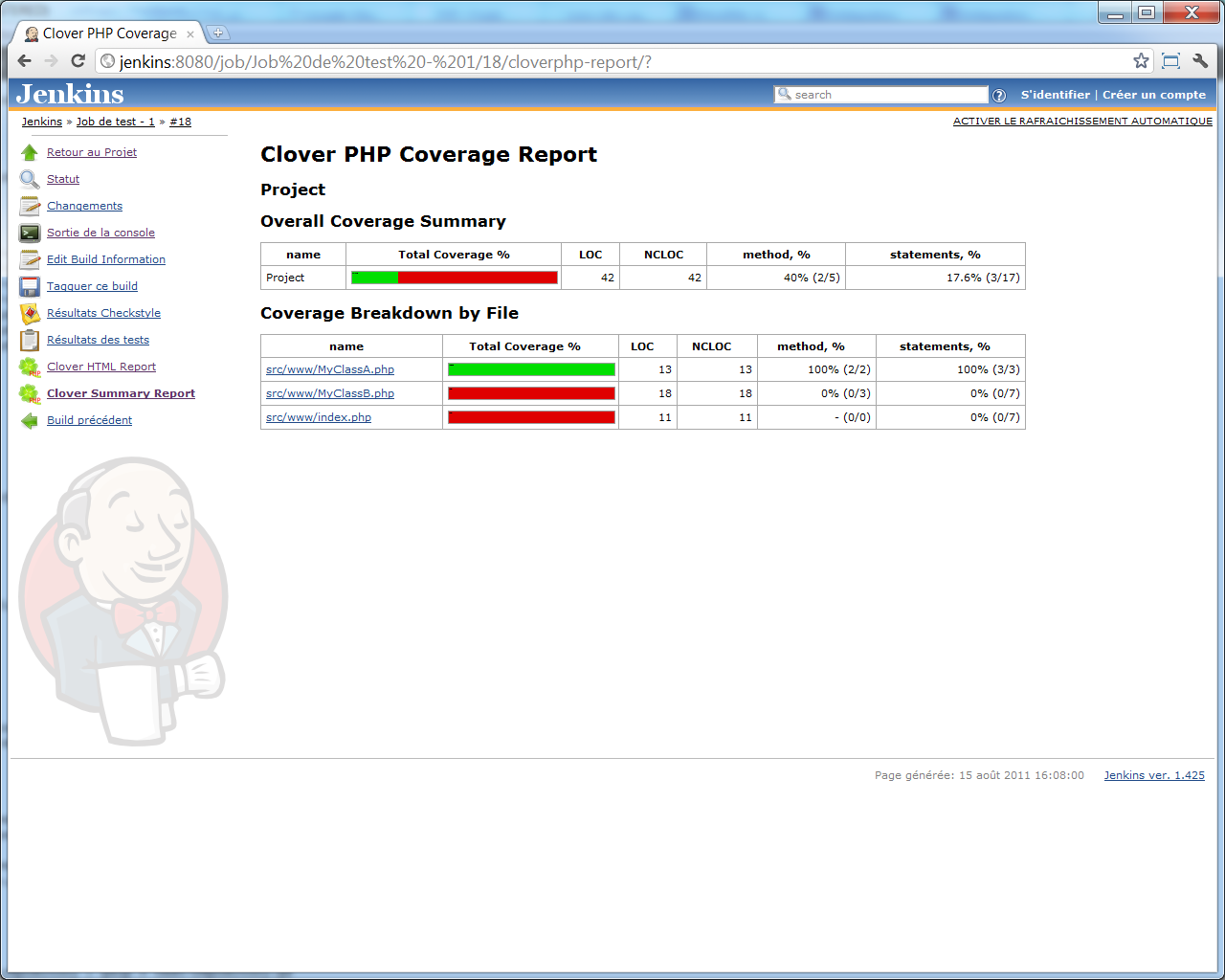
Ces statistiques se retrouvent d'ailleurs aussi sur la page principale de notre projet, pour ceux qui voudraient y avoir accès en un coup d'oeil :
Documentation d'API, et Code Browser
Nous avons intégré à notre processus de build la génération de la documentation d'API (via phpDocumentor, ici) et d'un navigateur de code (via PHP_CodeBrowser).
Ces deux outils générent une série de pages HTML, dont Jenkins ne peut pas extraire d'information spécifique ; nous les publierons donc sous forme de << HTML reports >>, ce qui nous permettra tout de même d'y avoir accès depuis notre plate-forme d'Intégration Continue :
Après avoir ajouté les deux rapports correspondant (les chemins utilisés ici correspondent à ceux que nous avons renseigné dans notre script de construction, build.xml, bien entendu) :

Comme d'habitude, nous vérifions, via la sortie console du build lancé après enregistrement de ces nouveaux paramètres, que ceux-ci ont bien été pris en compte :

Et la page d'accueil de notre job (ainsi que le menu gauche) s'enrichit de deux liens, correspondant aux deux rapports dont nous avons demandé la publication :
- <<
API Documentation>>, - et <<
Code Browser>>
Après avoir cliqué sur le premier lien, nous arrivons à la documentation d'API de notre projet (si j'avais positionné quelques docblocks dans mon code, ça serait un peu plus parlant, certes) :
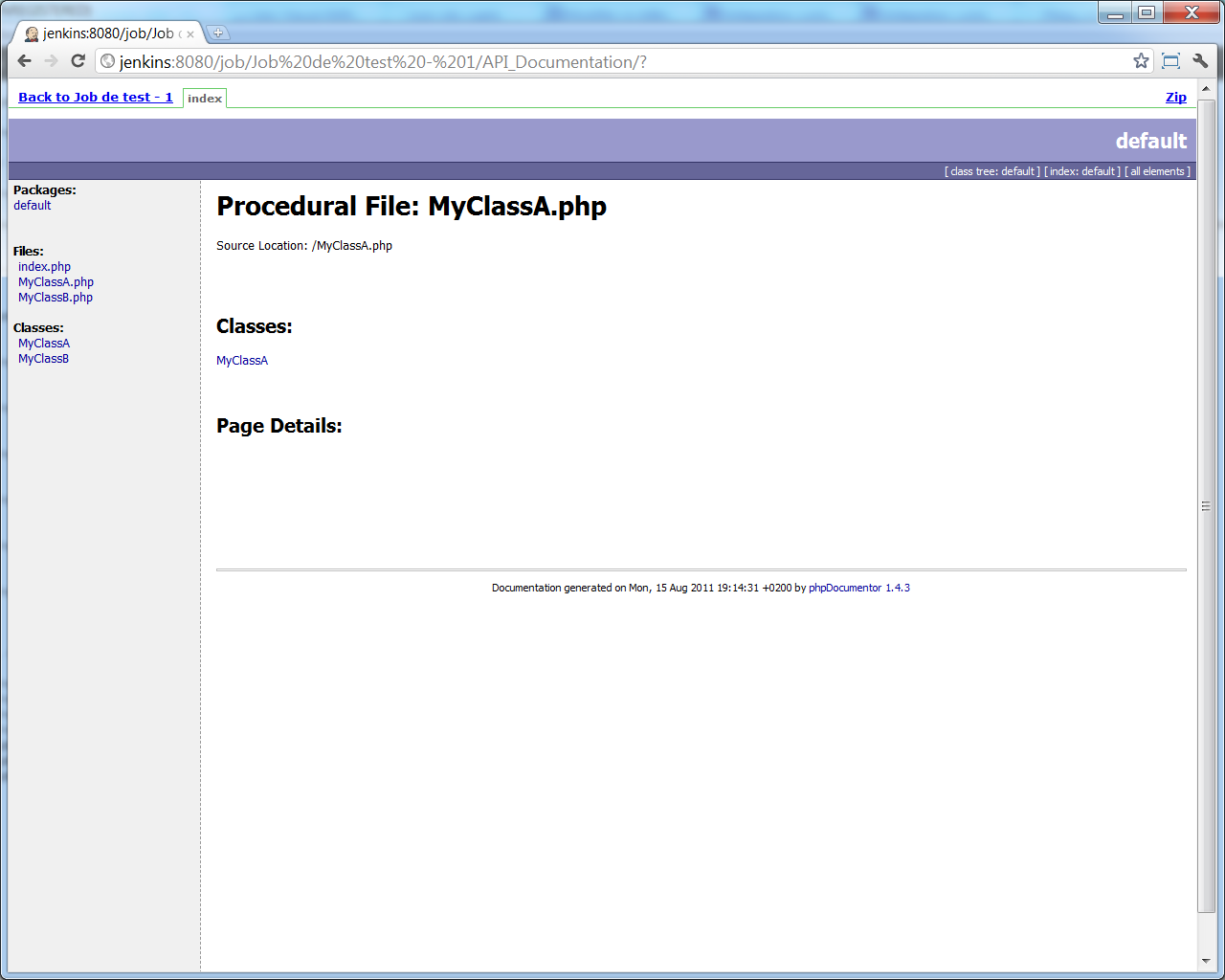
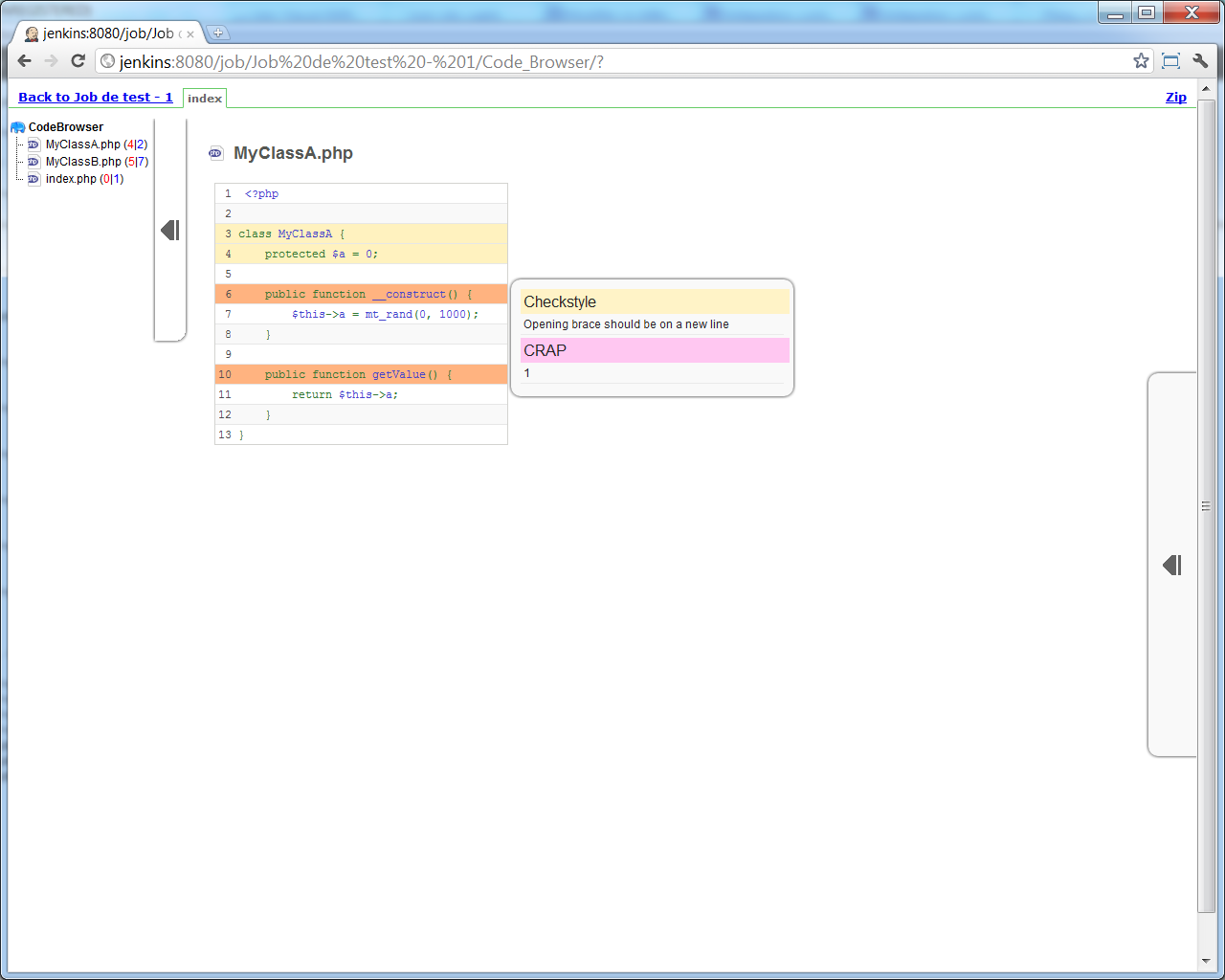
Et le second lien mène à un navigateur de code, qui intégre une partie des résultats d'analyse produits par d'autres outils (ici, en exemple, un extrait de rapport checkstyle généré par PHP_CodeSniffer) :
Rapport PHP Depend
Passons ensuite à la publication du rapport généré par PHP Depend -- qui a fourni un fichier correspondant au format JDepend du monde JAVA, ce qui, encore une fois, est bien arrangeant :

Et, une fois notre paramétrage enregistré, lançons un build et vérifions la sortie console :

Le menu gauche de notre job s'enrichit, encore une fois, d'une entrée supplémentaire : << JDepend >> :
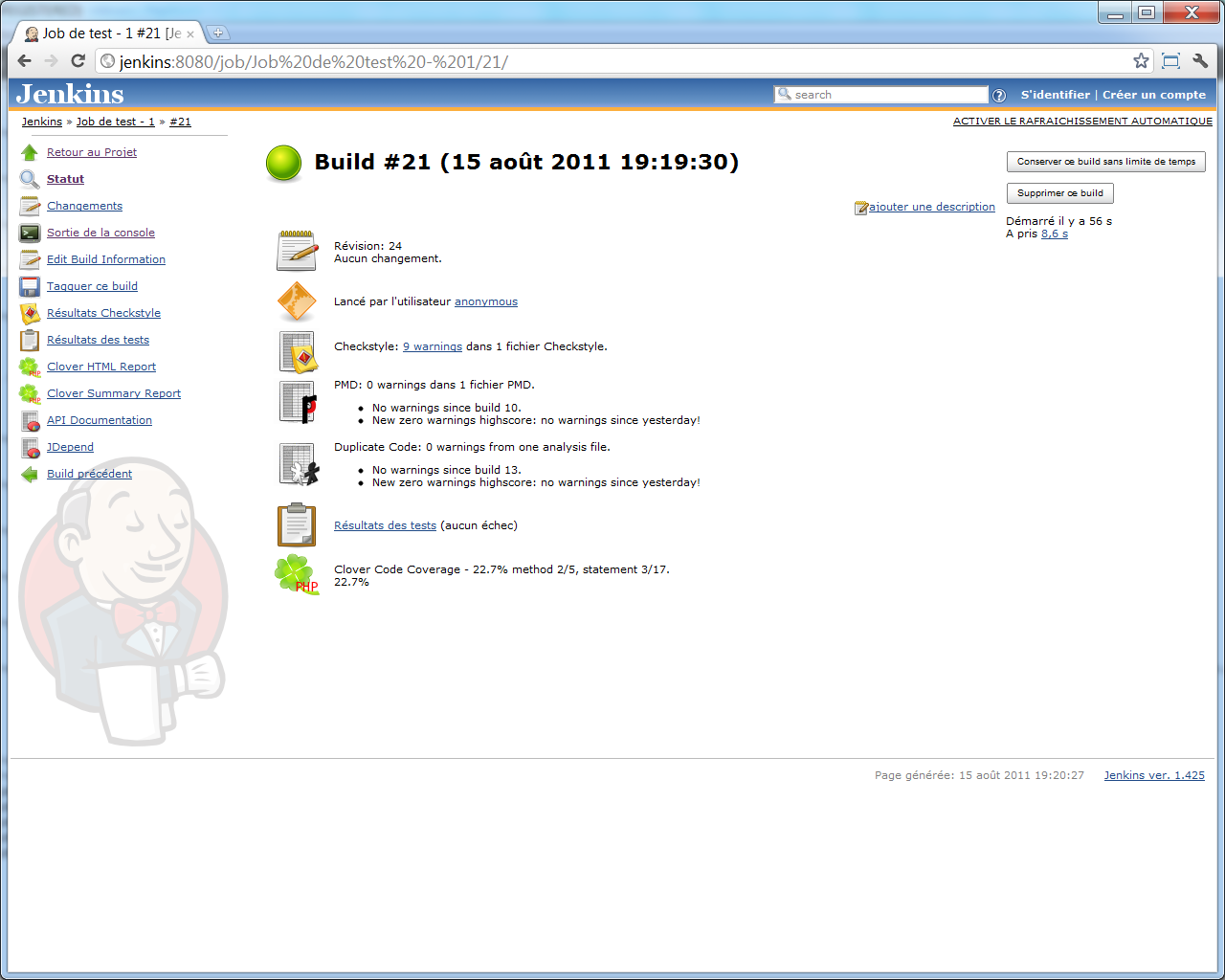
Et voici un aperçu du rapport qui s'affiche si nous cliquons dessus (encore une fois, sur un projet d'exemple aussi petit, le rapport n'est pas aussi intéressant qu'il pourrait l'être sur un projet plus volumineux...) :
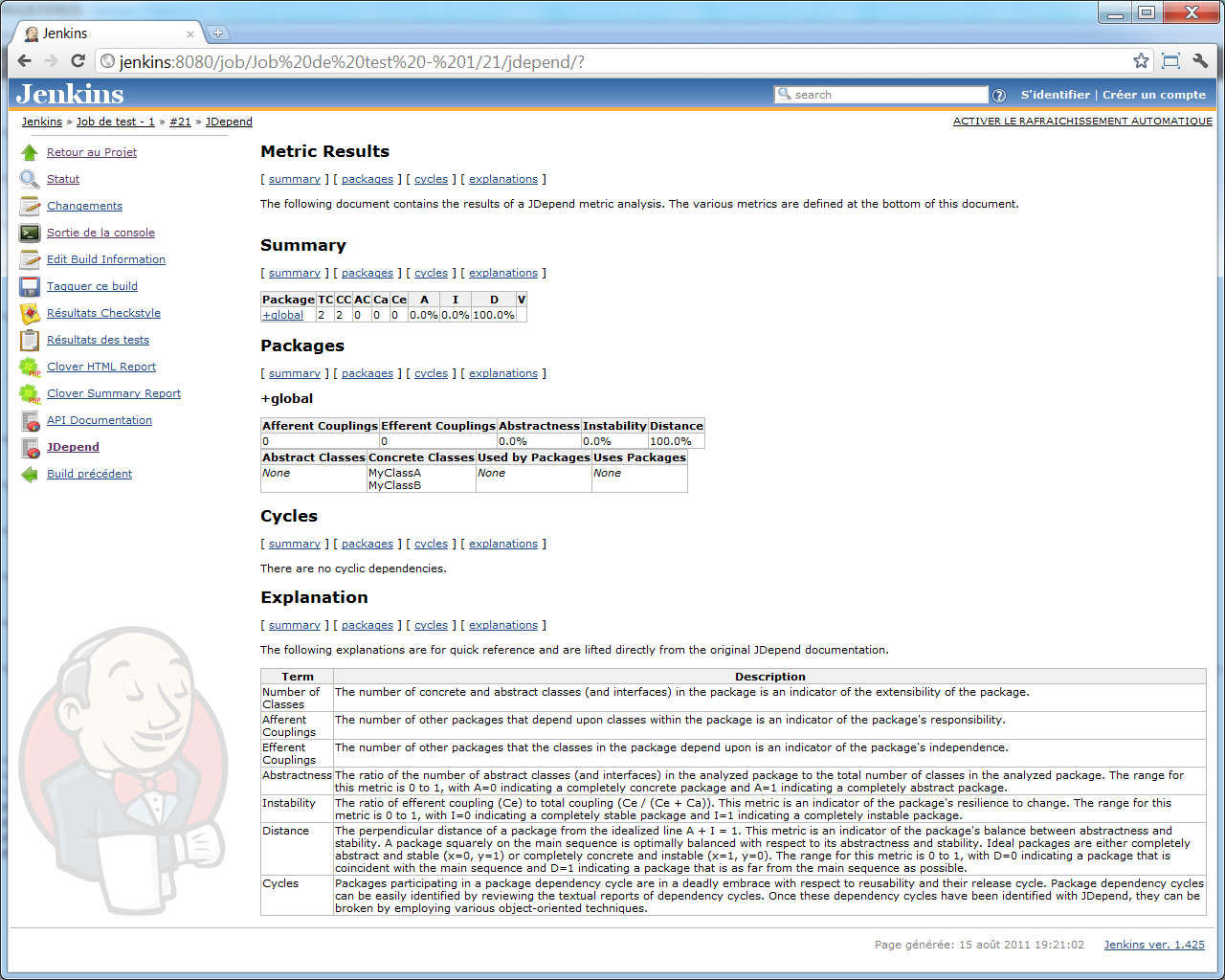
Rapport de violations
Nous pouvons aussi demander à Jenkins de regrouper, sous forme d'un graphe, plusieurs types de rapports.
Typiquement, ici, nous allons regoruper au sein d'un même graphe les informations issues des analyse checkstyle, cpd, et pmd :
Comme d'habitude, jetons un coup d'oeil à la console après avoir lancé un build... Bon, pas bien grand chose d'utile, ce coup-ci :

Par contre, maintenant (éventuellement, au bout de quelques builds, pour avoir des points de comparaison pour pouvoir tracer un graphe), nous avons sur la page d'accueil de chaque build un graphe reprenant les informations que nous avons aggrégées au-dessus :
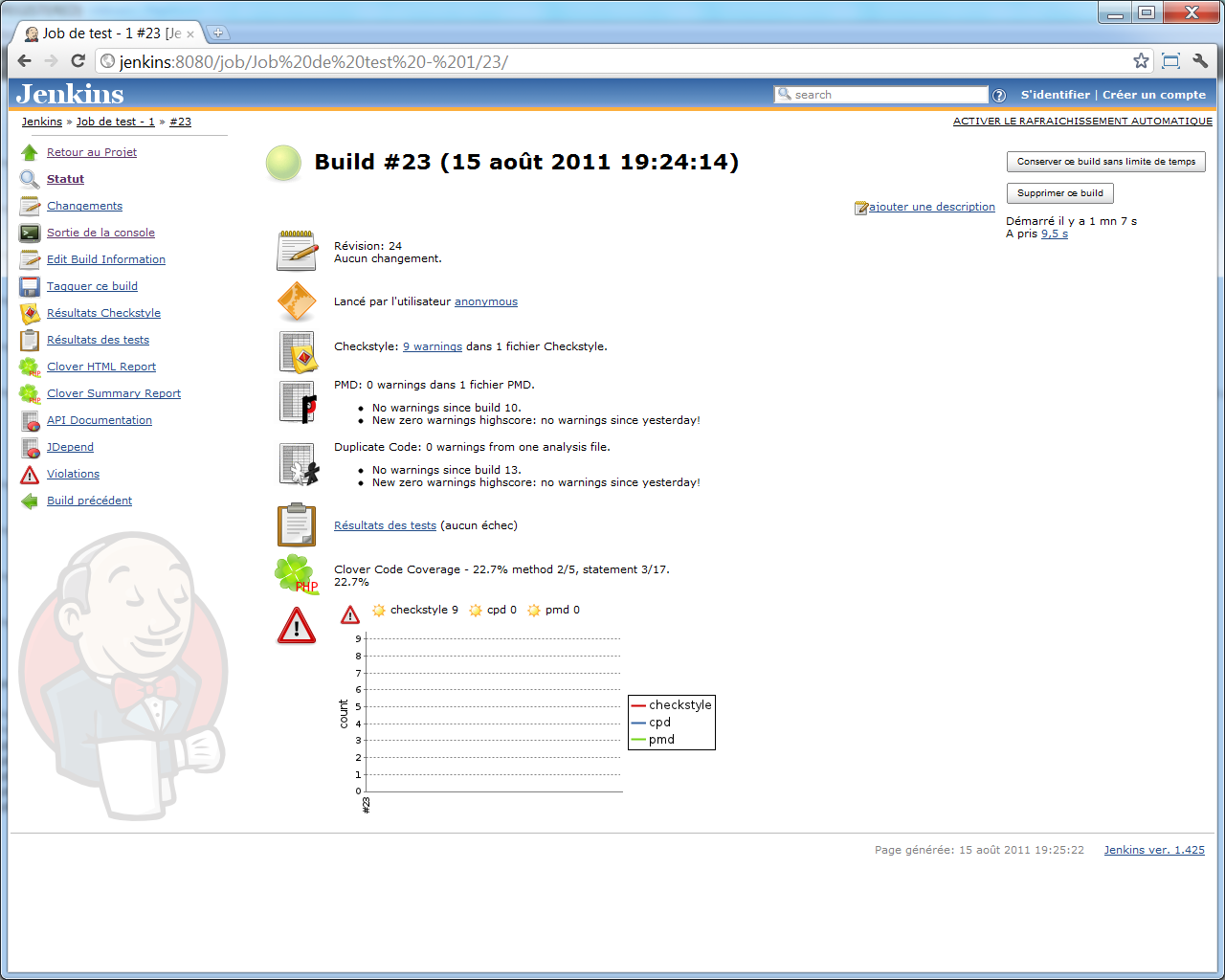
Ce graphique se retrouve aussi sur la page principale de notre job, d'ailleurs.
Et si nous cliquons sur le lien << Violations >> dans le menu gauche, nous arrivons à une page de détails :
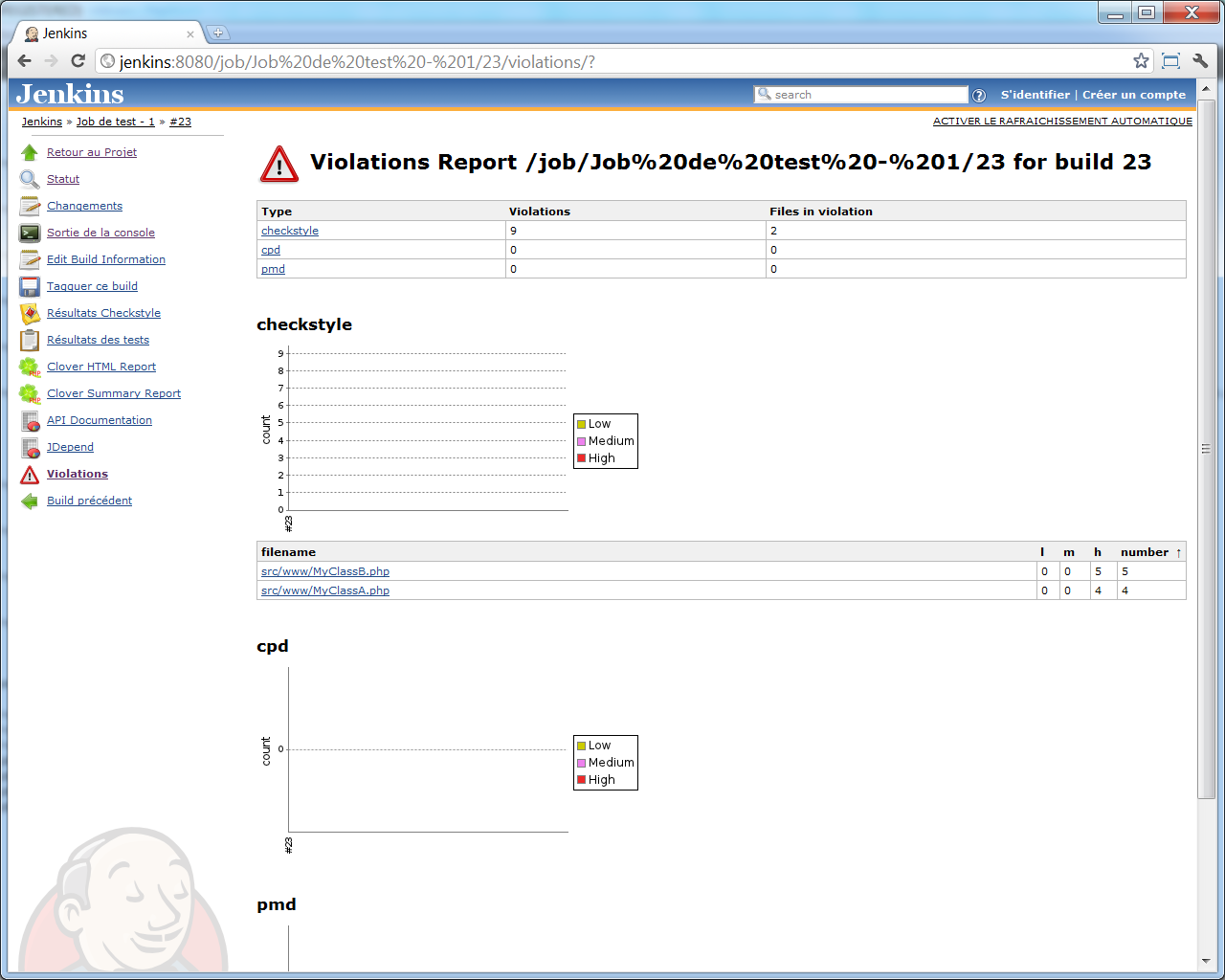
Cette page n'est pas forcément celle qui vous sera la plus utile, mais le graphique sur la page principale du job, par contre, peut vous intéresser, pour détecter tout changement brutal du nombre de problèmes causées par les sources de votre projet (par exemple, cela peut vous permettre de vérifier en un clin d'oeil que l'arrivée d'un nouveau développeur dans l'équipe, ne connaissant pas encore vos normes de codage, ne s'accompagne pas d'une hausse catastrophique de violations de celles-ci).
Lignes de code, nombres de méthodes, classes, ...
Il reste encore un outil d'analyse dont nous n'avons pas exploité les résultats : phploc.
Nous avons demandé à cet outil de nous générer en sortie un fichier CSV, enregistré dans build/logs/phploc.csv :
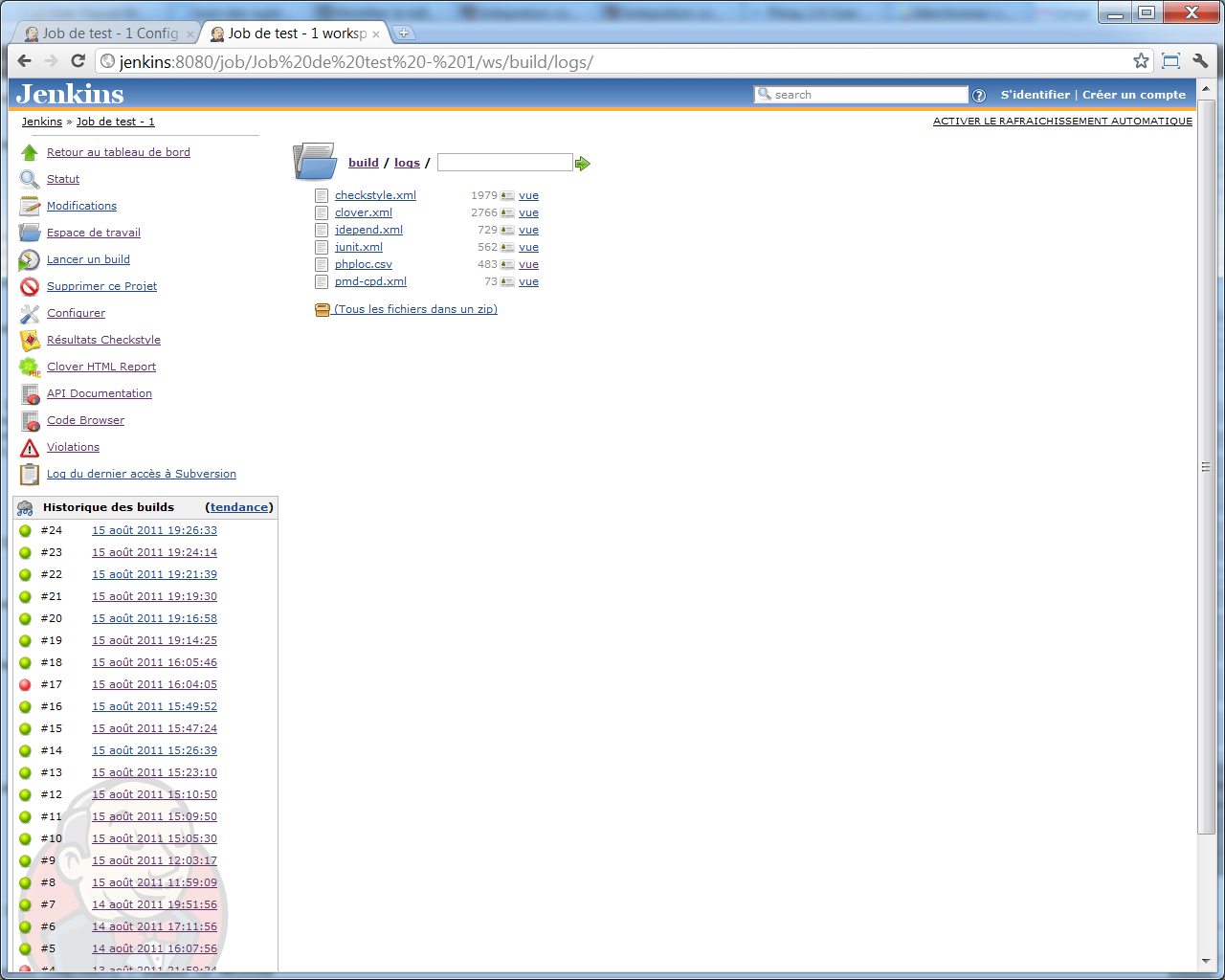
Si nous jetons un coup d'oeil au contenu de ce fichier (toujours sur le même mini-projet de test, qui n'est probablement pas le plus intéressant pour ce genre de chose), nous pouvons voir qu'il contient quelque chose de ce type (j'ai ajouté des retours à la ligne dans la première ligne, pour faciliter la lecture) :
Lines of Code (LOC),Cyclomatic Complexity / Lines of Code,Comment Lines of Code (CLOC),Non-Comment Lines of Code (NCLOC),
Namespaces,Interfaces,Classes,Abstract Classes,
Concrete Classes,Average Class Length (NCLOC),Methods,Non-Static Methods,
Static Methods,Public Methods,Non-Public Methods,Average Method Length (NCLOC),
Cyclomatic Complexity / Number of Methods,Anonymous Functions,Functions,Constants,
Global Constants,Class Constants
42,0,0,42,0,0,2,0,2,12.5,5,5,0,3,2,5,1,0,0,0,0,0
Un fichier CSV tout ce qu'il y a de plus classique, autrement dit, avec en première ligne les titres de colonnes, et en seconde ligne les valeurs.
Tel quel, ce fichier n'est pas des plus intéressant ; et les chiffres qu'il contient ne le sont pas bien plus.
Par contre, avec ce type d'informations, ce qui peut être intéressant, c'est la progression au cours du cycle de vie du projet, d'un build sur l'autre.
Nous allons donc publier ces chiffres sous forme de graphes, reprenant l'historique d'un nombre non négligeable de constructions, permettant de voir en un rapide coup d'oeil quelle est l'évolution de notre projet en termes de nombres de lignes de codes, de nombres de classes, de nombres de méthodes, ...
Les paramètres de configuration que je vais reproduire ici sont ceux proposés par Sebastian Bergmann dans ses Templates PHP pour Jenkins -- ils font plutôt bien l'affaire ; et Sebastian sait de quoi il parle, puisque c'est l'auteur de, entre autre, phploc, l'outil utilisé pour effectuer les analyses dont nous présentons ici les résultats.
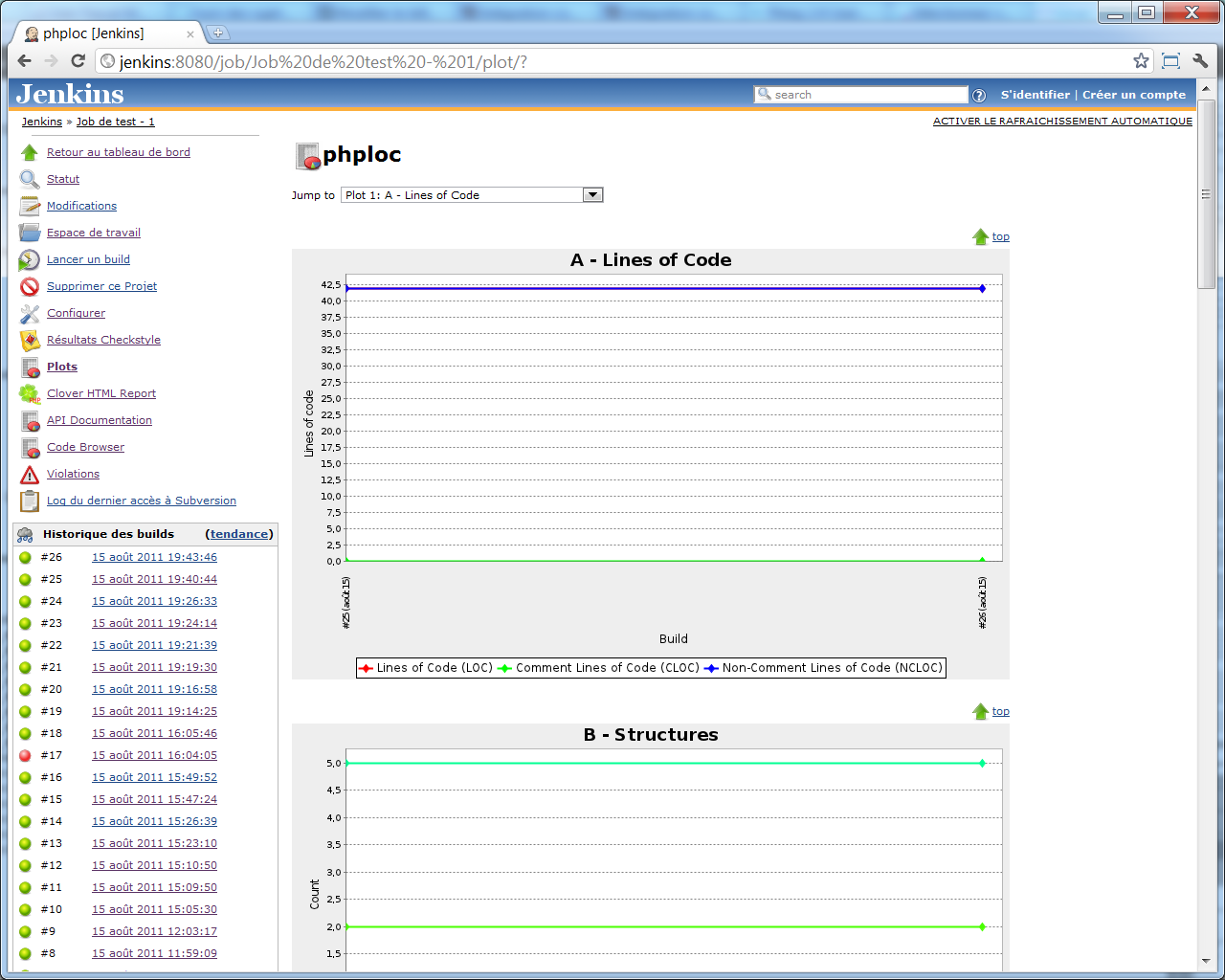
A - Lines of code
Le premier graphe est celui des nombres de lignes de code.
Il prendra en compte les colonnes suivantes du fichier CSV : Lines of Code (LOC),Comment Lines of Code (CLOC),Non-Comment Lines of Code (NCLOC)
La configuration correspondante dans Jenkins pourrait donc ressembler à ceci :
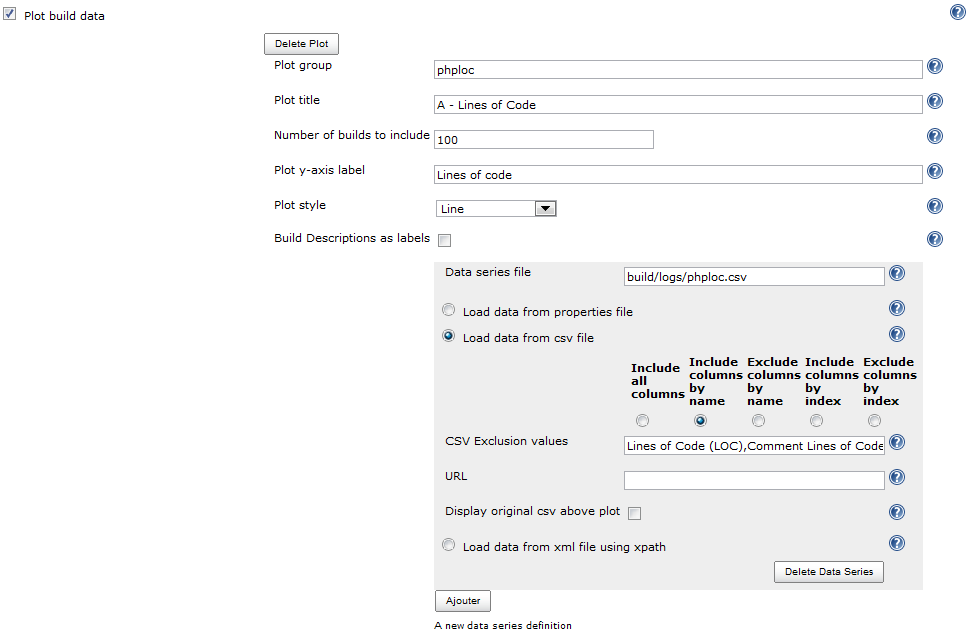
Libre à vous de personnaliser le titre et le libellé sur l'axe Y ; par contre, veillez à bien cocher la radio << Include columns by name >>, et à saisir en-dessous les noms des colonnes à utiliser -- cette remarque est vraie pour tous les graphes que nous construirons à partir du rapport généré par phploc.
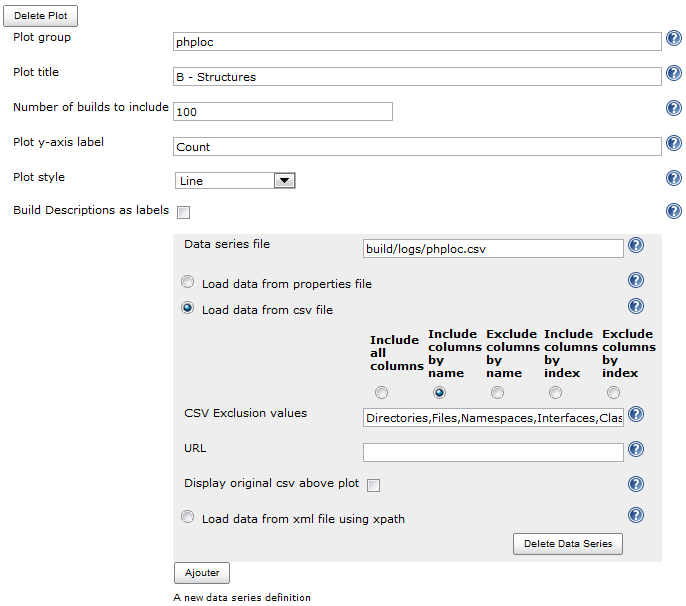
B - Structures
Passons ensuite au graphe affichant les nombres de structures de chaque type, qui prendra en compte les colonnes suivantes du fichier CSV : Directories,Files,Namespaces,Interfaces,Classes,Methods,Functions,Anonymous Functions,Constants
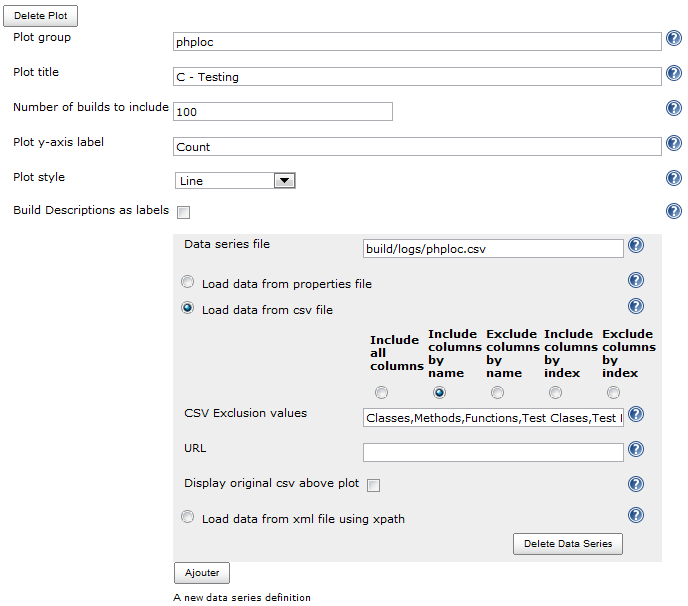
C - Testing
Au tour du graphique présentant les classes et méthodes de tests automatisés, qui tracera les courbes correspondant aux colonnes suivantes : Classes,Methods,Functions,Test Clases,Test Methods
D - Types of Classes
Viennent ensuite les nombres de classes de chaque type, avec les colonnes suivantes : Classes,Abstract Classes,Concrete Classes
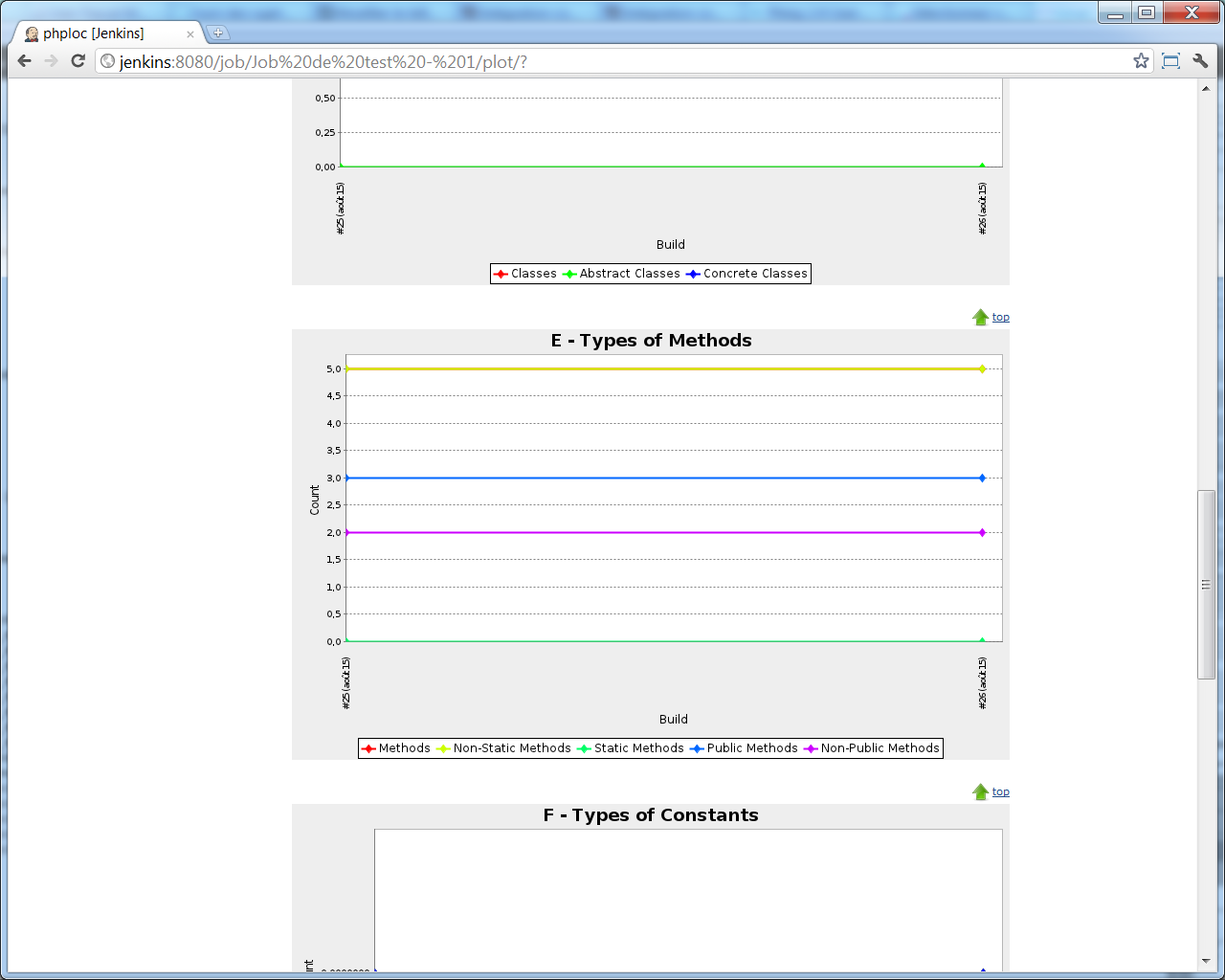
E - Types of Methods
Puis les différents types de méthodes : Methods,Non-Static Methods,Static Methods,Public Methods,Non-Public Methods
F - Types of Constants
On passe ensuite aux différents types de constantes : Constants,Global Constants,Class Constants
G - Average Length
Pour enchainer avec les longueurs moyennes de classes et de méthodes (on se rappelle au passage que les méthodes et classes trop longues, c'est pas top ;-) ) : Average Class Length (NCLOC),Average Method Length (NCLOC)
H - Relative Cyclomatic Complexity
Et nous terminons avec la Complexité Cyclomatique, tirant profit des colonnes suivantes : Cyclomatic Complexity / Lines of Code,Cyclomatic Complexity / Number of Methods
Et les résultats ?
Une seconde fois, rien de bien intéressant dans la sortie console de notre buid :

Par contre, une entrée << Plots >> est venue s'ajouter au menu gauche de notre job ; et cliquer dessus mène à une page présentant les différents graphes que nous venons de configurer.
Par exemple, pour le nombre de lignes de code :
Ou pour les différents types de méthodes :
(Bon, OK, ça devient plus intéressant lorsque vous bossez sur un vrai projet bien vivant -- à vous de jouer, pour ça ;-) )
Et maintenant ?
Voyons voir... vous savez installer Jenkins et ses plugins, et nous avons vu ici comment le configurer pour placer un projet PHP en intégration continue, construire ce projet avec Phing, et publier les résultats d'analyse... C'est plutôt un bon début ;-)
Maintenant, la balle est dans votre camp : c'est ce que vous ferez de cette plate-forme d'Intégration Continue, la façon dont vous travaillerez avec, qui déterminera son utilité réelle pour votre projet.
Si je puis tout de même me permettre quelques conseils :
- Plus les outils d'analyse de qualité arrivent tôt (s'ils sont en place avant même que les développement ne commencent, c'est encore mieux), plus il sera facile de former vos équipes, de les sensibiliser à l'importance de la qualité, et de tenir compte de ces retours -- si vous mettez en place PHP_CodeSniffer sur un projet en cours de développement depuis des mois, où chacun a codé à sa façon, vous aurez des milliers d'erreurs... et personne n'aura jamais le courage de les corriger ; donc les résultats de cette analyse seront tout simplement ignorés ; et hop, une partie de votre plate-forme qui ne servira à rien !
- La plate-forme d'intégration continue ne doit pas être vue comme un ennemi : un test qui échoue, ce n'est pas la fin du monde, ce n'est pas PHPUnit qui est méchant ; au contraire : c'est un problème potentiel identifié rapidement, avant livraison de l'application en production, avant de ne devenir un problème réel ; c'est donc une aide qui est apportée à toute l'équipe[5].
- L'Intégration Continue, tout comme le code de l'application, ce n'est pas réservé à une ou deux personnes : c'est toute l'équipe du projet qui est concernée ; et doit donc être formée à son utilité, et à son utilisation.
Et, sur un plan plus technique :
- Si vous utilisez un Framework (Zend Framework, symfony, ...), ou construisez autour d'un logiciel existant (Drupal, Magento, ...) : ne perdez pas de temps à jouer les tests de ces outils, ni à construire leur documentation d'API -- de toute façon, vous n'y arriverez probablement pas (votre build durerait une éternité ; pour rien ou presque, finalement) ; au contraire, excluez les répertoires concernés.
- Au fur et à mesure que votre projet va grossir, votre plate-forme d'Intégration Continue va avoir besoin de plus de ressources machine (CPU, RAM, disque, ...) -- évitez donc de la déployer sur un petit serveur dans un coin, déjà utilisé pour 36 autres trucs ;-)
Quelques liens et sources d'inspiration :
- Documentation de Phing[6] : elle vous sera utile, lorsque vous aurez besoin de rendre votre
build.xmlplus spécifique, ou de développer des tâches personnalisées (ce qui, dans le cadre de l'IC, ne m'est pas arrivé bien souvent ; mais phing, comme outil d'automatisation, peut être utilisé dans d'autres contextes ;-) ) - Template for Jenkins Jobs for PHP Projects : comment mettre un projet en Intégration Continue sous Jenkins -- en utilisant Ant, et pas Phing ; si vous n'avez pas envie de faire toute la création du script de build et toute la configuration du job Jenkins << à la main >>, ces templates sont fait pour vous ;-)
- Integrate Your PHP Project with Jenkins : une série de slides (en anglais) de Sebastian Bergmann sur le sujet,
- et Intégration continue des projets PHP avec Jenkins : une série de slides de Hugo Hamon ; en français, ceux-ci -- jetez-y un coup d'oeil !
Notes
[1] Et rien que cette extensibilité en PHP, c'est une énorme force pour Phing, dans le cadre de projets PHP où les équipes de développement ne savent pas forcément coder en JAVA -- en encore moins débugger un programme JAVA qui planterait.
[2] Si votre projet est sous SVN et que vous bossez sur plusieurs demandes en même temps, sans utiliser de branche, vous voyez probablement de quoi je parle...
[3] Un autre avantage de Phing, outil du monde PHP ;-)
[4] Libre à vous de coder la tâche correspondante, et de soumettre un patch ;-)
[5] Je ne sais pas vous, mais moi, je suis bien content quand j'arrive au bureau et que, avant de livrer une évolution en production, j'ai un mail qui me dit << build failed >> ; c'est quand même plus agréable que le coup de fil du client deux heures après, ralant parce que ça fait deux heures que les utilisateurs ne peuvent plus passer de commande sur sa boutique et qu'il a perdu X milliers d'euro sur la matinée... surtout si vous lui avez déjà fait le coup trois semaines avant...
[6] Oui, la documentation de Phing, en son état actuel, est mal foutue -- j'ai espoir que ça change dans le futur


